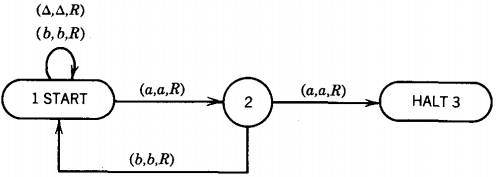
THEOREM : Every regular language has a TM that accepts exactly it.
Consider any regular language L. Take an FA that accepts L. Change the edge labels a and b to (a,a,R) and (b,b,R), respectively.
Change the - state to the word START. Erase the plus sign out of each final state and instead add to each of these an edge labeled (△,△,R) leading to a HALT state.
Hence we have a TM. We read the input string moving from state to state in the TM exactly as we would on the FA.
When we come to the end of the input string, if we are not in a TM state corresponding to a final state in the FA, we crash when the TAPE HEAD reads the △ in the next cell.
If the TM state corresponds to an FA final state, we take the edge labeled (△,△,R) to HALT. The acceptable strings are the same for the TM and the FA.
EXAMPLE
We shall now design a TM that accepts the language EQUAL, that is, the language of all strings with the same number of a's and b's.
EQUAL is a nonregular language, so the trick of Theorem 45 cannot be employed. Since we want to scan up and down the input string, we need a method of guaranteeing that on our way down we can find the beginning of the string without crashing through the left wall of cell i.
One way of being safe i- to insert a new symbol, #, at the beginning of the input TAPE in cell i to the left of the input string. This means we have to shift the input string one cell to the right without changing it in any way except for its location on the TAPE.
This problem arises so often that we shall write a program segment to achieve this that will be used in the future as a standard preprocessor or subroutine called INSERT #.
Over the alphabet Σ = {a,b} we need only 5 states.
State 1 START
State 2 We have just read an a.
State 3 We have just read a b.
State 4 We have just read a △.
State 5 Return to the beginning. This means leave the TAPE HEAD reading cell ii.
The first part of the TM is this:
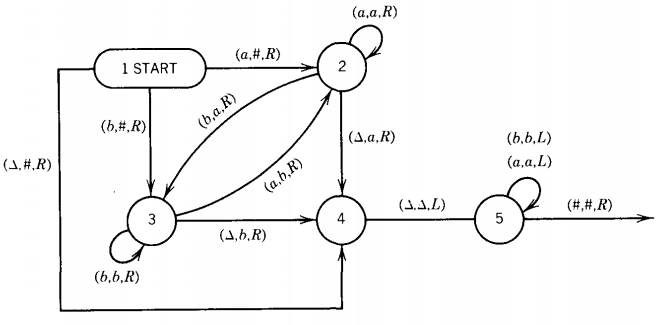
We start out in state 1. If we read an a, we go to state 2 and replace the a in cell i with the beginning-of-TAPE symbol #. Once we are in state 2, we know we owe the TAPE an a, so whatever we read next we print the a and go to a state that remembers whatever symbol was just read.
There are two possibilities. If we read another a, we print the prior a and still owe an a, so we stay in state 2. If we read a b, we print the a we owed and move to state 3, owing the TAPE a b.
Whenever we are in state 3 we read the next letter, and as we go to a new state we print the old b we already read but do not yet print the new letter. The state we go to now must remember what the new letter was and print it only after reading yet another letter. We are always paying last month's bill. We are never up to date until we read a blank. This lets us print the last a or b and takes us to state 4.
Eventually, we get to state 5. In state 5 we rewind the TAPE HEAD moving backward to the #, and then we leave ourselves in cell ii. There we are reading the first letter of the input string and ready to connect the edge from state 5 into the START state of some second process.
The problem we have encountered and solved is analogous to the problem of shifting a field of data one storage location up the TAPE. Writing-over causes erasing, so a temporary storage location is required. In this case, the information is stored in the program by the identity of the state we are in. Being in state 2, 3, or 4 tells us what we have just read.
Variations of this subroutine can be written to
Insert any other character into cell i while moving the data to the right.
Insert any character into any specified cell leaving everything to the left as it is and moving the entire TAPE contents on the right one cell down the TAPE.
