Basics of Wi-Fi
Wi-Fi is a technology for wireless local area networking with devices based on the IEEE 802.11 standards.
Devices that can use Wi-Fi technology include personal computers, video-game consoles, smartphones and tablets, digital cameras, smart TVs, digital audio players and modern printers. Wi-Fi compatible devices can connect to the Internet via a WLAN and a wireless access point. Such an access point (or hotspot) has a range of about 20 meters (66 feet) indoors and a greater range outdoors. Hotspot coverage can be as small as a single room with walls that block radio waves, or as large as many square kilometres achieved by using multiple overlapping access points
Wi-Fi most commonly uses the 2.4 gigahertz (12 cm) UHF and 5.8 gigahertz (5 cm) SHF ISM radio bands. Anyone within range with a wireless network interface controller can attempt to access the network; because of this, Wi-Fi is more vulnerable to attack (called eavesdropping) than wired networks.
Wi-Fi also allows communications directly from one computer to another without an access point intermediary. This is called ad hoc Wi-Fi transmission.
Frame Control: Indicates the type of frame (control, management, or data) and provides control information. Control information includes whether the frame is to or from a DS, fragmentation information, and privacy information.
Duration/Connection ID: If used as a duration field, indicates the time (in microseconds) the channel will be allocated for successful transmission of a MAC frame. In some control frames, this field contains an association, or connection, identifier.
Addresses: The number and meaning of the 48-bit address fields depend on context. The transmitter address and receiver address are the MAC addresses of stations joined to the BSS that are transmitting and receiving frames over the wireless LAN. The service set ID (SSID) identifies the wireless LAN over which a frame is transmitted.
For an IBSS, the SSID is a random number gen- erated at the time the network is formed. For a wireless LAN that is part of a larger configuration the SSID identifies the BSS over which the frame is trans- mitted; specifically, the SSID is the MAC-level address of the AP for this BSS.
Finally the source address and destination address are the MAC addresses of stations, wireless or otherwise, that are the ultimate source and destination of this frame. The source address may be identical to the transmit- ter address and the destination address may be identical to the receiver address.
Sequence Control: Contains a 4-bit fragment number subfield, used for frag- mentation and reassembly, and a 12-bit sequence number used to number frames sent between a given transmitter and receiver.
Frame Body: Contains an MSDU or a fragment of an MSDU. The MSDU is a LLC protocol data unit or MAC control information. Frame Check Sequence: A 32-bit cyclic redundancy check.

Architecture of WiFi
Stations : All components that can connect into a wireless medium in a network are referred to as stations (STA). All stations are equipped with wireless network interface controllers (WNICs). Wireless stations fall into two categories: wireless access points, and clients. Access points (APs), normally wireless routers, are base stations for the wireless network. They transmit and receive radio frequencies for wireless enabled devices to communicate with. Wireless clients can be mobile devices such as laptops, personal digital assistants, IP phones and other smartphones, or non-portable devices such as desktop computers and workstations that are equipped with a wireless network interface.
Basic service set : The basic service set (BSS) is a set of all stations that can communicate with each other at PHY layer. Every BSS has an identification (ID) called the BSSID, which is the MAC address of the access point servicing the BSS.
There are two types of BSS: Independent BSS (also referred to as IBSS), and infrastructure BSS. An independent BSS (IBSS) is an ad hoc network that contains no access points, which means they cannot connect to any other basic service set.
Independent basic service set : An IBSS is a set of STAs configured in ad hoc (peer-to-peer)mode.
Extended service set : An extended service set (ESS) is a set of connected BSSs. Access points in an ESS are connected by a distribution system. Each ESS has an ID called the SSID which is a 32-byte (maximum) character string.
Distribution system : A distribution system (DS) connects access points in an extended service set. The concept of a DS can be used to increase network coverage through roaming between cells. DS can be wired or wireless. Current wireless distribution systems are mostly based on WDS or MESH protocols, though other systems are in use.
Types of wireless LANs
The IEEE 802.11 has two basic modes of operation: infrastructure and ad hoc mode. In ad hoc mode, mobile units transmit directly peer-to-peer. In infrastructure mode, mobile units communicate through an access point that serves as a bridge to other networks (such as Internet or LAN).
Since wireless communication uses a more open medium for communication in comparison to wired LANs, the 802.11 designers also included encryption mechanisms: Wired Equivalent Privacy (WEP, now insecure), Wi-Fi Protected Access (WPA, WPA2), to secure wireless computer networks. Many access points will also offer Wi-Fi Protected Setup, a quick (but now insecure) method of joining a new device to an encrypted network.
Infrastructure : Most Wi-Fi networks are deployed in infrastructure mode.
In infrastructure mode, a base station acts as a wireless access point hub, and nodes communicate through the hub. The hub usually, but not always, has a wired or fiber network connection, and may have permanent wireless connections to other nodes.
Wireless access points are usually fixed, and provide service to their client nodes within range.
Wireless clients, such as laptops, smartphones etc. connect to the access point to join the network.
Sometimes a network will have a multiple access points, with the same 'SSID' and security arrangement. In that case connecting to any access point on that network joins the client to the network. In that case, the client software will try to choose the access point to try to give the best service, such as the access point with the strongest signal.
Peer-to-peer : Peer-to-Peer or ad hoc wireless LAN. An ad hoc network (not the same as a WiFi Direct network) is a network where stations communicate only peer to peer (P2P). There is no base and no one gives permission to talk. This is accomplished using the Independent Basic Service Set (IBSS).
A WiFi Direct network is another type of network where stations communicate peer to peer.
In a Wi-Fi P2P group, the group owner operates as an access point and all other devices are clients. There are two main methods to establish a group owner in the Wi-Fi Direct group. In one approach, the user sets up a P2P group owner manually. This method is also known as Autonomous Group Owner (autonomous GO). In the second method, also called negotiation-based group creation, two devices compete based on the group owner intent value. The device with higher intent value becomes a group owner and the second device becomes a client. Group owner intent value can depend on whether the wireless device performs a cross-connection between an infrastructure WLAN service and a P2P group, remaining power in the wireless device, whether the wireless device is already a group owner in another group and/or a received signal strength of the first wireless device.
A peer-to-peer network allows wireless devices to directly communicate with each other. Wireless devices within range of each other can discover and communicate directly without involving central access points. This method is typically used by two computers so that they can connect to each other to form a network. This can basically occur in devices within a closed range.
If a signal strength meter is used in this situation, it may not read the strength accurately and can be misleading, because it registers the strength of the strongest signal, which may be the closest computer.
Hidden node problem: Devices A and C are both communicating with B, but are unaware of each other. IEEE 802.11 defines the physical layer (PHY) and MAC (Media Access Control) layers based on CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance). The 802.11 specification includes provisions designed to minimize collisions, because two mobile units may both be in range of a common access point, but out of range of each other.
Bridge : A bridge can be used to connect networks, typically of different types. A wireless Ethernet bridge allows the connection of devices on a wired Ethernet network to a wireless network. The bridge acts as the connection point to the Wireless LAN.
Wireless distribution system : A Wireless Distribution System enables the wireless interconnection of access points in an IEEE 802.11 network. It allows a wireless network to be expanded using multiple access points without the need for a wired backbone to link them, as is traditionally required. The notable advantage of DS over other solutions is that it preserves the MAC addresses of client packets across links between access points.
An access point can be either a main, relay or remote base station. A main base station is typically connected to the wired Ethernet. A relay base station relays data between remote base stations, wireless clients or other relay stations to either a main or another relay base station. A remote base station accepts connections from wireless clients and passes them to relay or main stations. Connections between "clients" are made using MAC addresses rather than by specifying IP assignments.
All base stations in a Wireless Distribution System must be configured to use the same radio channel, and share WEP keys or WPA keys if they are used. They can be configured to different service set identifiers. WDS also requires that every base station be configured to forward to others in the system as mentioned above.
WDS may also be referred to as repeater mode because it appears to bridge and accept wireless clients at the same time (unlike traditional bridging). Throughput in this method is halved for all clients connected wirelessly.
When it is difficult to connect all of the access points in a network by wires, it is also possible to put up access points as repeaters.
Cryptography
Cryptography, a word with Greek origins, means "secret writing." However, we use the term to refer to the science and art of transforming messages to make them secure and immune to attacks.
The original message, before being transformed, is called plaintext. After the message is transformed, it is called ciphertext. An encryption algorithm transforms the plaintext into ciphertext; a decryption algorithm transforms the ciphertext back into plaintext. The sender uses an encryption algorithm, and the receiver uses a decryption algorithm.
We refer to encryption and decryption algorithms as ciphers. The term cipher is also used to refer to different categories of algorithms in cryptography. This is not to say that every sender-receiver pair needs their very own unique cipher for a secure communication. On the contrary, one cipher can serve millions of communicating pairs.
