Introduction to Database Systems
A database-management system (DBMS) is a collection of interrelated data and a set of programs to access those data.
The collection of data, usually referred to as the database, contains information relevant to an enterprise. The primary goal of a DBMS is to provide a way to store and retrieve database information that is both convenient and efficient.
Management of data involves both defining structures for storage of information and providing mechanisms for the manipulation of information
The database system must ensure the safety of the information stored, despite system crashes or attempts at unauthorized access. If data are to be shared among several users, the system must avoid possible anomalous results.
Purpose of Database Systems
File-processing system have certain disadvantages:
Data redundancy and inconsistency:
The same information may be duplicated in several places (files).
Various files are likely to have different structures and the programs may be written in several programming languages.
This redundancy leads to higher storage and access cost. In addition, it may lead to data inconsistency where the various copies of the same data may no longer agree.
Difficulty in accessing data
Conventional file-processing environments do not allow needed data to be retrieved in a convenient and efficient manner.
Responsive data-retrieval systems are needed as requirements change and these changes have to be factored in.
Data isolation:
Data are scattered in various files, and files may be in different formats, writing new application programs to retrieve the appropriate data is difficult.
Integrity problems:
The data values stored in the database must satisfy certain types of consistency constraints.
Developers enforce these constraints in the system by adding appropriate code in the various application programs. However, when new constraints are added, it is difficult to change the programs to enforce them.
The problem is compounded when constraints involve several data items from different files.
Atomicity problems :
It is crucial that, if a failure occurs, the data be restored to the consistent state that existed prior to the failure.
Example, Consider a program to transfer $500 from the account balance of department A to the account balance of department B. If a system failure occurs during the execution of the program, it is possible that the $500 was removed from the balance of department A but was not credited to the balance of department B, resulting in an inconsistent database state.
Clearly, it is essential to database consistency that either both the credit and debit occur, or that neither occur.
That is, the funds transfer must be atomic - it must happen in its entirety or not at all. It is difficult to ensure atomicity in a conventional file-processing system.
Concurrent-access anomalies :
To allow faster response many systems allow multiple users to update the data simultaneously
Problems with allowing concurrent access is to allow multiple users to read and write data from a single account.
This causes inconsistency and may leave database in an invalid state.
Example, Consider department A, with an account balance of $10,000. If two department clerks debit the account balance (by say $500 and $100, respectively) of department A at almost exactly the same time, the result of the concurrent executions may leave the budget in an incorrect (or inconsistent) state.
Suppose that the programs executing on behalf of each withdrawal read the old balance, reduce that value by the amount being withdrawn, and write the result back. If the two programs run concurrently, they may both read the value $10,000, and write back $9500 and $9900, respectively. Depending on which one writes the value last, the account balance of department A may contain either $9500 or $9900, rather than the correct value of $9400.
Security problems :
Not every user of the database system should be able to access all the data.
But, since application programs are added to the file-processing system in an ad-hoc manner, enforcing such security constraints is difficult.
View of Data
A database system is a collection of interrelated data and a set of programs that allow users to access and modify these data.
Data Abstraction: A major purpose of a database system is to provide users with an abstract view of the data. That is, the system hides certain details of how the data are stored and maintained.
Physical level:
The lowest level of abstraction describes how the data are actually stored.
The physical level describes complex low-level data structures in detail
Logical level:
Describes what data are stored in the database, and what relationships exist among those data.
The logical level thus describes the entire database in terms of a small number of relatively simple structures.
Although implementation of the simple structures at the logical level may involve complex physical-level structures, the user of the logical level does not need to be aware of this complexity. This is referred to as physical data independence.
Database administrators, who must decide what information to keep in the database, use the logical level of abstraction
View level:
Describes only part of the entire database
Many users of the database system do not need all this information; instead, they need to access only a part of the database.
The view level of abstraction exists to simplify their interaction with the system. The system may provide many views for the same database.
