Basic Recipe for Machine Learning
In the previous section, you saw how looking at training error and depth error can help you diagnose whether your algorithm has a bias or a variance problem, or maybe both.
It turns out that this information that lets you much more systematically go about improving your algorithms' performance.
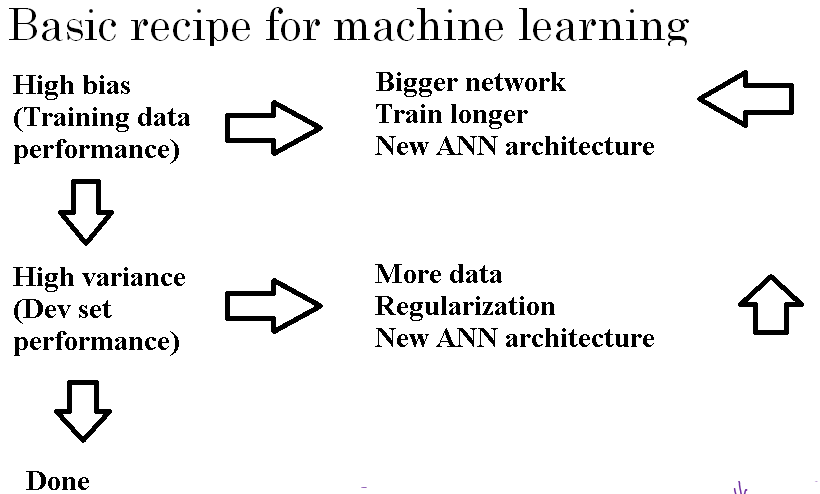
When training a neural network, here's a basic recipe we will use. After having trained an initial model, we will first ask, does your algorithm have high bias?
And so to try and evaluate if there is high bias, you should look at the training set or the training data performance.
And so, if it does have high bias, does not even fit in the training set that well, some things you could try would be to try pick a network, such as more hidden layers or more hidden units, or you could train it longer.
Maybe run trains longer or try some more advanced optimization algorithms, which we'll see about later in this course.
Or you can also try, a different neural network architecture and maybe you can find a new network architecture that's better suited for this problem.
Maybe you can make it work, maybe not.
Whereas getting a bigger network almost always helps.
And training longer doesn't always help, but it certainly never hurts.
So when training a learning algorithm, we would try these things until we can at least get rid of the bias problems, as in go back after we've tried this and keep doing that until we can fit, at least, the training set pretty well.
And usually if you have a big enough network, you should usually be able to fit the training data well so long as it's a problem that is possible for someone to do
If the image is very blurry, it may be impossible to fit it. But if at least a human can do well on the task, if you think bayes error is not too high, then by training a big enough network you should be able to do well, at least on the training set.
To at least fit or overfit the training set. Once you reduce bias to acceptable amounts then ask, do you have a variance problem?
And so to evaluate that we would look at dev set performance i.e Are you able to generalize from a pretty good training set performance to having a pretty good dev set performance?
And if you have high variance best way to solve a high variance problem is to get more data.
If you can get it then it can only help. But sometimes you can't get more data.
Then you could try regularization, which we'll see in the next section, to try to reduce overfitting.
But if you can find a more appropriate neural network architecture, sometimes that can reduce your variance problem as well as reduce your bias problem.
So depending on whether you have high bias or high variance, the set of things you should try could be quite different.
We'll usually use the training set to try to diagnose if you have a bias or variance problem, and then use that to select the appropriate subset of things to try.
So for example, if you actually have a high bias problem, getting more training data is actually not going to help.
Or at least it's not the most efficient thing to do.
So being clear on how much of a bias problem or variance problem or both can help you focus on selecting the most useful things to try.
Bias variance tradeoff
Second, in the earlier era of machine learning, there used to be a lot of discussion on what is called the bias variance tradeoff.
And the reason for that was that, for a lot of the things you could try, you could increase bias and reduce variance, or reduce bias and increase variance.
But back in the pre-deep learning era, we didn't have as many tools that just reduce bias or that just reduce variance without hurting the other one.
But in the modern deep learning, big data era, so long as you can keep training a bigger network, and so long as you can keep getting more data, which isn't always the case for either of these, but if that's the case, then getting a bigger network almost always just reduces your bias without necessarily hurting your variance, so long as you regularize appropriately.
And getting more data pretty much always reduces your variance and doesn't hurt your bias much.
So what's really happened is that, with these two steps, the ability to train, pick a network, or get more data, we now have tools to drive down bias and just drive down bias, or drive down variance and just drive down variance, without really hurting the other thing that much.
And this has been one of the big reasons that deep learning has been so useful for supervised learning, that there's much less of this tradeoff where you have to carefully balance bias and variance, but sometimes you just have more options for reducing bias or reducing variance without necessarily increasing the other one.
And, in fact, if you have a well regularized network. We'll see regularization starting from the next section.
Training a bigger network almost never hurts. And the main cost of training a neural network that's too big is just computational time, so long as you're regularizing.
So this gives you a sense of the basic structure of how to organize your machine learning problem to diagnose bias and variance, and then try to select the right operation for you to make progress on your problem.
One of the things we mentioned several times in the section is regularization, is a very useful technique for reducing variance.
There is a little bit of a bias variance tradeoff when you use regularization. It might increase the bias a little bit, although often not too much if you have a huge enough network.
But let's dive into more details in the next section so you can better understand how to apply regularization to your neural network.