Understanding Dropout
Drop out does this seemingly crazy thing of randomly knocking out units on your network. Why does it work so well with a regularizer?
Let's gain some better intuition. In the previous section, we gave this intuition that drop-out randomly knocks out units in your network.
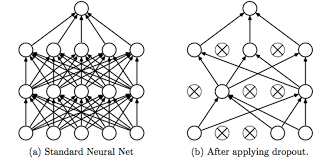
So it's as if on every iteration you're working with a smaller neural network, and so using a smaller neural network seems like it should have a regularizing effect.
Here's a second intuition which is, let's look at it from the perspective of a single unit.
Let's take example of a single unit. Now, for this unit (shown below) to do his job as for inputs and it needs to generate some meaningful output.
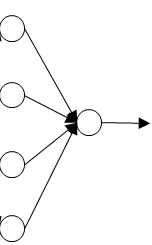
Now with drop out, the inputs can get randomly eliminated. Sometimes two units will get eliminated, sometimes a different unit will get eliminated. This is shown below.
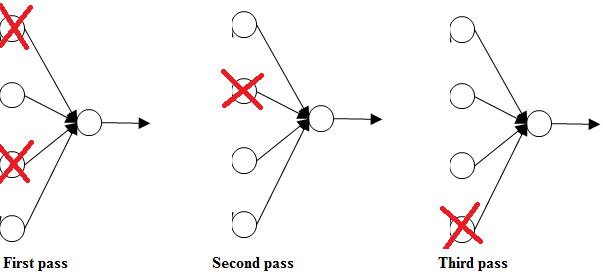
This means that a unit can't rely on any one feature (input neuron) because any one feature could go away at random or any one of its own inputs could go away at random.
So during training high weights might not be given to a single input neuron.
So this unit will be more motivated to spread out this way and give you a little bit of weight to each of the four inputs to this unit.
And by spreading all the weights, this will tend to have an effect of shrinking the squared norm of the weights.
And so, similar to what we saw with L2 regularization, the effect of implementing drop out is that it shrinks the weights and does some of those outer regularization that helps prevent over-fitting.
But it turns out that drop out can formally be shown to be an adaptive form without a regularization. But L2 penalty on different weights are different, depending on the size of the activations being multiplied that way.
But to summarize, it is possible to show that drop out has a similar effect to L2 regularization.
Only to L2 regularization applied to different ways can be a little bit different and even more adaptive to the scale of different inputs.