NONREGULAR LANGUAGES
A language that cannot be defined by a regular expression is called a nonregular language.
By Kleene's theorem, a nonregular language can also not be accepted by any FA or TG. All languages are either regular or nonregular, none are both.
Let us first consider a simple case. Let us define the language L. L = {Λ ab aabb aaabbb aaaabbbb aaaaabbbbb ...}
We could also define this language by the formula L = {anbn for n = 0 1 2 3 4 5 ... } or for short L = {anbn}
We shall now show that this language is nonregular. Let us note, though, that it is a subset of many regular languages, such as a*b*, which, however, also includes such strings as aab and bb that {anbn} does not.
Let us be very careful to note that {anbn} is not a regular expression. It involves the symbols { } and n that are not in the alphabet of regular expressions. This is a language-defining expression that is not regular.
Suppose on the contrary that this language were regular. Then there would have to exist some FA that accepts it.
This FA might have many states. Let us say that it has 95 states, just for the sake of argument. Yet we know it accepts the word a96b96
The first 96 letters of this input string are all a's and they trace a path through this machine. The path cannot visit a new state with each input letter read because there are only 95 states.
Therefore, at some point the path returns to a state that it has already visited. The first time it was in that state it left by the a-road.
The second time it is in that state it leaves by the a-road again. Even if it only returns once we say that the path contains a circuit in it.
(A circuit is a loop that can be made of several edges.) First the path wanders up to the circuit and then it starts to loop around the circuit, maybe many times. It cannot leave the circuit until a b is read in.
Then the path can take a different turn. In this hypothetical example the path could make 30 loops around a three-state circuit before the first b is read.
After the first b is read, the path goes off and does some other stuff following b edges and eventually winds up at a final state where the word a96b96 is accepted.
Let us, for the sake of argument again, say that the circuit that the a-edge path loops 'around has seven states in it. The path enters the circuit, loops around it madly and then goes off on the b-line to a final state.
What would happen to the input string a96 + 7b96 ?
Just as in the case of the input string a96b96 , this string would produce a path through the machine that would walk up to the same circuit (reading in only a's) and begin to loop around it in exactly the same way.
However, the path for a96 + 7b96 loops around this circuit one more time than the path for a96b96--precisely one extra time.
Both paths, at exactly the same state in the circuit, begin to branch off on the b-road.
Once on the b-road, they both go the same 96 b-steps and arrive at the same final state. But this would mean that the input string a103b96 is accepted by this machine. But that string is not in the language L = {anbn}.
This is a contradiction. We assumed that we were talking about an FA that accepts exactly the words in L and then we were able to prove that the same machine accepts some word that is not in L.
This contradiction means that the machine that accepts exactly the words in L does not exist. In other words, L is nonregular.
We chose a word in L that was so large (had so many letters) that its path through the FA had to contain a circuit.
Once we found that some path with a circuit could reach a final state, we asked ourselves what happens to a path that is just like the first one, but that loops around the circuit one extra time and then proceeds identically through the machine.
The new path also leads to the same final state, but it is generated by a different input string-an input string not in the language L.
When the range of the abstract exponent n is unspecified we mean to imply that it is 0,1,2,3, ...
Pumping Lemma
Let the path for a9b9 be:
Here we have shown only those edges needed in the word a9b9. State 6 is the only state that sees both an a-exit and a b-exit edge. In the path this input string takes to acceptance we find two circuits.
The a-circuit 3-4-5-6 and the b-circuit 9-10. Let us concentrate on the a-circuit. What would be the path through this FA of the input string a13b9?
The path for a13b9 would begin with the same nine steps as the path for a9b9 ending after nine steps in state 6. The input string a9b9 now gives us a b to read, which makes us go to state 7.