A key is a number (or a set of numbers) that the cipher, as an algorithm, operates on. To encrypt a message, we need an encryption algorithm, an encryption key, and the plaintext. These create the ciphertext. To decrypt a message, we need a decryption algorithm, a decryption key, and the ciphertext. These reveal the original plaintext.
We can divide all the cryptography algorithms (ciphers) into two groups: symmetric key (also called secret-key) cryptography algorithms and asymmetric (also called public-key) cryptography algorithms.
Symmetric-Key Cryptography : In symmetric-key cryptography, the same key is used by both parties. The sender uses this key and an encryption algorithm to encrypt data; the receiver uses the same key and the corresponding decryption algorithm to decrypt the data
In asymmetric or public-key cryptography, there are two keys: a private key and a public key. The private key is kept by the receiver. The public key is announced to the public. In Figure below, imagine Alice wants to send a message to Bob. Alice uses the public key to encrypt the message. When the message is received by Bob, the private key is used to decrypt the message.
In public-key encryption/decryption, the public key that is used for encryption is different from the private key that is used for decryption. The public key is available to the public; the private key is available only to an individual.
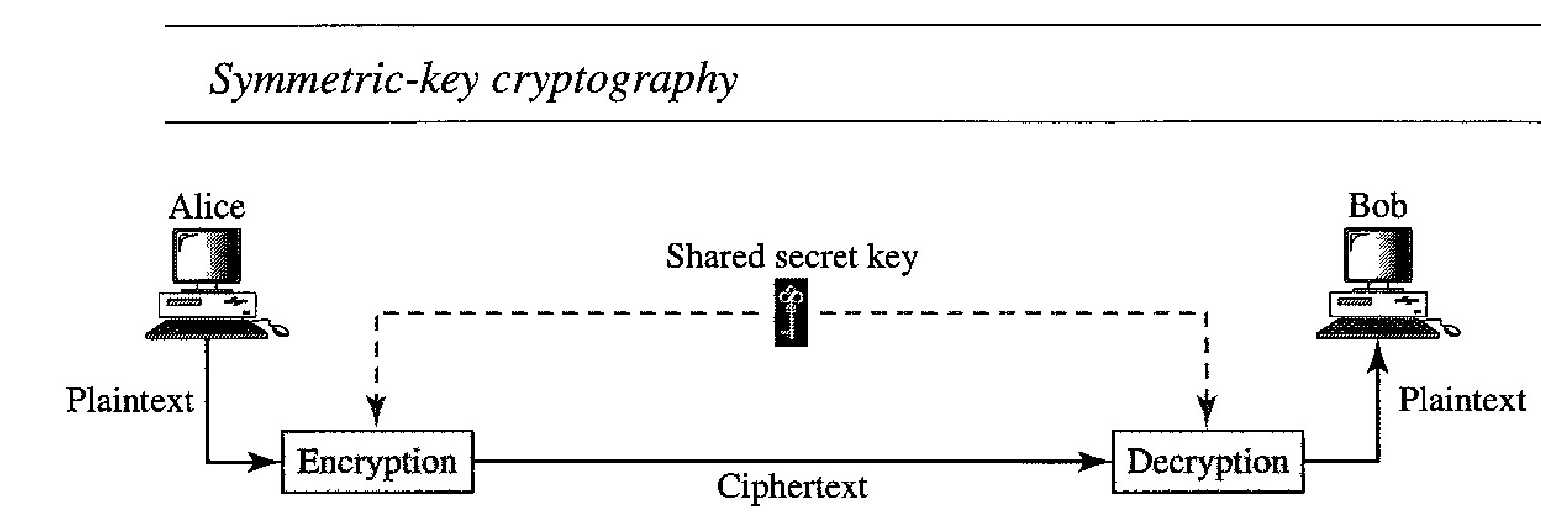
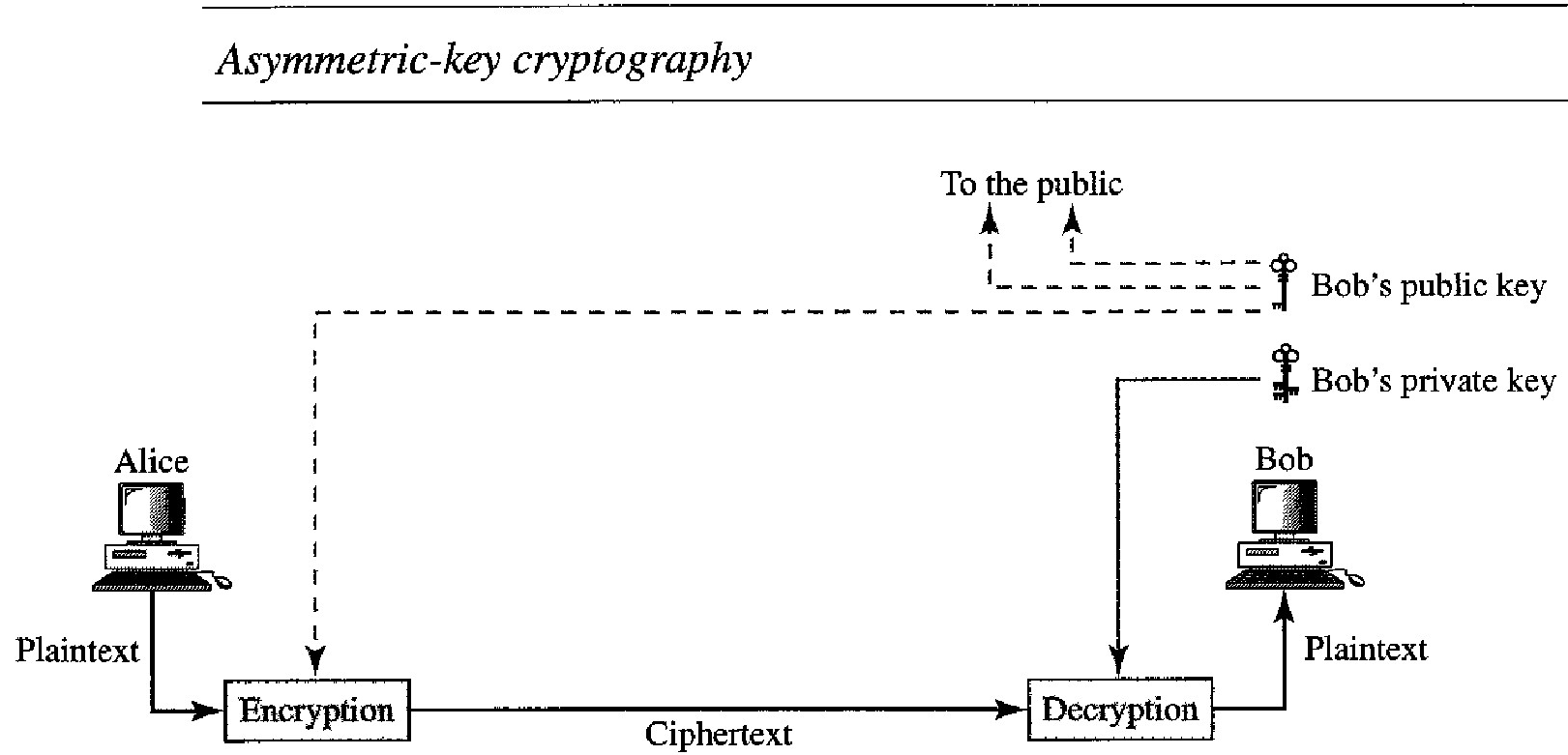
SYMMETRIC-KEY CRYPTOGRAPHY
Traditional ciphers are character-oriented. Although these are now obsolete, the goal is to show how modern ciphers evolved from them. We can divide traditional symmetric-key ciphers into two broad categories: substitution ciphers and transposition ciphers
A substitution cipher substitutes one symbol with another.
If the symbols in the plaintext are alphabetic characters, we replace one character with another.
For example, we can replace character A with D, and character T with Z.
If the symbols are digits (0 to 9), we can replace 3 with 7, and 2 with 6.
Substitution ciphers can be categorized as either monoalphabetic or polyalphabetic ciphers.
In a monoalphabetic cipher, a character (or a symbol) in the plaintext is always changed to the same character (or symbol) in the ciphertext regardless of its position in the text.
For example, if the algorithm says that character A in the plaintext is changed to character D, every character A is changed to character D.
In other words, the relationship between characters in the plaintext and the ciphertext is a one-to-one relationship.
In a polyalphabetic cipher, each occurrence of a character can have a different substitute. The relationship between a character in the plaintext to a character in the ciphertext is a one-to-many relationship. For example, character A could be changed to D in the beginning of the text, but it could be changed to N at the middle.
It is obvious that if the relationship between plaintext characters and ciphertext characters is one-to- many, the key must tell us which of the many possible characters can be chosen for encryption.
