Introduction to Machine Learning
What is machine learning? You probably use it dozens of times a day without even knowing it.
Each time you do a web search on Google or Bing, that works so well because their machine learning software has figured out how to rank what pages.
When Facebook or Apple's photo application recognizes your friends in your pictures, that's also machine learning.
Each time you read your email and a spam filter saves you from having to wade through tons of spam, again, that's because your computer has learned to distinguish spam from non-spam email. So, that's machine learning.
There's a science of getting computers to learn without being explicitly programmed.
Building truly intelligent machines, we can do just about anything that you or I can do.
Many scientists think the best way to make progress on this is through learning algorithms called neural networks, which mimic how the human brain works, and I'll teach you about that, too.
In this course, you learn about machine learning and get to implement them yourself.
What is machine learning?
Arthur Samuel - He defined machine learning as the field of study that gives computers the ability to learn without being explicitly learned.
And eventually learn to play checkers better than the Arthur Samuel himself was able to. This was a remarkable result. Arthur Samuel himself turns out not to be a very good checkers player. But because a computer has the patience to play tens of thousands of games against itself, no human has the patience to play that many games. By doing this, a computer was able to get so much checkers playing experience that it eventually became a better checkers player than Arthur himself.
Tom Mitchell - A well-posed learning problem is defined as follows : a computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Let's say your email program watches which emails you do or do not mark as spam. So in an email client like this, you might click the Spam button to report some email as spam but not other emails. And based on which emails you mark as spam, say your email program learns better how to filter spam email.
. In the 1950, he wrote a checkers playing program and the amazing thing about this checkers playing program was that Arthur Samuel himself wasn't a very good checkers player. But what he did was he had to programmed maybe tens of thousands of games against himself, and by watching what sorts of board positions tended to lead to wins and what sort of board positions tended to lead to losses, the checkers playing program learned over time what are good board positions and what are bad board positions.
- Explanation :
Classifying emails is the task T. In fact, this definition defines a task T performance measure P and some experience E. And so, watching you label emails as spam or not spam, this would be the experience E and and the fraction of emails correctly classified, that might be a performance measure P. And so on the task of systems performance, on the performance measure P will improve after the experience E.
Several types of learning algorithms
There are several different types of learning algorithms. The main two types are what we call supervised learning and unsupervised learning.
In supervised learning, the idea is we're going to teach the computer how to do something. Whereas in unsupervised learning, we're going to let it learn by itself.
Supervised learning - introduction
Probably the most common problem type in machine learning. For example : How do we predict housing prices, first Collect data regarding housing prices and how they relate to size in feet.
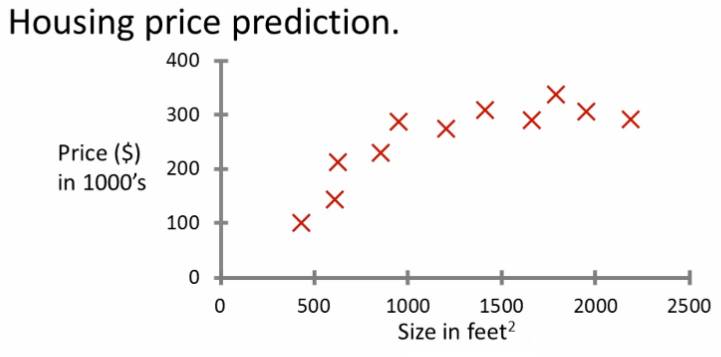
Let's say you want to predict housing prices. A while back a student collected data sets from the City of Portland, Oregon, and let's say you plot the data set and it looks like this.
Here on the horizontal axis, the size of different houses in square feet, and on the vertical axis, the price of different houses in thousands of dollars.
So, given this data, let's say you have a friend who owns a house that is say 750 square feet, and they are hoping to sell the house, and they want to know how much they can get for the house. So, how can the learning algorithm help you?