However, the path for a13b9 still has four more a-steps to take, which is one more time around the circuit, and then it follows the nine b-steps. The path for a13b9 is shown below:
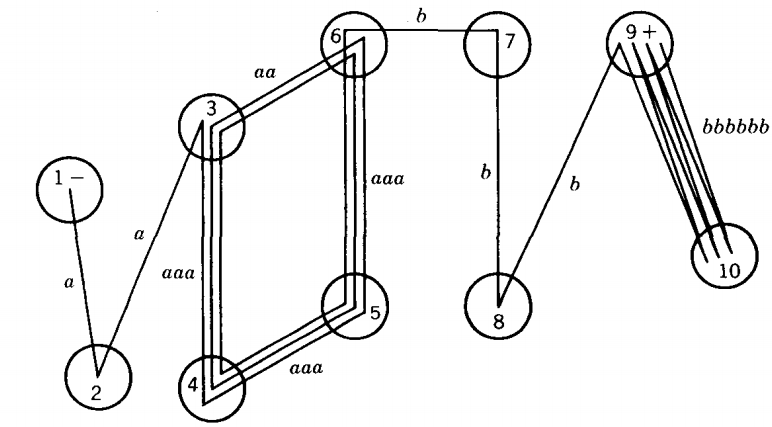
Let us return to our first consideration. With the assumptions we made above (that there were 95 states and that the circuit was 7 states long), we could also say that a110b96 , a117b96 .. are also accepted by this machine.
They can all be written in this form a96(a7)mb96 where m is any integer 0,1,2,3 .....
If m is 0 the path through this machine is the path for the word a96b96 . If m is 1, that looks the same, but it loops the circuit one more time. If m = 2, the path loops the circuit two more times. in general, a96(a7)mb96 loops the circuit exactly m more times.
After doing this looping it gets off the circuit at exactly the same place a96b96 does and proceeds along exactly the same route to the final state. All these words, though not in L, must be accepted.
All in all, we can definitely conclude that there is no FA that accepts all the strings in L and only the strings in L. Therefore L is nonregular.
The principle we have been using to discuss the language L above can be generalized so that it applies to consideration of other languages. It is a tool that enables us to prove that certain other languages are also nonregular.
The generalization of this idea is called the Pumping Lemma for regular languages
DECIDABILITY
In this topic the following questions shall be answered
How can we tell if two regular expressions define the same language?
How can we tell if two FA's are equivalent?
How can we tell if the language defined by an FA has finitely many or infinitely many words in it?
In mathematical logic we say that a problem is effectively solvable if there is an algorithm that provides the answer in a finite number of steps, no matter what the particular inputs are. The maximum number of steps the algorithm will take must be predictable before we begin to execute the procedure.
An effective solution to a problem that has a yes or no answer is called a decision procedure. A problem that has a decision procedure is called decidable.
We want to decide whether two regular expressions determine the exact same language. We might, very simply, use the two expressions to generate many words from each language until we find one that obviously is not in the language of the other.
a(a + b)* and (b + Λ)(baa + ba*)*.
It is obvious that all the words in the language represented by the first expression begin with the letter a and all the words in the language represented by the second expression begin with the letter b.
These expressions have no word in common; and this fact is very clear. However, consider these two expressions: (aa + ab + ba + bb)* and ((ba + ab)*(aa + bb)*)*
They both define the language of all strings over Σ = {a, b} with an even number of letters, but its impossible to know they are equivalent. The following two expressions are even less clear:
((b*a)*ab*)* and Λ +a(a + b)* + (a + b)*aa(a + b)*
They both define the language of all words that either start with an a or else have a double a in them somewhere or else are null.
Steps : To decide whether two regular expressions determine the exact same language
Given two languages L1 and L2 defined either by regular expressions or by FA's, we have developed the procedures necessary to produce finite automata for the languages L1', L2', L1 ∩ L2', and L2 ∩ L1 '. Th
erefore, we can produce an FA that accepts the language (L1 ∩ L2') + (L2 ∩ L1')
This machine accepts the language of all words that are in L1 but not L2 or else in L2 but not L1. If L1 and L2 are the same language, this machine cannot accept any words.
If this machine accepts even one word, then L1 is not equal to L2; even if the one word is the null word. If L1 is equal to L2, then the machine for the language above accepts nothing at all.
To make this discussion into an effective decision procedure, we must show that we can tell by some algorithm when an FA accepts no words at all.
How to determine whether an FA accepts any words
Convert the FA into a regular expression. Every regular expression defines some words. We can prove this by an algorithm.
First delete all stars. Then for each + we throw away the right half of the sum and the + sign itself. When we have no more *'s or + 's, we remove the parentheses and we have a concatenation of a's, b's, and Λ's.
These taken together form a word. For example:
(a + Λ)(ab* + ba*)*(Λ + b*)*
becomes (after removing *'s) (a + Λ)(ab + ba) (Λ + b) which becomes (throwing away right halves)
(a)(ab)(Λ) which becomes (eliminating parentheses) a ab Λ
which is the word aab
This word must be in the language of the regular expression since the operations of choosing * = power 1, and + = left half, are both legal choices for forming words.