To achieve this goal, we need to divide the text into groups of characters and use a set of keys. For example, we can divide the text "THISISANEASYTASK" into groups of 3 characters and then apply the encryption using a set of 3 keys. We then repeat the procedure for the next 3 characters.
Shift Cipher : We assume that the plaintext and ciphertext consist of uppercase letters (A to Z) only. In this cipher, the encryption algorithm is "shift key characters down," with key equal to some number. The decryption algorithm is "shift key characters up." For example, if the key is 5, the encryption algorithm is "shift 5 characters down" (toward the end of the alphabet). The decryption algorithm is "shift 5 characters up" (toward the beginning of the alphabet). Of course, if we reach the end or beginning of the alphabet, we wrap around. Julius Caesar used the shift cipher to communicate with his officers. For this reason, the shift cipher is sometimes referred to as the Caesar cipher. Caesar used a key of 3 for his communications.
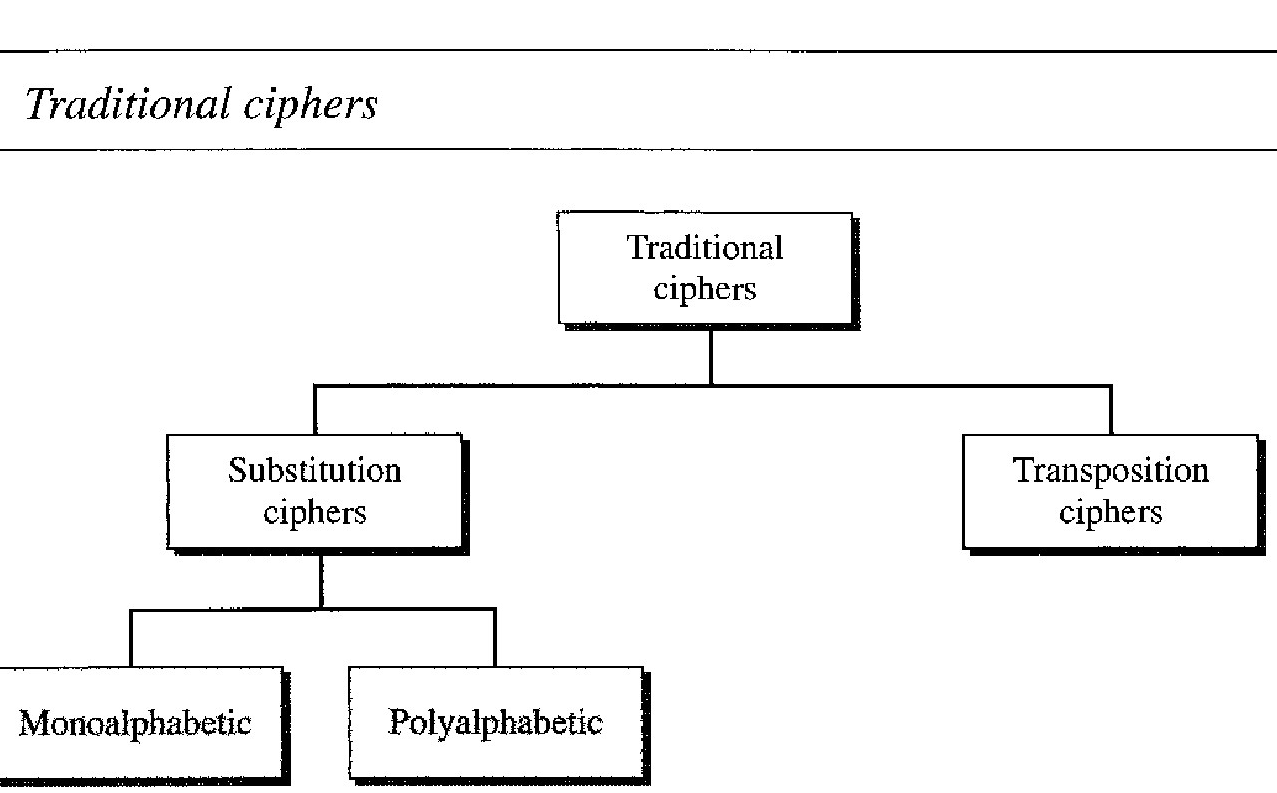
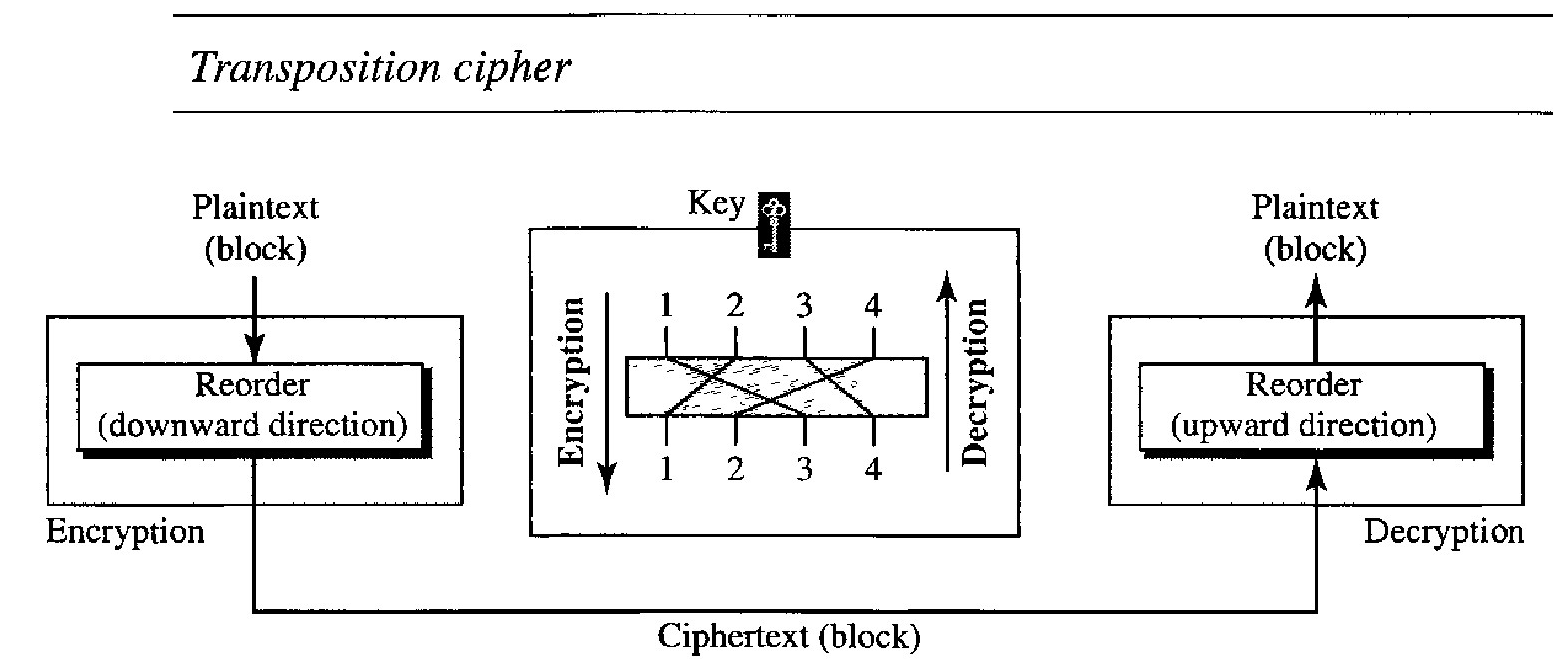
Transposition Ciphers
In a transposition cipher, there is no substitution of characters; instead, their locations change. A character in the first position of the plaintext may appear in the tenth position of the ciphertext. A character in the eighth position may appear in the first position. In other words, a transposition cipher reorders the symbols in a block of symbols.
In a transposition cipher, the key is a mapping between the position of the symbols in the plaintext and cipher text. For example, the following shows the key using a block of four characters: Plaintext: 2 4 1 3 ; Ciphertext: 1 2 3 4
In encryption, we move the character at position 2 to position 1, the character at position 4 to position 2, and so on. In decryption, we do the reverse. Note that, to be more effective, the key should be long, which means encryption and decryption of long blocks of data.
Q. The following shows a plaintext and its corresponding ciphertext. Is the cipher monoalphabetic? Plaintext: HELLO Ciphertext: KHOOR
The cipher is probably monoalphabetic because both occurrences of L's are encrypted as O's
Q. The following shows a plaintext and its corresponding ciphertext. Is the cipher monoalphabetic? Plaintext: HELLO Ciphertext: ABNZF
The cipher is not monoalphabetic because each occurrence of L is encrypted by a different character. The first L is encrypted as N; the second as Z.
