Other regularization methods
In addition to L2 regularization and drop out regularization there are few other techniques to reducing over fitting in your neural network.
Let's take a look. Let's say you fitting a CAT crossfire. If you are over fitting getting more training data can help, but getting more training data can be expensive and sometimes you just can't get more data.
But what you can do is augment your training set by taking image like the one shown on the left below.

And for example, flipping it horizontally and adding that also with your training set. So now instead of just this one example in your training set, you can add this to your training example.
So by flipping the images horizontally, you could double the size of your training set. Because you're training set is now a bit redundant this isn't as good as if you had collected an additional set of brand new independent examples.
But you could do this Without needing to pay the expense of going out to take more pictures of cats. And then other than flipping horizontally, you can also take random crops of the image.
So for the second image on the right shown above we're rotated and sort of randomly zoom into the image and this still looks like a cat.
So by taking random distortions and translations of the image you could augment your data set and make additional fake training examples.
Again, these extra fake training examples they don't add as much information as they were to call they get a brand new independent example of a cat. But because you can do this, almost for free, other than for some confrontational costs.
This can be an inexpensive way to give your algorithm more data and therefore sort of regularize it and reduce over fitting. And by synthesizing examples like this what you're really telling your algorithm is that If something is a cat then flipping it horizontally is still a cat.
Notice I didn't flip it vertically, because maybe we don't want upside down cats, right? And then also maybe randomly zooming in to part of the image it's probably still a cat.
For optical character recognition you can also bring your data set by taking digits and imposing random rotations and distortions to it. So If you add these things to your training set, these are also still digits.
For illustration I applied a very strong distortion. So this look very wavy for, in practice you don't need to distort the four quite as aggressively, but just a more subtle distortion than what I'm showing here, to make this example clearer for you, right?

But a more subtle distortion is usually used in practice, because this looks like really warped fours. So data augmentation can be used as a regularization technique, in fact similar to regularization.
Early stopping
So what you're going to do is as you run gradient descent you're going to plot your the training error on the training set.
Or just plot the cost function J optimizing, and that should decrease monotonically.
Because as you train, hopefully, your cost function J should decrease. So with early stopping, what you do is you plot this, and you also plot your dev set error as shown below.
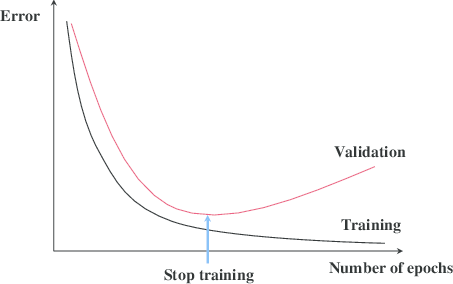
Now what you find is that your dev set error will usually go down for a while, and then it will increase from there.
So what early stopping does is, you will say well, it looks like your neural network was doing best around that iteration, so we just want to stop trading on your neural network halfway and take whatever value achieved this dev set error.
So why does this work? Well when you've haven't run many iterations for your neural network yet your parameters w will be close to zero.
Because with random initialization you probably initialize w to small random values so before you train for a long time, w is still quite small.
And as you iterate, as you train, w will get bigger and bigger and bigger until here maybe you have a much larger value of the parameters w for your neural network.
So what early stopping does is by stopping halfway you have only a mid-size rate w.
And so similar to L2 regularization by picking a neural network with smaller norm for your parameters w, hopefully your neural network is over fitting less.
And the term early stopping refers to the fact that you're just stopping the training of your neural network earlier.