Forward and Backward Propagation
The basic blocks of implementing a deep neural network are A forward propagation step for each layer, and a corresponding backward propagation step.
Let's see how you can actually implement these steps. We'll start with forward propagation.
Recall that what this will do is input \( a^{[l-1]} \) and output \( a^{[l]} \), and the cache \( z^{[l]} \). And we just said that an implementational point of view, maybe where cache \( w^{[l]} \) and \( b^{[l]} \) as well.
The way to implement a forward function is just this equals \( w^{[l]} * a^{[l-1]} + b^{[l]} \), and then, \( a^{[l]} = g(z^{[l]}) \). Where g() is the activation function.
Next, let's talk about the backward propagation step.
Here, your goal is to input \( da^{[l]} \), and output \( da^{[l-1]} \) and \( dW^{[l]} \) and \( db^{[l]} \).
Let me just right out the steps you need to compute these things: \( dz^{[l]} = da^{[l]} * {g^{[l]}}^{'} * (z^{[l]}) \). Here \( {g^{[l]}}^{'} \) is the derivative of the activation function.
Then, to compute the derivatives \( dW^{[l]} = dz^{[l]} * a^{[l - 1]} \).
\( db^{[l]} = dz^{[l]} \)
\( da^{[l-1]} = {W^{[l]}}^{T} dz^{[l]} \)
Parameters vs Hyperparameters
Being effective in developing your deep neural Nets requires that you not only organize your parameters well but also your hyper parameters so what are hyper parameters
The parameters of your model are W and B but there are other things you need to tell your learning algorithm such as the learning rate \( \alpha \), the number of iterations of gradient descent you carry out your learning algorithm, the number of hidden layers L or the number of hidden units and finally the choice of activation function
So all of these things are things that you need to tell your learning algorithm and so these are parameters that control the ultimate parameters W and B and so we call all of these things hyper parameters because it is the hyper parameters that you know somehow determine the final value of the parameters W and B
So when you're training a deep net for your own application you find that there may be a lot of possible settings for the hyper parameters that you need to just try out so apply deep learning
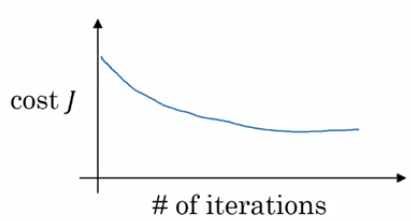
For example if you're not sure what's the best value for the learning rate you might try one value of the learning rate alpha and see their cost function J go down like shown below
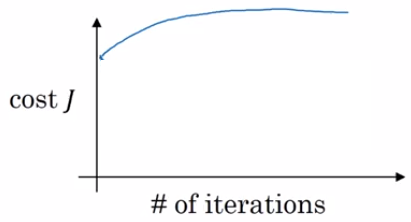
Then you might try a larger value for the learning rate alpha and see the cost function blow up and diverge then as given in the below figure.
It is very difficult to know in advance exactly what's the best value of the hyper parameters so what often happen is you just have to try out many different values and go around a cycle where you try some values and evaluate your output. Then decide how to proceed.