Q. Use the shift cipher with key = 15 to encrypt the message "HELLO."
We encrypt one character at a time. Each character is shifted 15 characters down. Letter H is encrypted to W. Letter E is encrypted to T. The first L is encrypted to A. The second L is also encrypted to A. And 0 is encrypted to D. The cipher text is WTAAD.
Q. Use the shift cipher with key = 15 to decrypt the message "WTAAD."
We decrypt one character at a time. Each character is shifted 15 characters up. Letter W is decrypted to H. Letter T is decrypted to E. The first A is decrypted to L. The second A is decrypted to L. And, finally, D is decrypted to O. The plaintext is HELLO.
Q. Encrypt the message "HELLO MY DEAR," using the above key given in figure of transposition ciphers.
We first remove the spaces in the message. We then divide the text into blocks of four characters. We add a bogus character Z at the end of the third block. The result is HELL OMYD EARZ. We create a three-block ciphertext ELHLMDOYAZER.
Q. Using Example given above, decrypt the message "ELHLMDOYAZER".
The result is HELL OMYD EARZ. After removing the bogus character and combining the characters, we get the original message "HELLO MY DEAR."
Simple Modern Ciphers
The traditional ciphers we have studied so far are character-oriented. With the advent of the computer, ciphers need to be bit-oriented.
This is so because the information to be encrypted is not just text; it can also consist of numbers, graphics, audio, and video data.
It is convenient to convert these types of data into a stream of bits, encrypt the stream, and then send the encrypted stream.
In addition, when text is treated at the bit level, each character is replaced by 8 (or 16) bits, which means the number of symbols becomes 8 (or 16).
Mingling and mangling bits provides more security than mingling and mangling characters.
XOR Cipher : Modern ciphers today are normally made of a set of simple ciphers, which are simple predefined functions in mathematics or computer science. XOR cipher uses the exclusive-or operation as defined in computer science. An XOR operation needs two data inputs plaintext, as the first and a key as the second. In other words, one of the inputs is the block to be the encrypted, the other input is a key; the result is the encrypted block. Note that in an XOR cipher, the size of the key, the plaintext, and the ciphertext are all the same. XOR ciphers have a property: the encryption and decryption are the same.
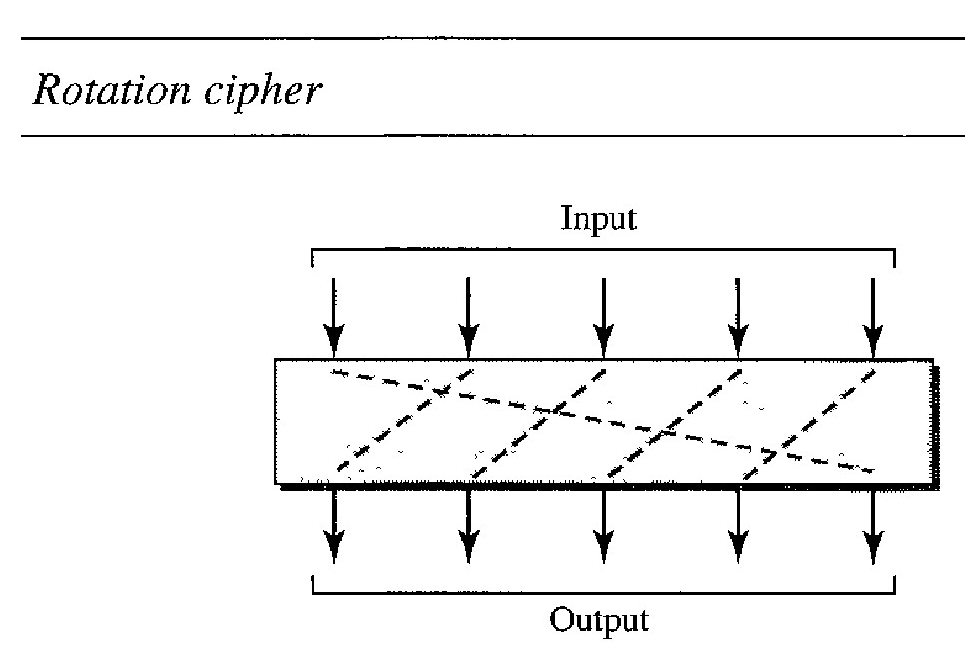
Rotation Cipher : The input bits are rotated to the left or right. The rotation cipher can be keyed or keyless. In keyed rotation, the value of the key defines the number of rotations; in keyless rotation the number of rotations is fixed. Figure below shows an example of a rotation cipher. Note that the rotation cipher can be considered a special case of the transpositional cipher using bits instead of characters. The rotation cipher has an interesting property. If the length of the original stream is N, after N rotations, we get the original input stream. This means that it is useless to apply more than N - 1 rotations. In other words, the number of rotations must be between 1 and N-1. The decryption algorithm for the rotation cipher uses the same key and the opposite rotation direction. If we use a right rotation in the encryption, we use a left rotation in decryption and vice versa.
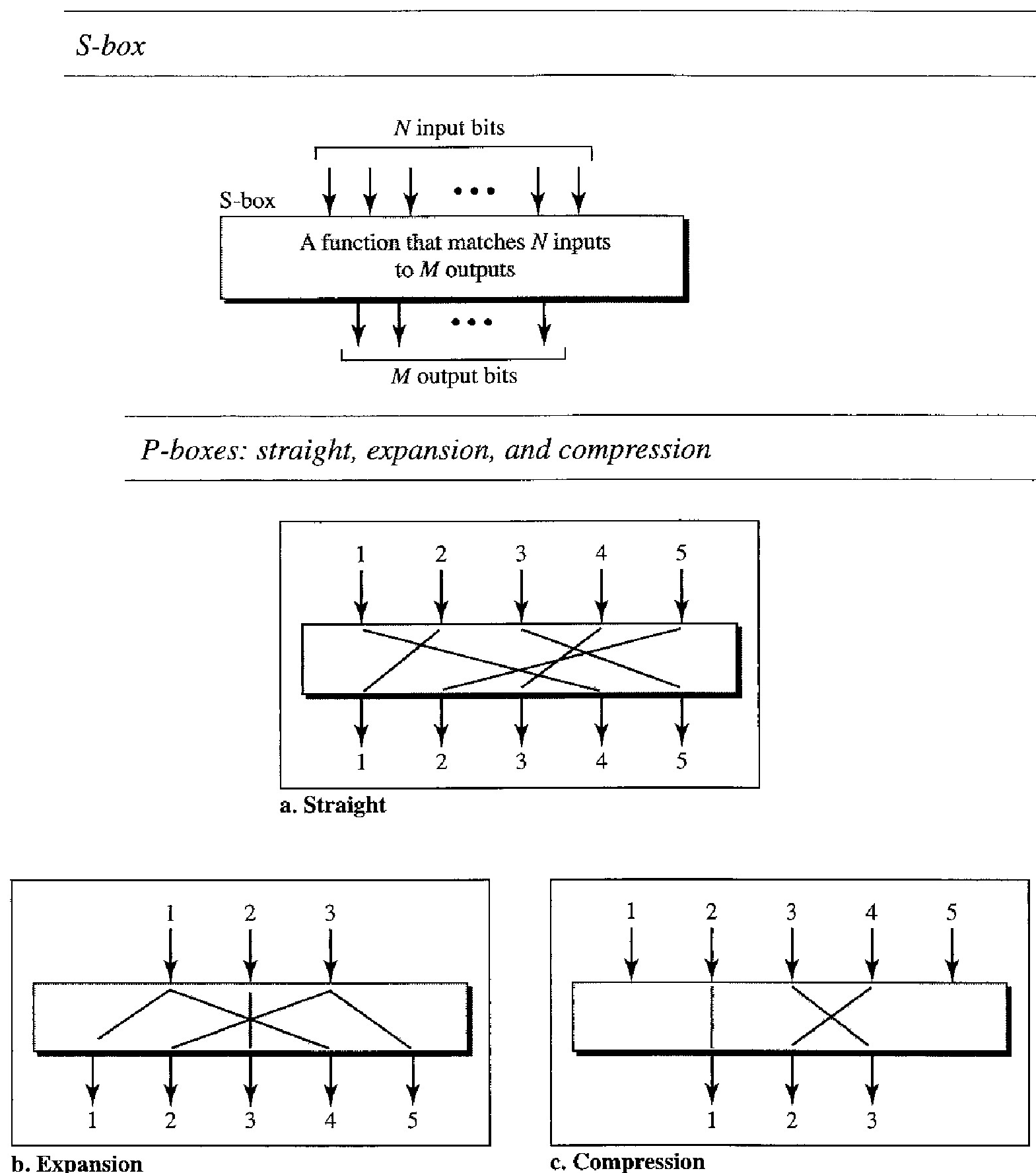
Substitution Cipher: S-box An S-box (substitution box) parallels the traditional substitution cipher for characters. The input to an S-box is a stream of bits with length N; the result is another stream of bits with length M. And N and M are not necessarily the same. Figure below shows an S-box. The S-box is normally keyless and is used as an intermediate stage of encryption or decryption. The function that matches the input to the output may be defined mathematically or by a table.