If every regular expression defines at least one word, it seems at first glance that this means that every FA must accept at least one word. How then could we ever show that two languages are equal?
If we first build an FA for the language (L1 ∩ L2') + (L2 ∩ L1')
and then when we convert this machine into a regular expression, is it not true that by the argument above we must find some word in the language of the regular expression and therefore L1 ≠ L2 no matter what they are? No.
The hole in this reasoning is that the process of converting this FA into a regular expression breaks down. We come down to the last step where we usually have several edges running from - to + that we add together to form the regular expression.
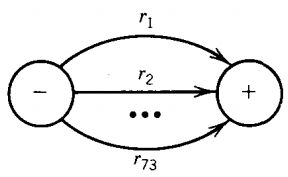
However, when we get to this last step we suddenly realize that there are no paths from - to + at all. This could happen theoretically in three different ways: the machine has no final states, such as this one:
or the final state is disconnected from the start state, as with this one:
or the final state is unreachable from the start state, as with this one:
We shall see later in this chapter which of these situations does arise if the languages are actually equal.
Method 2 : How to determine whether an FA accepts any words
Examine the FA to see if there is any path from - to +. If there is any path, then the machine must accept some words-for one, the word that is the concatenation of the labels of the edges in the path from - to + just discovered.
In a large FA with thousands of states and millions of directed edges, it may be impossible to decide if there is a path from - to + without the aid of an effective procedure. One such procedure is this:
Step 1 Paint the start state blue.
Step 2 From every blue state follow each edge that leads out of it and paint the connecting state blue, then delete this edge from the machine.
Step 3 Repeat Step 2 until no new state is painted blue, then stop.
Step 4 When the procedure has stopped, if any of the final states are painted blue, then the machine accepts some words and, if not, it does not. Let us look at this procedure at work on the machine
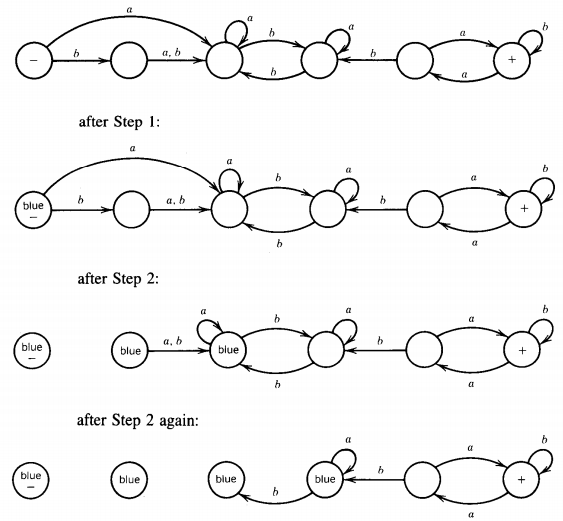
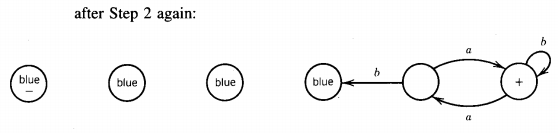
No new states were painted blue this time, so the procedure stops and no words. While we were examining the second method we might have noticed that Step 2 cannot be repeated more times than there are total states in the machine. If the machine has N states, after N iterations of Step 2 either they are all colored blue or we have already stopped.
Determine whether two regular expressions are equivalent
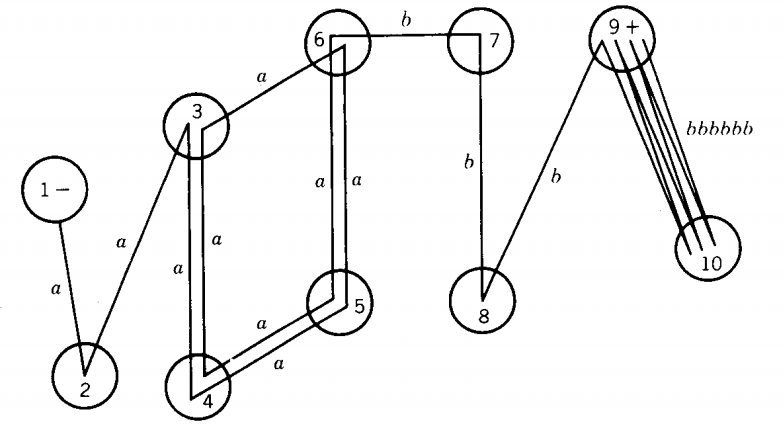
Let the two regular expressions be: r1 = a* and r2 = Λ + aa*
Luckily in this case we can understand that these two define the same language. Let us see how the decision procedure proves this.