Insert any character into any cell, on a TAPE with input strings from any alphabet.
Let us illustrate the operation of INSERT # on the input string abba:
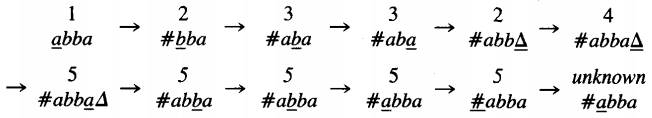
The last state is "unknown" because we are in whatever state we got to on our departure from state 5. We cannot specify it in general because INSERT # will be used in many different programs. Here "unknown" will be called state 6.
We can now begin the algorithm of pairing off a's and b's. The method we use is to X out an a and then X out a b and repeat this until nothing at all is left. There are many good ways to accept EQUAL; the one we shall use is not the most efficient, but Turing machines run on imagination, which is cheaper than petroleum.
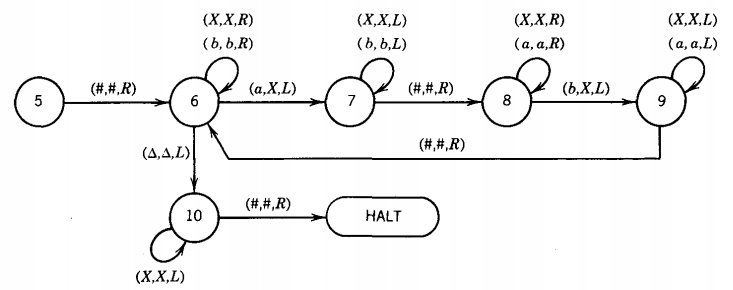
In state 6 we start at the left of the input string and scan upward for the first a. When we find it, we change it to an X and move to state 7. This state returns the TAPE HEAD to cell ii by backing up until it bumps off the symbol #. Now we scan upward looking for the first unchanged b.
If we hit the end of the word before we find the matching b, we read a △ and crash because the input string has more a's than b's. If we do find an unused b, then in state 8 we change it to an X.
In state 9 we return the TAPE HEAD to cell ii and state 6 to repeat the whole process. If, in state 6, while searching for the first unused a we find there are no more left (by encountering a △), we go to state 10. State 10 begins at the end of the string and rewinds us to cell ii reading only X's.
If it encounters any unused b's, it crashes. In that case we have cancelled all the a's but not all the b's, so the input must have had more b's than a's. If the TAPE HEAD can get all the way back to # reading only X's, then every letter in the input string has been converted to X and the machine accepts the string
Let us follow the operation on baab starting in state 6. Starting in state 6 means that we have already inserted a # to the left of the input on the TAPE in states 1 through 5.
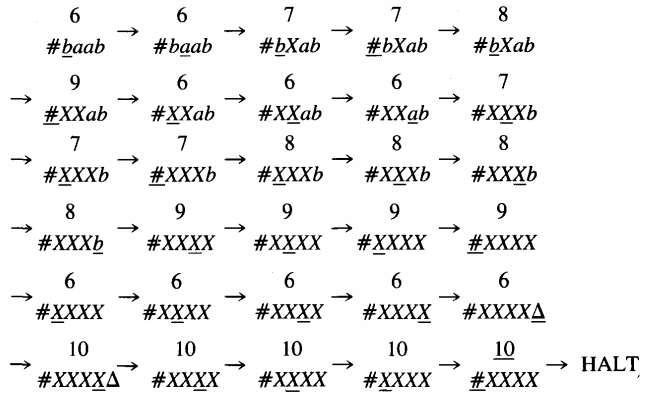
EXAMPLE
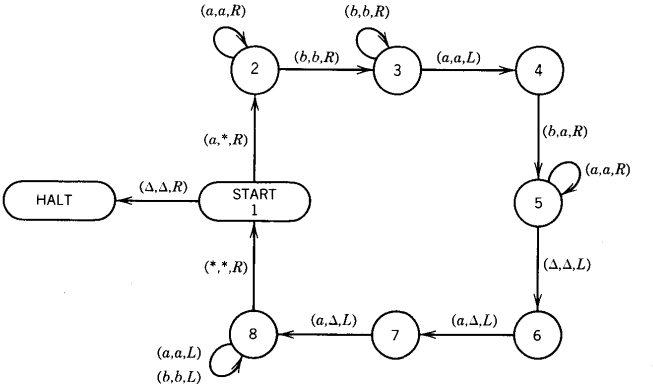
Now we shall consider a valid but problematic machine to accept the language of all strings that have a double a in them somewhere:
The problem is that we have labeled the loop at the start state with the extra option (△,△,R).