Transposition Cipher: P-box A P-box (permutation box) for bits parallels the traditional transposition cipher for char- acters. It performs a transposition at the bit level; it transposes bits. It can be implemented in software or hardware, but hardware is faster. P-boxes, like S-boxes, are normally keyless. We can have three types of permutations in P-boxes: the straight permutation, expansion permutation, and compression permutation
A straight permutation cipher or a straight P-box has the same number of inputs as outputs. So, if the number of inputs is N, the number of outputs is also N. In an expansion permutation cipher, the number of output ports is greater than the number of input ports. In a compression permutation cipher, the number of output ports is less than the number of input ports.
Modern Round Ciphers - AES and DES
These ciphers are referred to as block ciphers because they divide the plaintext into blocks and use the same key to encrypt and decrypt the blocks. DES has been the de facto standard until recently. AES is the formal standard now.
The ciphers of today are called round ciphers because they involve multiple rounds, where each round is a complex cipher made up of the simple ciphers
The key used in each round is a subset or variation of the general key called the round key. If the cipher has N rounds, a key generator produces N keys, K1, K2, ..• , KN, where K1 is used in round 1, K2 in round 2, and so on.
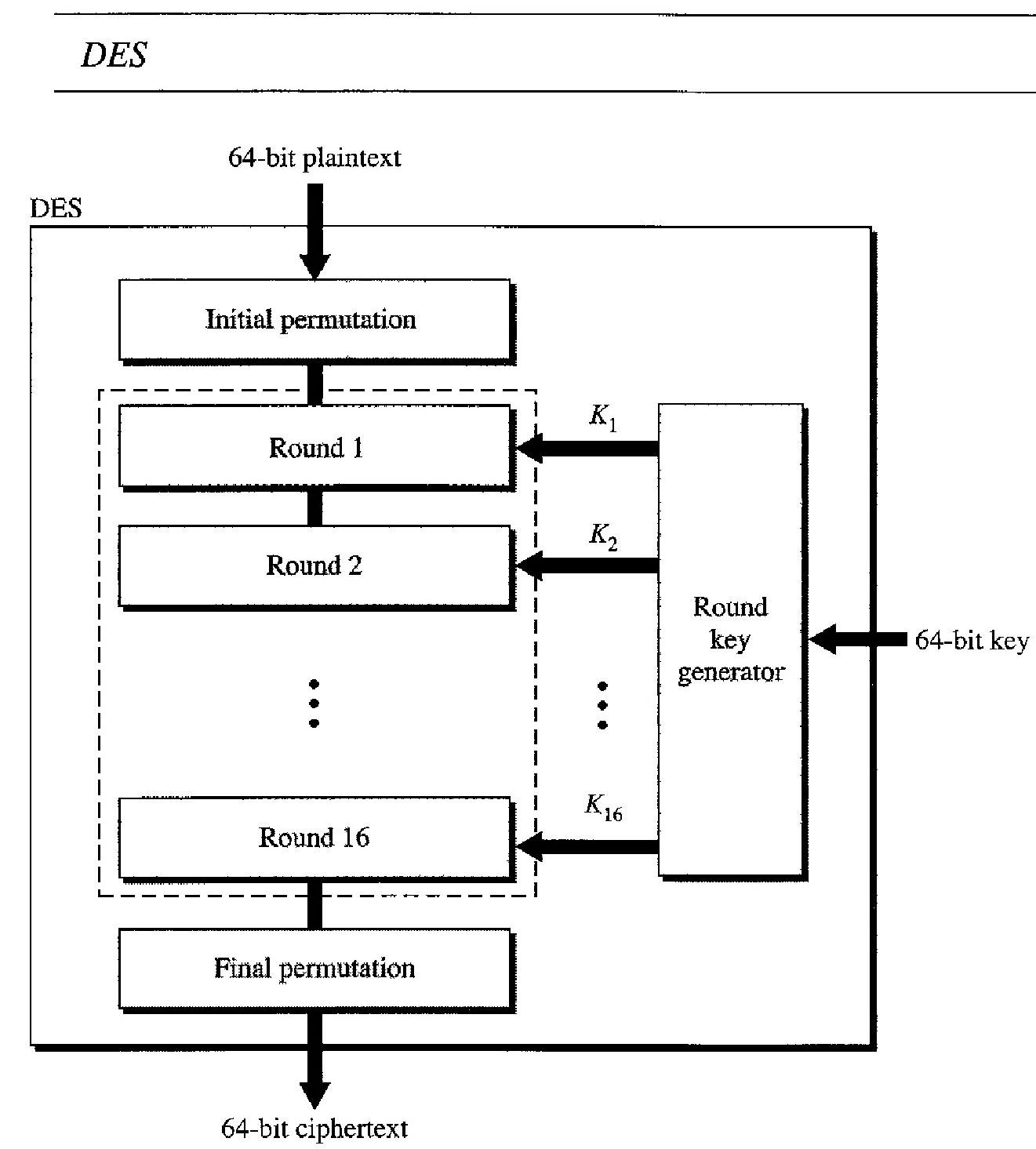
Data Encryption Standard (DES)
The algorithm encrypts a 64-bit plaintext block using a 64-bit key
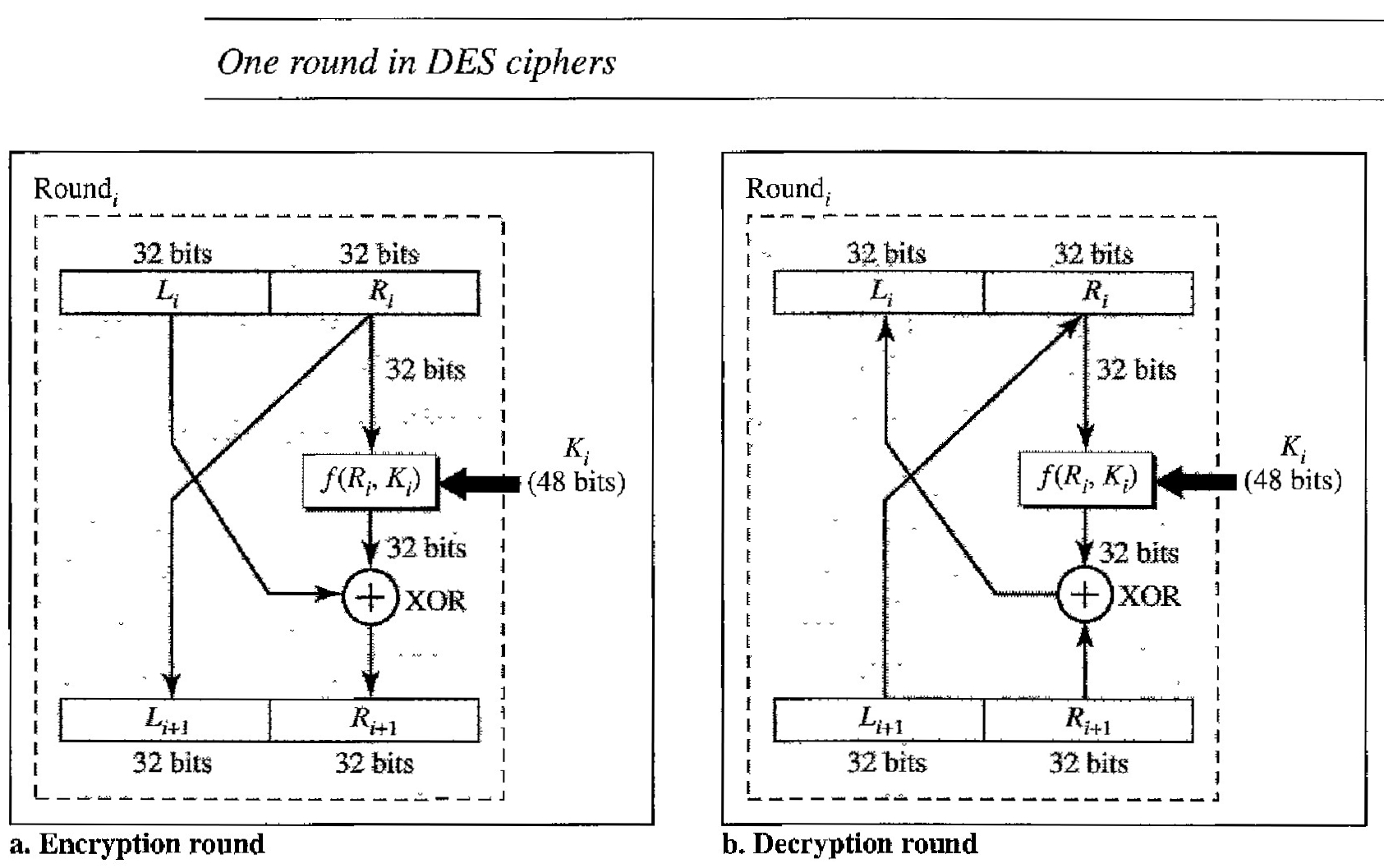
DES has two transposition blocks (P-boxes) and 16 complex round ciphers (they are repeated). Although the 16 iteration round ciphers are conceptually the same, each uses a different key derived from the original key.