Some machines for FA1, FA1', FA2, and FA2' are shown below:
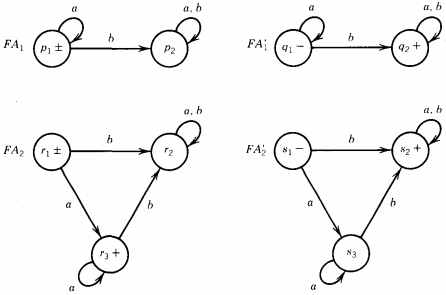
If we did not know how to produce these, algorithms in previous chapters would show us how. We have labeled the states with the letters p, q, r, and s for clarity. Instead of using the logical formula:
(L1 ∩ L2') + (L2 ∩ Ll')
we build our machine based on the equivalent Set Theory formula (L1' + L2)' + (L2' + L1)'
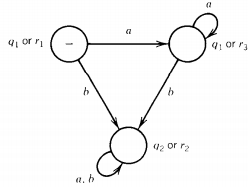
The machine for the first half of this formula is (FA1' + FA2)'
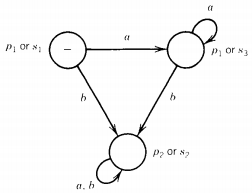
The machine for the second half is (FA2' + FA1)'
It was not an oversight that we failed to mark any of the states in these two machines with a +.
Neither machine has any final states. For (FA1' + FA2)' to have a final state, the machine (FA1' + FA2) must have a nonfinal state. The start state for this machine is (ql or r1).
From there, if we read an a we go to (ql or r3 ), and if we read instead a b we go to (q2 or r2). If we ever get to (q2 or r2) we must stay there. From (q1 or r3) an input b takes us to (q2 or r2) and an input a leaves us at (q1 or r3).
All in all, from - we cannot get to any other combination of states, such as the potential (q2 or r1) or (q1 or r2).
Now since q2 is a + and r, and r3 are both +, all three states (q1 or r1), (q1 or r3 ), and (q2 or r2) are all +, which means that the complement has no final states.
The exact same thing is true for the machine for the second half of the formula. Clearly, if we added these two machines together we would get a machine with nine states and no final state.
Since it has no final state, it accepts no words and the two languages L1 and L2 are equivalent. This ends the decision procedure.
There are no words in one language that are not in the other, so the two regular expressions define the same language and are equivalent.
This example is a paradigm for the general situation. The machine for (L1' + L2)' accepts only those words in L1 but not in L2.
If the languages are in fact equal, this machine will have no final states. The same will be true for the machine for (L2' + L1)'.
It will never be necessary to combine these two machines, since if either accepts a word, then L1 ≠ L2. When we listed three ways that a machine could accept no words the first way was that there be no final states and the second and third ways were that the final states not be reachable from the start state.
We counted these situations separately. When we form a machine by adding two machines together, we do not usually bother describing the states that are not reachable from the start state.
The algorithm that we described previously never gets to consider combinations of states of the component machines that are never referred to.
However, if we used a different algorithm, based on writing down the whole table of possible combinations and then drawing edges between the resultant states as indicated, we would, in this example, produce a picture with a final state but it would be unreachable from the start state.
In the example above, the full machine for (FA1 ' + FA2)' is this:
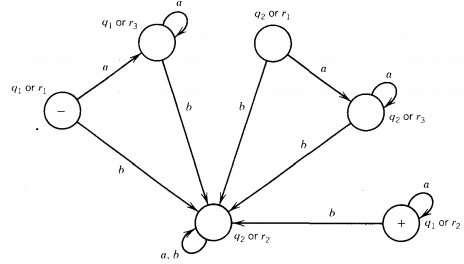
The only final state, (q1 or r2), cannot be reached from anywhere (in particular not from the start state (q1 or r1). So the machine accepts no words.