This is still a perfectly valid TM because it fits all the clauses in the definition.
Any string without a double a that ends in the letter a will get to state 2, where the TAPE HEAD will read a △ and crash.
What happens to strings without a double a that end in b? When the- last letter of the input string has been read, we are in state 1.
We read the first △ and return to state 1, moving the TAPE HEAD further up the TAPE full of △'s.
In fact, we loop forever in state 1 on the edge labeled (△,△,R). All the strings in {a,b}* can be divided into three sets:
Those with a double a. They are accepted by the TM.
Those without aa that end in a. They crash.
Those without aa that end in b. They loop forever.
DEFINITION
Every Turing machine T over the alphabet I divides the set of strings '* into three classes:
ACCEPT(T) is the set of all strings leading to a HALT state. This is also called the language accepted by T.
REJECT(T) is the set of all strings that crash during execution by moving left from cell i or by being in a state that has no exit edge that wants to read the character the TAPE HEAD is reading.
LOOP(T) is the set of all other strings, that is, strings that loop forever while running on T.
EXAMPLE
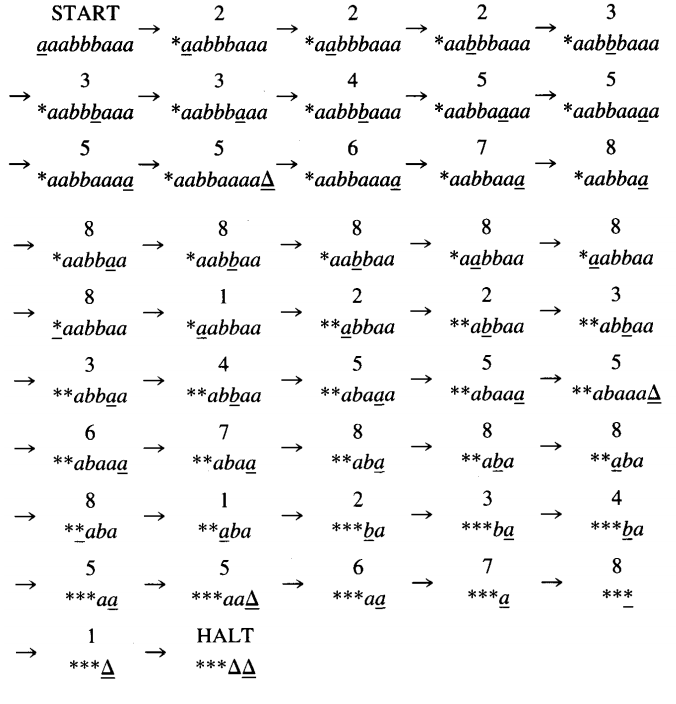
Let us consider the non-context-free language {anbnan}. This language can be accepted by the following interesting procedure:
Step I We presume that we are reading the first letter of what remains on the input.
Initially this means we are reading the first letter of the input string, but as the algorithm progresses we may find ourselves back in this step reading the first letter of a smaller remainder. If no letters are found (a blank is read), we go to HALT.
If what we read is an a, we change it to a * and move the TAPE HEAD right. If we read anything else, we crash. This is all done in state 1.
Step 2 In state 2 we skip over the rest of the a's in the initial clump of a's looking for the first b. This will put us in state 3.
Here we search for the last b in the clump of b's: We read b's continually until we encounter the first a (which takes us to state 4) and then bounce off that a to the left. If after the b's we find a △ instead of an a, we crash.