The initial and final permutations are keyless straight permutations that are the inverse of each other. The permutation takes a 64-bit input and permutes them according to predefined values.
Each round of DES is a complex round cipher, as shown in Figure below. Note that the structure of the encryption round ciphers is different from that of the decryption one.
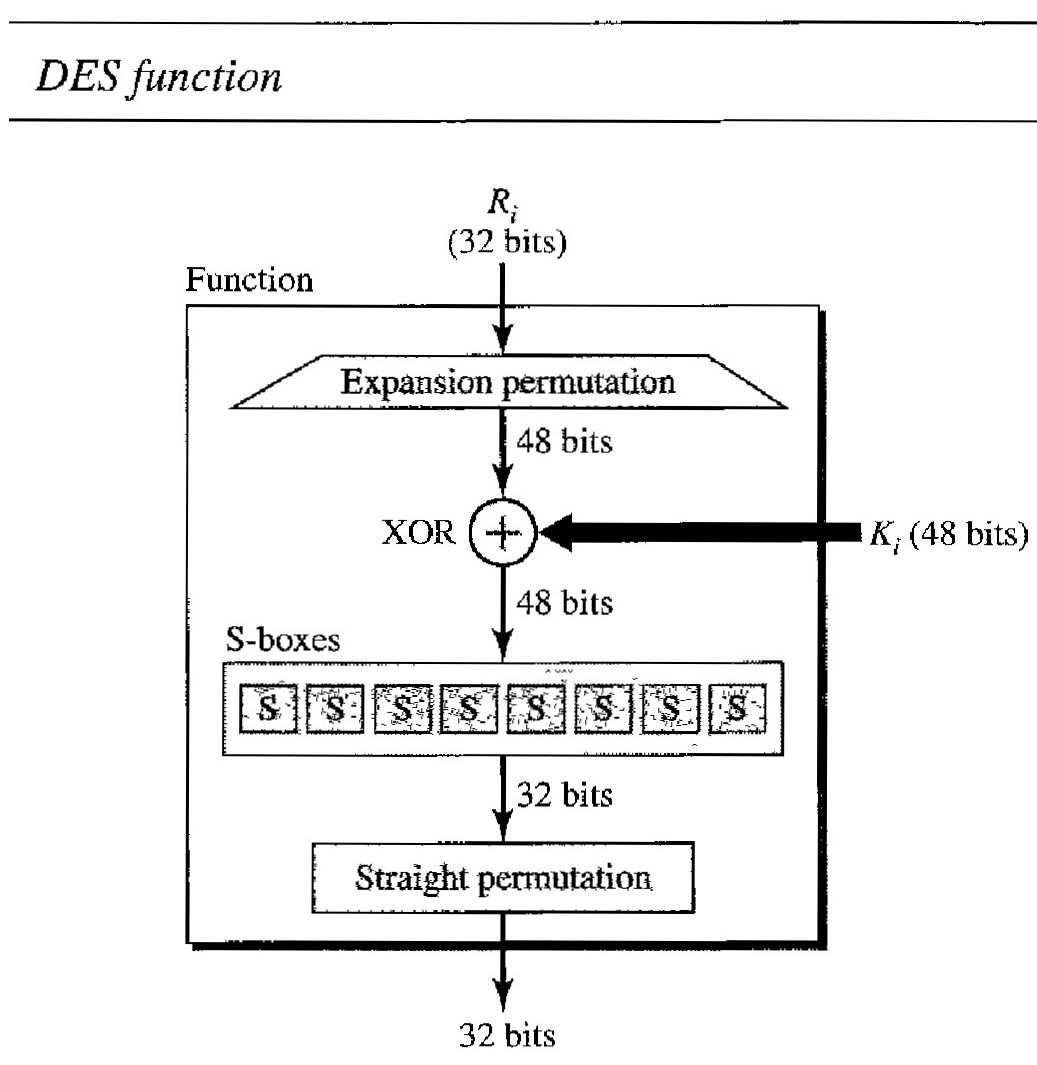
DES Function : The heart of DES is the DES function. The DES function applies a 48-bit key to the rightmost 32 bits Ri, to produce a 32-bit output. This function is made up of four operations: an XOR, an expansion permutation, a group of S-boxes, and a straight permutation
Advanced Encryption Standard (AES)
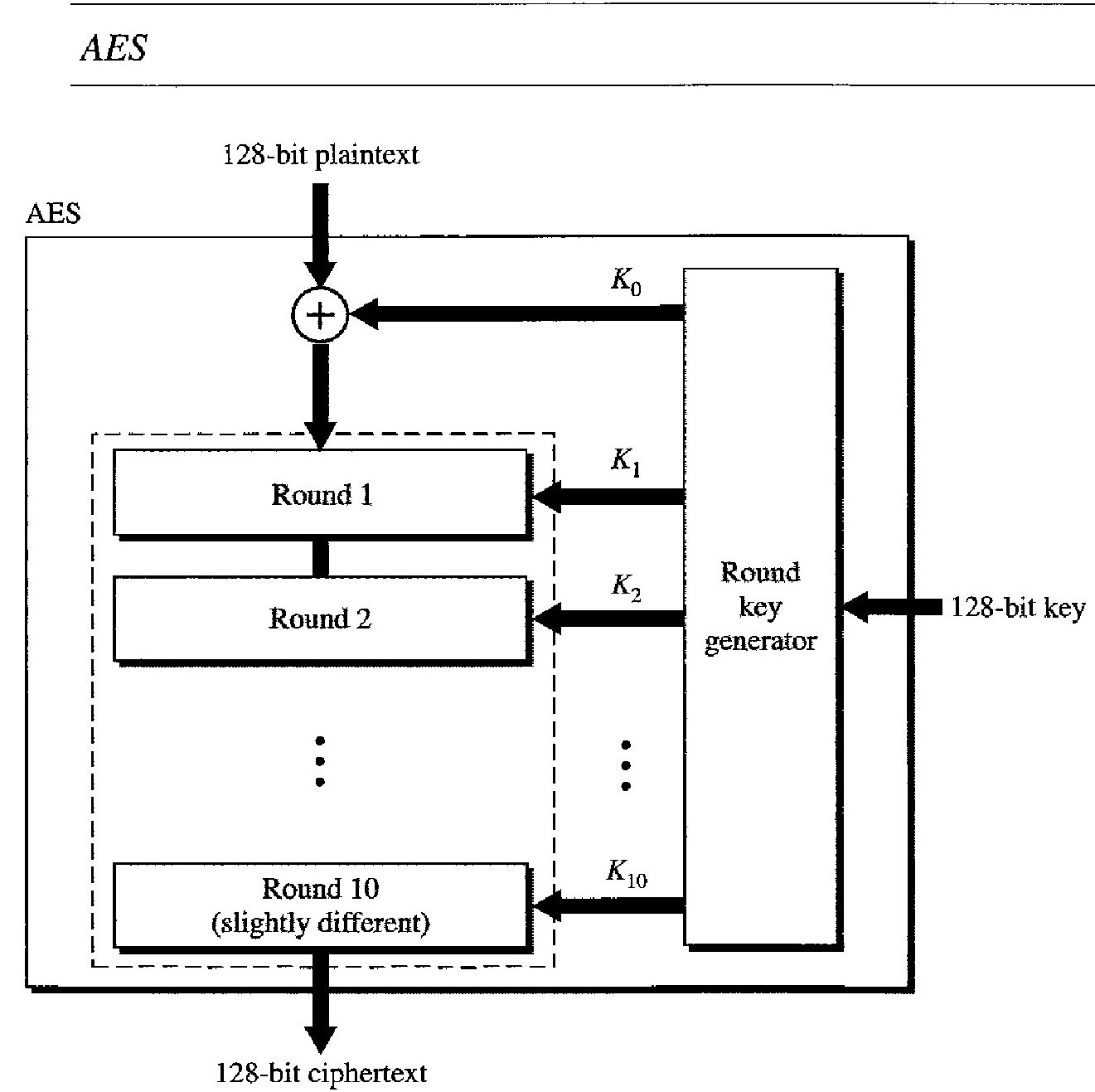
The Advanced Encryption Standard (AES) was designed because DES's key was too small. Although Triple DES (3DES) increased the key size, the process was too slow. AES is a very complex round cipher. AES is designed with three key sizes: 128, 192, or 256 bits. Size of data block in AES is 128 bits.
