Unsupervised learning algorithm
We start to talk about clustering. It is our first unsupervised learning algorithm, where we learn from unlabeled data instead from labelled data.
So, what is unsupervised learning? A typical supervised learning problem is where we're given a labeled training set and the goal is to find the decision boundary that separates the positive label examples and the negative label examples.
So, the supervised learning problem in this case is given a set of labels to fit a hypothesis to it. In contrast, in the unsupervised learning problem we're given data that does not have any labels associated with it.
So, we're given data that looks like this. Here's a set of points add in no labels, and so, our training set is written just x1, x2, and so on up to xm and we don't get any labels y.
And that's why the points plotted up on the figure don't have any labels with them. So, in unsupervised learning what we do is we give this sort of unlabeled training set to an algorithm and we just ask the algorithm find some structure in the data for us.
Given this data set one type of structure we might have an algorithm find is that it looks like this data set has points grouped into two separate clusters and so an algorithm that finds clusters is called a clustering algorithm.
And this would be our first type of unsupervised learning, although there will be other types of unsupervised learning algorithms that we'll talk about later that finds other types of structure or other types of patterns in the data other than clusters.
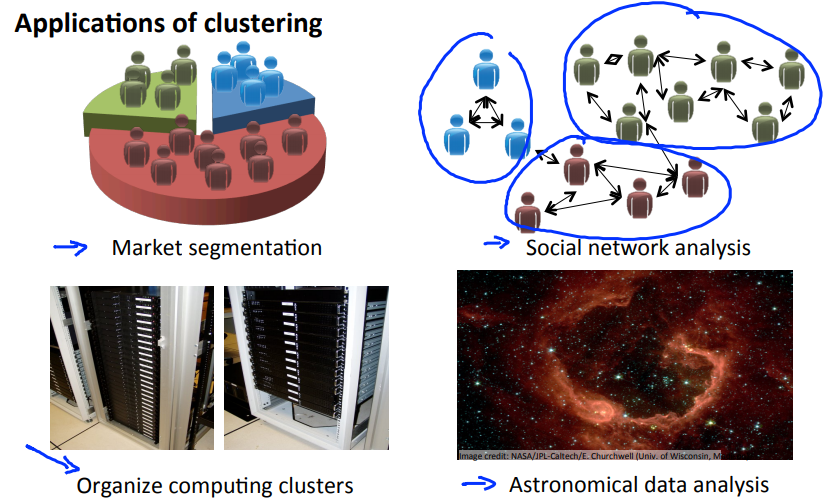
We'll talk about this after we've talked about clustering. So, what is clustering good for? One is market segmentation where you may have a database of customers and want to group them into different marker segments so you can sell to them separately or serve your different market segments better. Social network analysis.
There are actually groups have done this things like looking at a group of people's social networks. So, things like Facebook, Google+, or maybe information about who other people that you email the most frequently and who are the people that they email the most frequently and to find coherence in groups of people.
So, this would be another maybe clustering algorithm where you know want to find who are the coherent groups of friends in the social network?