Now that we have located the last b in the clump we do something clever: We change it into an a, and we move on to state 5. The reason it took so many TM states to do this simple job is that if we allowed, say, state 2 to skip over b's as well as a's, it would merrily skip its way to the end of the input.
We need a separate TM state to keep track of where we are in the data. Step 3 The first thing we want to do here is find the end of the clump of a's (this is the second clump of a's in the input). We do this in state 5 by reading right until we get to a △.
If we read a b after this second clump of a's, we crash. If we get to the △ we know that the input is in fact of the form a*b*a*. When we have located the end of this clump we turn the last two a's into △'s.
Because we changed the last b into an a this is tantamount to killing off a b and an a. If we had turned that b into a △, it would have meant △'s in the middle of the input string and we would have had trouble telling where the real ends of the string were.
Instead, we turned a b into an a and then erased two a's off the end. Step 4 We are now in state 8 and we want to return to state 1 and do this whole thing again. Nothing could be easier.
We skip over a's and b's, moving the TAPE HEAD left until we encounter one of the *'s that fill the front end of the TAPE. Then we move one cell to the right and begin again in state 1.
The TM looks like this:
After designing the machine and following the trace several things should be obvious to us:
The only words accepted are of the form anbnan (here n = 0,1,2,3 . . . )
When the machine halts, the TAPE will hold as many *'s as there were b's in the input.
If the input was ambmam, the TAPE HEAD will be in cell (m + 2) when the machine halts.
EXAMPLE
In building the TM for EQUAL, we developed a TM subroutine that can insert a character in front of an input string on a TM TAPE.
We mentioned that a slight modification allows us to use this routine to insert any new character at any point in a TM TAPE and shift the rest of the input one cell to the right.
Let us consider how to do this. We start with some arbitrary string on the TAPE. Let us just say for the purpose of example that what is on the TAPE is a string of a's, b's, and X's with △'s after it.
Suppose further that the TAPE HEAD is pointing to the very cell in the middle of the string where we want to insert a new character, let us say a b. We want everything to the right of this spot moved one cell up the TAPE.
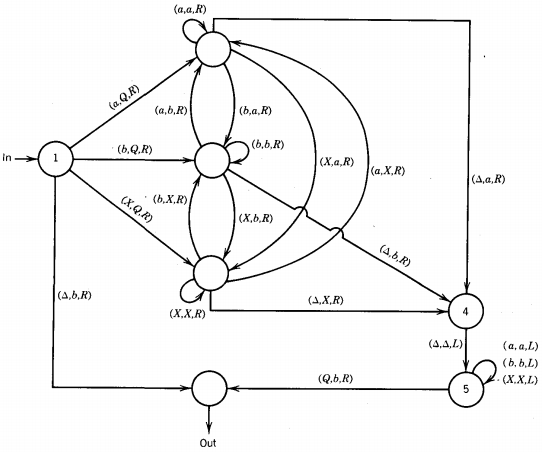
What we need is a symbol unlike any that is on the TAPE now, say Q. The following TM subroutine will accomplish this job:
-
Notice that we leave the TAPE HEAD reading the next cell after the cell where the insertion occurred.
EXAMPLE
For our last example we shall build a TM subprogram that deletes, that is, it erases the contents of the cell the TAPE HEAD is initially pointing to, moving the contents of each of the nonempty cells to its right down one cell to the left to close up the gap and leaving the TAPE HEAD positioned one cell past where it was at the start.
For example:
Just as with INSERT, the exact program of DELETE depends on the alphabet of letters found on the TAPE.
Let us suppose the characters on the TAPE are from the alphabet {a,b,c} One subroutine to do this job is shown on the next page.
What we have done here is (1) erased the target cell, (2) moved to the right end of the non-A data, (3) worked our way back down the TAPE running the inverse of INSERT.
We could just as easily have done the job on one pass up the TAPE, but then the TAPE HEAD would have been left at the end of the data and we would have lost our place;
there would be no memory of where the deleted character used to be. The way we have written it, the TAPE HEAD is left in the cell immediately after the deletion cell.