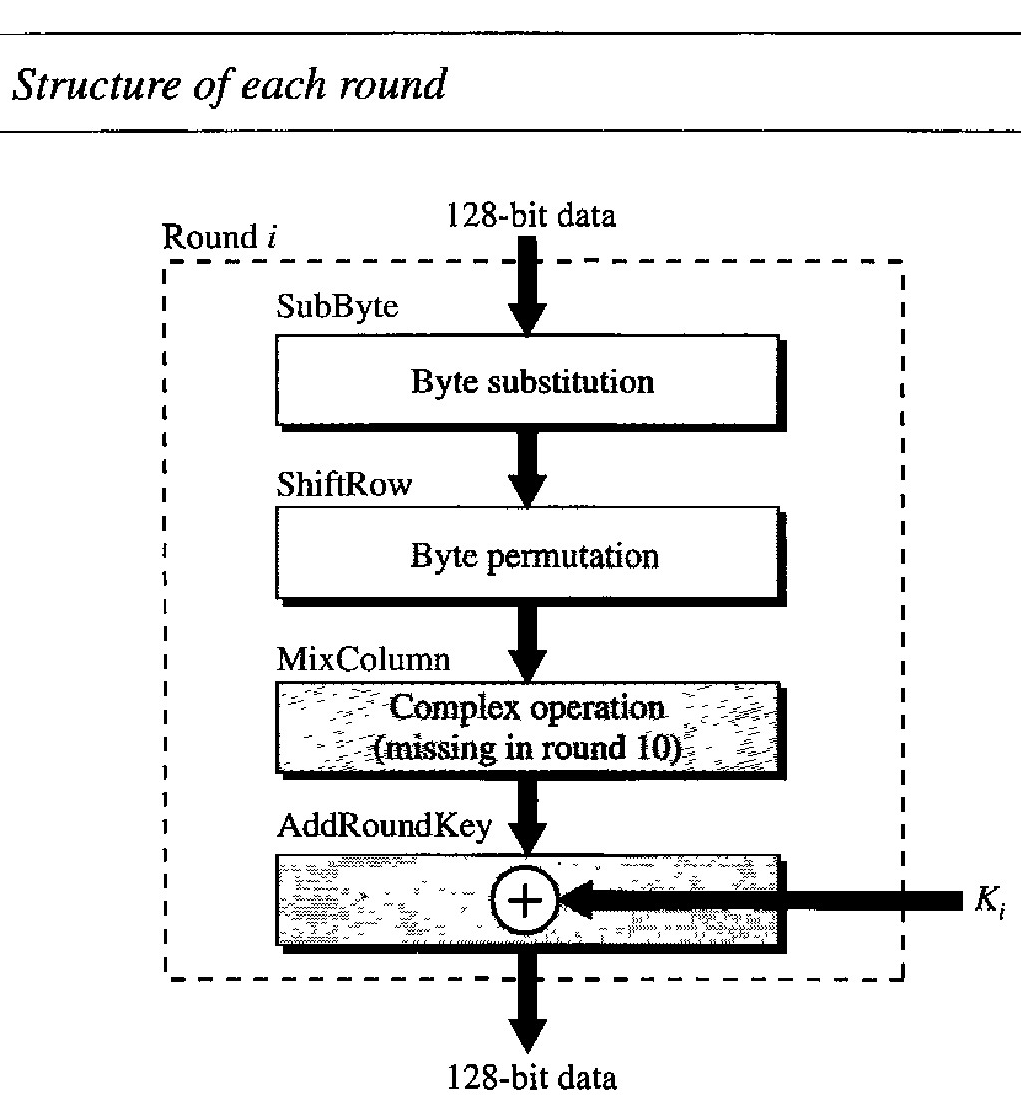
There is an initial XOR operation followed by 10 round ciphers. The last round is slightly different from the preceding rounds; it is missing one operation. Although the 10 iteration blocks are almost identical, each uses a different key derived from the original key.
Each round of AES, except for the last, is a cipher with four operations that are invertible. The last round has only three operations. Figure below is a flowchart that shows the operations in each round. Each of the four operations used in each round uses a complex cipher;
Mode of Operation
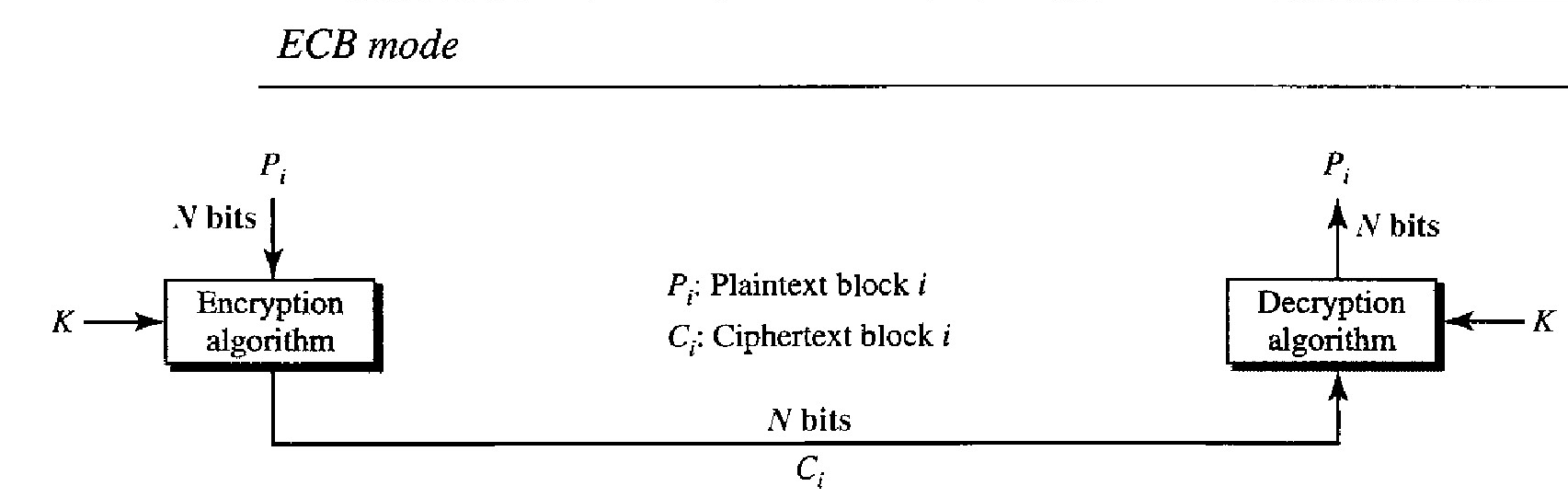
The electronic code book (ECB) mode is a purely block cipher technique. The plain- text is divided into blocks of N bits. The ciphertext is made of blocks of N bits. The value of N depends on the type of cipher used.
Because the key and the encryption/decryption algorithm are the same, equal blocks in the plaintext become equal blocks in the ciphertext. For example, if plaintext blocks 1, 5, and 9 are the same, ciphertext blocks 1, 5, and 9 are also the same.
This can be a security problem; the adversary can guess that the plaintext blocks are the same if the corresponding ciphertext blocks are the same.
If we reorder the plaintext block, the ciphertext is also reordered.
Blocks are independent of each other. Each block is encrypted or decrypted inde- pendently. A problem in encryption or decryption of a block does not affect other blocks.
An error in one block is not propagated to other blocks. If one or more bits are corrupted during transmission, it only affects the bits in the corresponding plaintext after decryption.
Other plaintext blocks are not affected. This is a real advantage if the channel is not noise-free.