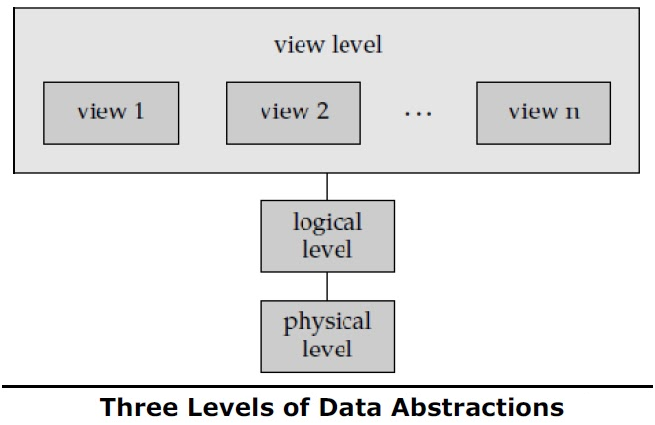
Relationship among the three levels of abstraction
For example we want to create a data structure to sore the record of an employee we may describe a record as follows:
type instructor = record
ID = char(5)
name = char(20)
dept_name = char(20)
salary = numeric(8,2)
end;
This code defines a new record type called instructor with four fields. Each field has a name and a type associated with it.
At the physical level, an instructor record can be described as a block of consecutive storage locations. The compiler hides this level of detail from programmers.
Similarly, the database system hides many of the lowest-level storage details from database programmers. Database administrators, on the other hand, may be aware of certain details of the physical organization of the data
At the logical level, each such record is described by a type definition and the interrelationship of these record types is defined as well. Programmers and database administrators usually work at this level of abstraction.
At the view level, computer users see a set of application programs that hide details of the data types. The views also provide a security mechanism to prevent users from accessing certain parts of the database. For example, clerks in the university registrar office can see only that part of the database that has information about students; they cannot access information about salaries of instructors.
Instances and Schemas
Databases change over time as information is inserted and deleted. The collection of information stored in the database at a particular moment is called an instance of the database.
The overall design of the database is called the database schema. Schemas are changed infrequently or not at all.
A database schema corresponds to the variable declarations (along with associated type definitions) in a program.
Each variable has a particular value at a given instant. The values of the variables in a program at a point in time correspond to an instance of a database schema.
Database systems have several schemas, partitioned according to the levels of abstraction.
Physical schema : Describes the database design at the physical level
Logical schema : Describes the database design at the logical level
View level schema: A database may also have several schemas at the view level, sometimes called subschemas, that describe different views of the database.
Data Models
Underlying the structure of a database is the data model: a collection of conceptual tools for describing data, data relationships, data semantics, and consistency constraints.
A data model provides a way to describe the design of a database at the physical, logical, and view levels.
The data models can be classified into four different categories:
Relational Model :
The relational model uses a collection of tables to represent both data and the relationships among those data.
Each table has multiple columns, and each column has a unique name. Tables are also known as relations.
The relational model is an example of a record-based model. Record-based models are so named because the database is structured in fixed-format records of several types. Each table contains records of a particular type.
Each record type defines a fixed number of fields, or attributes. The columns of the table correspond to the attributes of the record type.
Entity-Relationship Model:
The entity-relationship (E-R) data model uses a collection of basic objects, called entities and relationships among these objects.
An entity is a "thing" or "object" in the real world that is distinguishable from other objects.
Object-Based Data Model:
Object-oriented data model can be seen as extending the E-R model with notions of encapsulation, methods (functions), and object identity.
The object-relational data model combines features of the object-oriented data model and relational data model.
Semistructured Data Model:
The semistructured data model permits the specification of data where individual data items of the same type may have different sets of attributes.
This is in contrast to the data models mentioned earlier, where every data item of a particular type must have the same set of attributes.
The Extensible Markup Language (XML) is widely used to represent semistructured data.