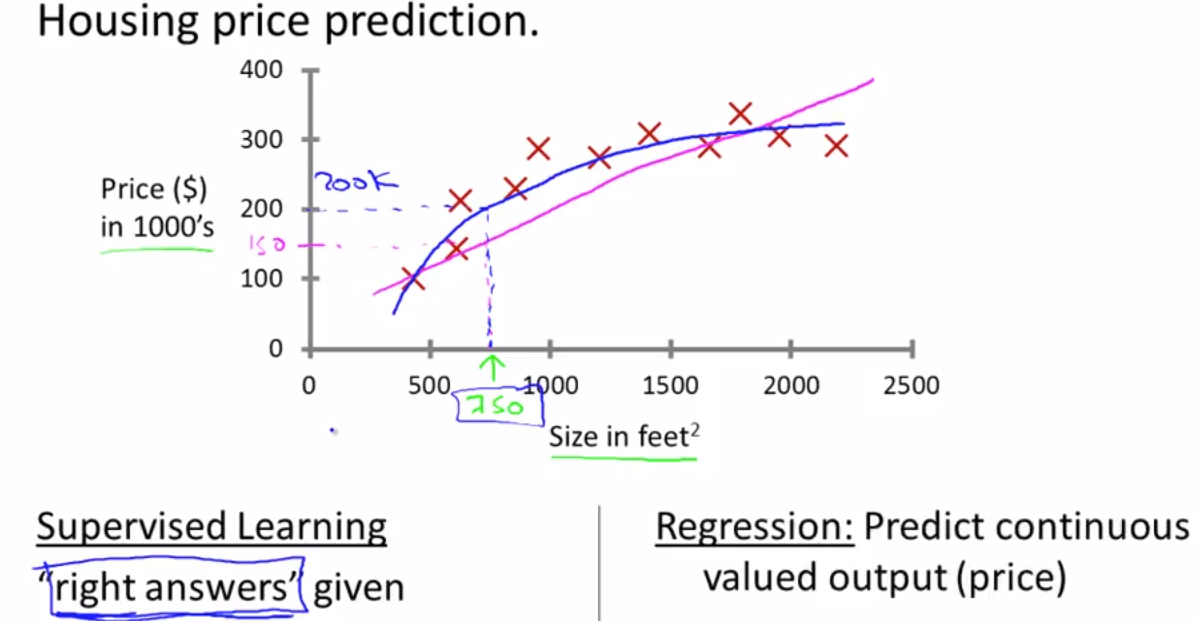
One thing a learning algorithm might be want to do is put a straight line through the data, also fit a straight line to the data. Based on that, it looks like maybe their house can be sold for maybe about $150,000.
But maybe this isn't the only learning algorithm you can use, and there might be a better one. For example, instead of fitting a straight line to the data, we might decide that it's better to fit a quadratic function, or a second-order polynomial to this data.
If you do that and make a prediction here, then it looks like, well, maybe they can sell the house for closer to $200,000.
There's no fair picking whichever one gives your friend the better house to sell.
But each of these would be a fine example of a learning algorithm. So, this is an example of a Supervised Learning algorithm.
The term Supervised Learning refers to the fact that we gave the algorithm a data set in which the, called, "right answers" were given. That is we gave it a data set of houses in which for every example in this data set, we told it what is the right price.
So, what was the actual price that that house sold for, and the task of the algorithm was to just produce more of these right answers such as for this new house that your friend may be trying to sell.
To define a bit more terminology, this is also called a regression problem. By regression problem, we're trying to predict a continuous valued output. Namely the price. So technically prices can be rounded off to the nearest cent. So, maybe prices are actually discrete value.
But usually, we think of the price of a house as a real number, as a scalar value, as a continuous value number, and the term regression refers to the fact that we're trying to predict the sort of continuous values attribute. Here's another Supervised Learning examples.
Let's say you want to look at medical records and try to predict of a breast cancer as malignant or benign. If someone discovers a breast tumor, a lump in their breast, a malignant tumor is a tumor that is harmful and dangerous, and a benign tumor is a tumor that is harmless.