Cipher Block Chaining
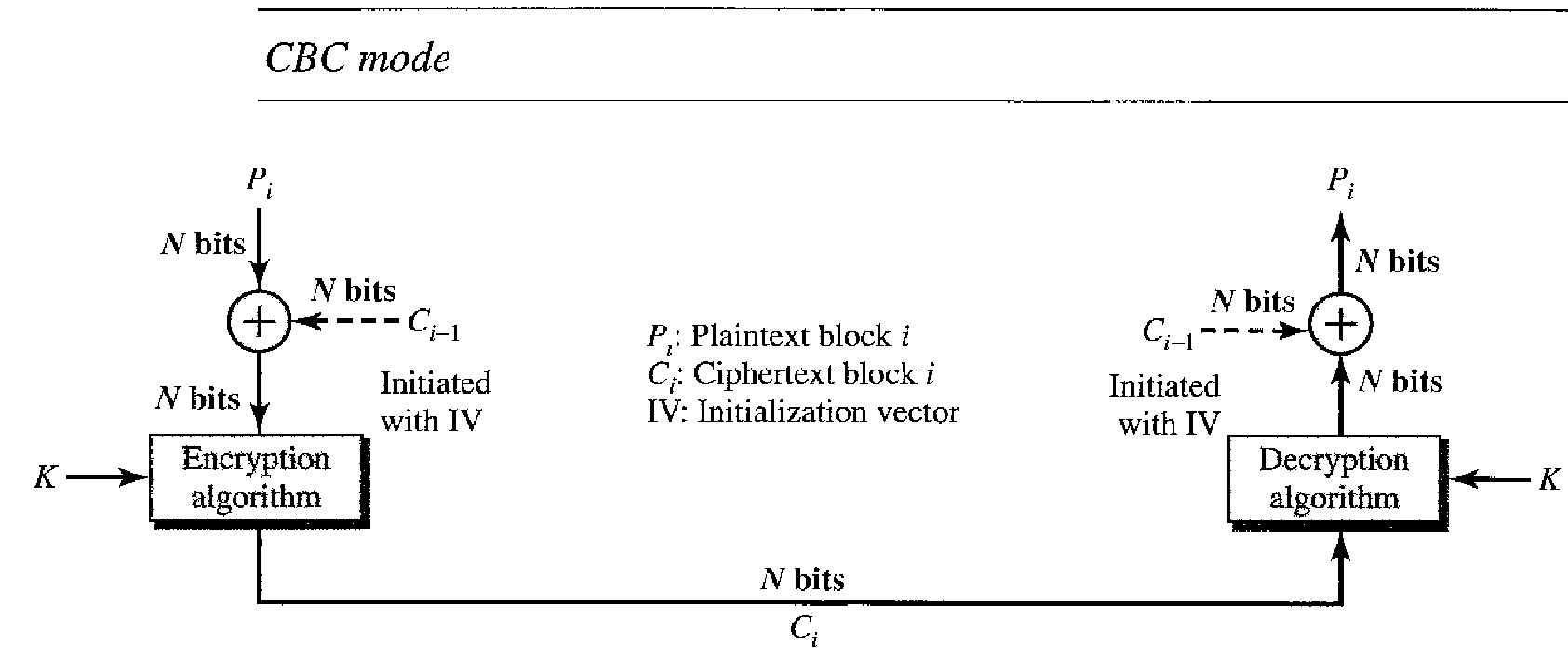
The cipher block chaining (CBC) mode tries to alleviate some of the problems in ECB by including the previous cipher block in the preparation of the current block.
If the current block is i, the previous ciphertext block Ci-1 is included in the encryption of block i.
In other words, when a block is completely enciphered, the block is sent, but a copy of it is kept in a register (a place where data can be held) to be used in the encryption of the next block.
The reader may wonder about the initial block. There is no ciphertext block before the first block.
In this case, a phony block called the initiation vector (IV) is used.
Both the sender and receiver agree upon a specific predetermined IV. In other words, the IV is used instead of the nonexistent C0.
The following are some characteristics of CBC.
1. Even though the key and the encryption/decryption algorithm are the same, equal blocks in the plaintext do not become equal blocks in the ciphertext. For example, if plaintext blocks 1,5, and 9 are the same, ciphertext blocks 1,5, and 9 will not be the same. An adversary will not be able to guess from the ciphertext that two blocks are the same.
2. Blocks are dependent on each other. Each block is encrypted or decrypted based on a previous block. A problem in encryption or decryption of a block affects other blocks.
3. The error in one block is propagated to the other blocks. If one or more bits are corrupted during the transmission, it affects the bits in the next blocks of the plaintext after decryption.
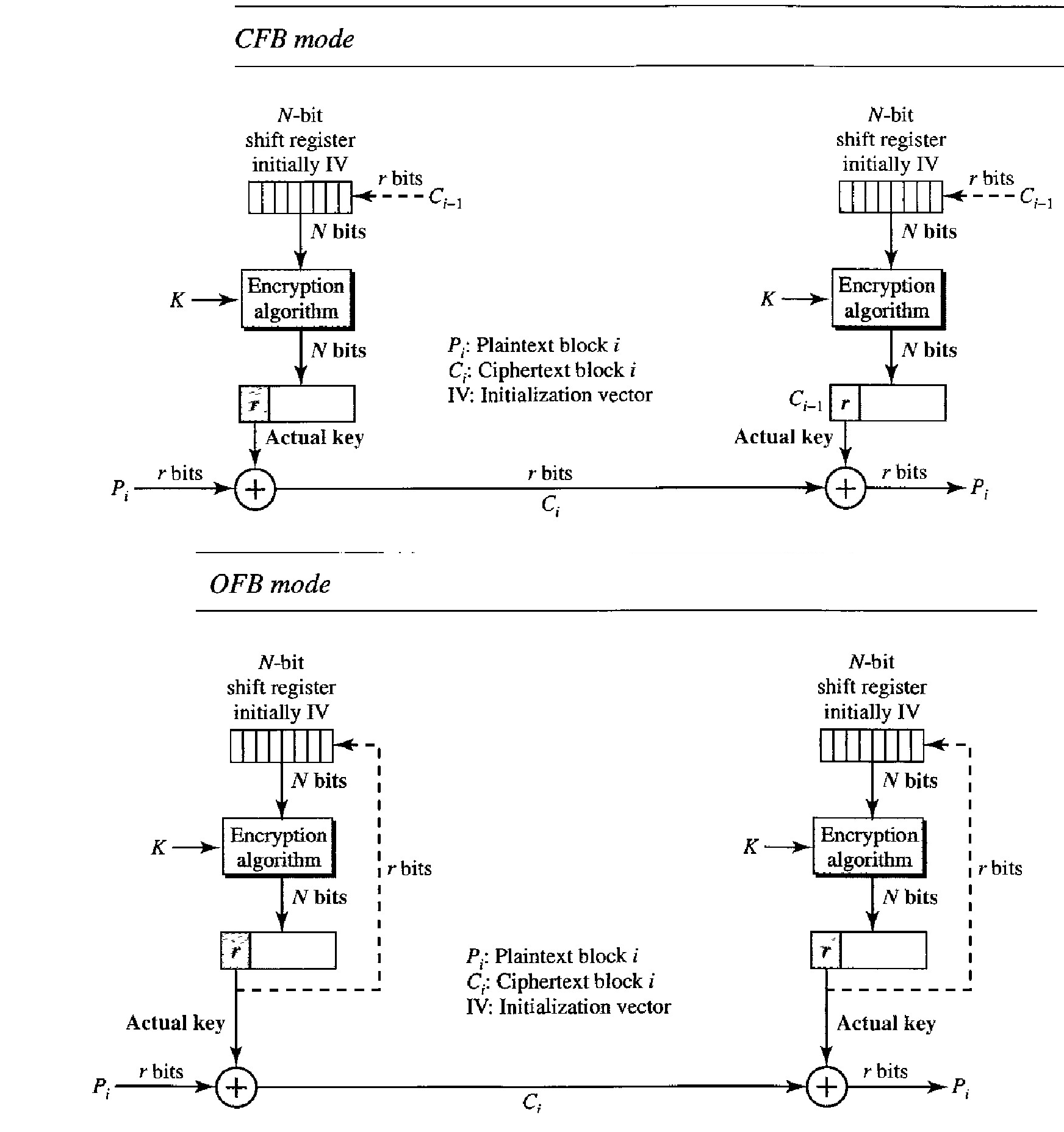
Cipher Feedback
The cipher feedback (CFB) mode was created for those situations in which we need to send or receive r bits of data, where r is a number different from the underlying block size of the encryption cipher used.
The value of r can be 1, 4, 8, or any number of bits.
Since all block ciphers work on a block of data at a time, the problem is how to encrypt just r bits.
The solution is to let the cipher encrypt a block of bits and use only the first r bits as a new key (stream key) to encrypt the r bits of user data. Figure below shows the configuration.
The following are some characteristics of the CFB mode:
1. If we change the IV from one encryption to another using the same plaintext, the ciphertext is different.
2. The ciphertext C, depends on both Pi and the preceding ciphertext block.
3. Errors in one or more bits of the ciphertext block affect the next ciphertext blocks.
Output Feedback
The output feedback (OFB) mode is very similar to the CFB mode with one difference.
Each bit in the ciphertext is independent of the previous bit or bits. This avoids error propagation.
If an error occurs in transmission, it does not affect the future bits.
Note that, as in CFB, both the sender and the receiver use the encryption algorithm.
Note also that in OFB, block ciphers such as DES or AES can only be used to create the key stream.
The feedback for creating the next bit stream comes from the previous bits of the key stream instead of the ciphertext. The ciphertext does not take part in creating the key stream. Figure below shows the OFB mode.
The following are some of the characteristics of the OFB mode.
1. If we change the IV from one encryption to another using the same plaintext, the ciphertext will be different.
2. The ciphertext C, depends on the plaintext Pi'
3. Errors in one or more bits of the ciphertext do not affect future ciphertext blocks.