Determine whether an FA, or regular expression, accepts a finite language or an infinite language?
With regular expressions this is easy. The closure of any nonempty set, whether finite or infinite, is itself infinite.
Even the closure of one letter is infinite.
Therefore, if when building the regular expression from the recursive definition we have ever had to use the closure operator, the resulting language is infinite.
This can be determined by scanning the expression itself to see whether it contains the symbol *.
If the regular expression does contain a*, then the language is infinite.
The one exception to this rule is Λ*, which is just Λ.
This one exception can however be very tricky. Of the two regular expressions: (Λ + a Λ*) (Λ* + Λ)* and (Λ + aΛ)* (Λ* + Λ)*
only the second defines an infinite language. If the regular expression does not contain a*, then the language is necessarily finite. This is because the other rules of building regular expressions (any letter, sum, and product) cannot produce an infinite set from finite ones.
Therefore, as we could prove recursively, the result must be finite.
If we want to decide this question for an FA, we could first convert it to a regular expression.
On the other hand, there are ways to determine whether an FA accepts an infinite language without having to perform the conversion
THEOREM - PROOF
Let F be an FA with N states. Then
(i) If F accepts an input string w such that : N ≤ length (w) < 2N then F accepts an infinite language.
(ii) If F accepts infinitely many words, than F accepts some word w such that N ≤ length (w) < 2NIf there is some word w with N or more letters, then by the second version of the Pumping Lemma, we can break it into three parts: w = xyz The infinitely many different words x yn z for n = 1, 2, 3 . . . are all accepted by F.
Now we are supposing that F does accept infinitely many words. Then it must accept a word so large that its path must contain a circuit, maybe several circuits.
Each circuit can contain at most N states because F has only N states in total.
Let us change the path of this long word by keeping the first circuit we come to and bypassing all the others.
To bypass a circuit means to come up to it, go no more than part way around it, and leave at the first occurrence of the state from which the path previously exited.
This one-circuit path corresponds to some word accepted by F. The word can have at most 2N letters, since at most N states are on the one circuit and at most N states are encountered off that circuit.
If the length of this word is more than N, then we have found a word whose length is in the range that the theorem specifies.
If, on the other hand, the length of this word is less than N, we can increase it by looping around the one circuit until the length is greater than N.
The first time the length of the word (and path) becomes greater than N, it is still less than 2N, since we have increased the word only by the length of the circuit, which is less than N.
Eventually, we come to an accepted word with a length in the proper range.
Example
Consider this example:
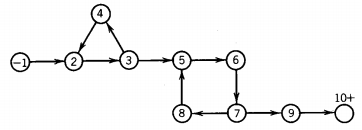
The first circuit is 2-3-4. It stays. The second circuit is 5-6-7-8. It is bypassed to become 5-6-7-9.
The path that used to be 1-2-3-4-2-3-5-6-7-8-5-6-7-8-5-6-7-9-10 becomes 1-2-3-4-2-3-5-6-7-9-10
This demonstrates the existence of a simple one-circuit path in any FA that accepts infinitely many words.
This theorem provides us with an effective procedure for determining whether F accepts a finite language or an infinite language.
We simply test the finitely many strings with lengths between N and 2N by running them on the machine and seeing if any reach a final state.
If none does, the language is finite. Otherwise it is infinite.
THEOREM : There is an effective procedure to decide whether a given FA accepts a finite or an infinite language
If the machine has N states and the alphabet has m letters, then in total there are \( m^N + m^{N+1} + m^{N+1} + .... + m^{2N-1} \) different input strings in the range N ≤ length of string < 2N.
We can test them all by running them on the machine. If any are accepted, the language is infinite. If none are accepted, the language is finite.
It may often be more efficient to convert the FA to a regular expression.
However, suppose the FA is an actual physical machine that is sitting in front of us. We may not know its exact structure inside or it may be extremely complicated.
Even though we have an effective procedure for converting it into a regular expression, we may not have the capacity (storage or time or inclination) to do so.
Yet there might be an automatic way of feeding in all combinations of letters in the interesting range.
Even if this situation never arises, the theorem we have covered is a prototype for decidability of more complex questions.
In the case where the machine has 3 states and the alphabet has 2 letters, the number of strings we have to test is 23 + 24 + 25 = 8 + 16 + 32 = 56
which is not too bad. However, an FA with 3 states can be converted into a regular expression in very few steps.