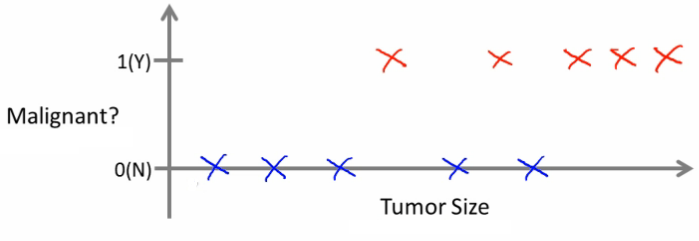
So people care a lot about this. Let's see collected data set. Suppose you are in your dataset, you have on your horizontal axis the size of the tumor, and on the vertical axis, we plot one or zero, yes or no, whether or not these are examples of tumors we've seen before are malignant, which is one, or zero or not malignant or benign.
So, let's say your dataset looks like this, where we saw a tumor of this size that turned out to be benign, one of this size, one of this size, and so on. Sadly, we also saw a few malignant tumors cell, one of that size, one of that size, one of that size, so on.
So in this example, five examples of benign tumors shown down here, and five examples of malignant tumors shown with a vertical axis value of one.
Let's say a friend who tragically has a breast tumor, and let's say her breast tumor size is maybe somewhere around this value, the Machine Learning question is, can you estimate what is the probability, what's the chance that a tumor as malignant versus benign? To introduce a bit more terminology, this is an example of a classification problem.
The term classification refers to the fact, that here, we're trying to predict a discrete value output zero or one, malignant or benign. It turns out that in classification problems, sometimes you can have more than two possible values for the output.
As a concrete example, maybe there are three types of breast cancers. So, you may try to predict a discrete value output zero, one, two, or three, where zero may mean benign, benign tumor, so no cancer, and one may mean type one cancer, maybe three types of cancer, whatever type one means, and two mean a second type of cancer, and three may mean a third type of cancer.
But this will also be a classification problem because this are the discrete value set of output corresponding to you're no cancer, or cancer type one, or cancer type two, or cancer types three.
In classification problems, there is another way to plot this data. So, if tumor size is going to be the attribute that I'm going to use to predict malignancy or benignness, I can also draw my data like this.
I'm going to use different symbols to denote my benign and malignant, or my negative and positive examples. So, instead of drawing crosses, I'm now going to draw O's for the benign tumors, like so, and I'm going to keep using X's to denote my malignant tumors. I hope this figure makes sense.
All I did was I took my data set on top, and I just mapped it down to this real line like so, and started to use different symbols, circles and crosses to denote malignant versus benign examples. Now, in this example, we use only one feature or one attribute, namely the tumor size in order to predict whether a tumor is malignant or benign.
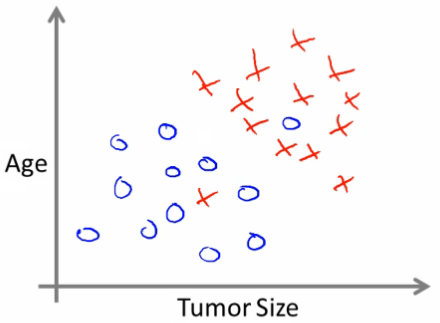
In other machine learning problems, when we have more than one feature or more than one attribute. Here's an example, let's say that instead of just knowing the tumor size, we know both the age of the patients and the tumor size.
In that case, maybe your data set would look like this, where I may have a set of patients with those ages, and that tumor size, and they look like this, and different set of patients that look a little different, whose tumors turn out to be malignant as denoted by the crosses.
So, let's say you have a friend who tragically has a tumor, and maybe their tumor size and age falls around there.
So, given a data set like this, what the learning algorithm might do is fit a straight line to the data to try to separate out the malignant tumors from the benign ones, and so the learning algorithm may decide to put a straight line like that to separate out the two causes of tumors.
With this, hopefully we can decide that your friend's tumor is more likely, if it's over there that hopefully your learning algorithm will say that your friend's tumor falls on this benign side and is therefore more likely to be benign than malignant.
In this example, we had two features namely, the age of the patient and the size of the tumor. In other Machine Learning problems, we will often have more features.
It turns out one of the most interesting learning algorithms that we'll see in this course, as the learning algorithm that can deal with not just two, or three, or five features, but an infinite number of features. On this slide, I've listed a total of five different features.
Two on the axis and three more up here. But it turns out that for some learning problems what you really want is not to use like three or five features, but instead you want to use an infinite number of features, an infinite number of attributes, so that your learning algorithm has lots of attributes, or features, or cues with which to make those predictions. So, how do you deal with an infinite number of features?
How do you even store an infinite number of things in the computer when your computer is going to run out of memory? It turns out that when we talk about an algorithm called the Support Vector Machine, there will be a neat mathematical trick that will allow a computer to deal with an infinite number of features.
Imagine that I didn't just write down two features here and three features on the right, but imagine that I wrote down an infinitely long list. I just kept writing more and more features, like an infinitely long list of features. It turns out we will come up with an algorithm that can deal with that.
So, just to recap, in this course, we'll talk about Supervised Learning, and the idea is that in Supervised Learning, in every example in our data set, we are told what is the correct answer that we would have quite liked the algorithms have predicted on that example.
Such as the price of the house, or whether a tumor is malignant or benign. We also talked about the regression problem, and by regression that means that our goal is to predict a continuous valued output.
We talked about the classification problem where the goal is to predict a discrete value output.

- Explanation :
For problem one, I would treat this as a regression problem because if I have thousands of items, well, I would probably just treat this as a real value, as a continuous value. Therefore, the number of items I sell as a continuous value. For the second problem, I would treat that as a classification problem, because I might say set the value I want to predict with zero to denote the account has not been hacked, and set the value one to denote an account that has been hacked into. So, just like your breast cancers where zero is benign, one is malignant. So, I might set this be zero or one depending on whether it's been hacked, and have an algorithm try to predict each one of these two discrete values. Because there's a small number of discrete values, I would therefore treat it as a classification problem.
Unsupervised Learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don't necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
Example: Clustering: Take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on.
Non-clustering: The "Cocktail Party Algorithm", allows you to find structure in a chaotic environment. (i.e. identifying individual voices and music from a mesh of sounds at a cocktail party
In Unsupervised Learning, we're given data that looks different than data that looks like this that doesn't have any labels or that all has the same label or really no labels.
One example where clustering is used is in Google News and if you have not seen this before, you can actually go to this URL news.google.com to take a look. What Google News does is everyday it goes and looks at tens of thousands or hundreds of thousands of new stories on the web and it groups them into cohesive news stories.
An example of DNA microarray data. The idea is put a group of different individuals and for each of them, you measure how much they do or do not have a certain gene. Technically you measure how much certain genes are expressed. So these colors, red, green, gray and so on, they show the degree to which different individuals do or do not have a specific gene.
So this is Unsupervised Learning because we're not telling the algorithm in advance that these are type 1 people, those are type 2 persons, those are type 3 persons and so on and instead what were saying is yeah here's a bunch of data. I don't know what's in this data. I don't know who's and what type. I don't even know what the different types of people are, but can you automatically find structure in the data from the you automatically cluster the individuals into these types that I don't know in advance? Because we're not giving the algorithm the right answer for the examples in my data set, this is Unsupervised Learning.
Social network analysis. : Given knowledge about which friends you email the most or given your Facebook friends or your Google+ circles, can we automatically identify which are cohesive groups of friends, also which are groups of people that all know each other?
Market segmentation. : Many companies have huge databases of customer information. So, can you look at this customer data set and automatically discover market segments and automatically . Group your customers into different market segments so that you can automatically and more efficiently sell or market your different market segments together?
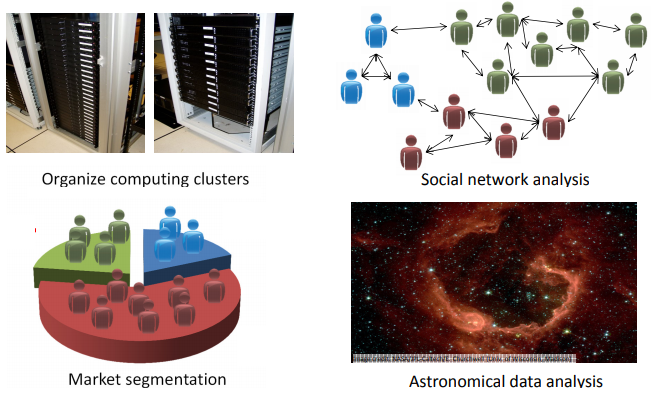
- Explanation :
News articles and customer segmentation are unsupervised as no labels are given