Solved Examples of Iterative Method
Q. \( T(n) = \left\{\begin{matrix} T(n-1) + n & n > 1 \\ 1 & n = 1 \end{matrix}\right. \)
T(n) = T(n-1) + n
= T(n-2) + (n-1) + n
= T(n-3) + (n-2) + (n-1) + n
This substitution is done iteratively for 'n' times
= T(1) + n + (n-1) + (n-2) + (n-3) + .. + 1
= \( \frac{n(n+1)}{2} \)
= O(n2)
Q. \( T(n) = \left\{\begin{matrix} T(n-1) + 1/n & n > 1 \\ 1 & n = 1 \end{matrix}\right. \)
T(n) = T(n-1) + 1/n
= T(n-2) + 1/(n-1) + 1/n
= T(n-3) + 1/(n-2) + 1/(n-1) + 1/n
This substitution is done iteratively for 'n' times
= T(1) + 1/2 + 1/3 + ... + 1/(n-3) + 1/(n-2) + 1/(n-1) + 1/n
Now we know that A series of the form: log n = 1 + 1/2 + 1/3 + ... + 1/(n-3) + 1/(n-2) + 1/(n-1) + 1/n
T(n) = O(log n)
Q. \( T(n) = \left\{\begin{matrix} T(n/2) + 1 & n > 1 \\ 1 & n = 1 \end{matrix}\right. \)
T(n) = T(n/2) + 1
= T(n/22) + 1 + 1
= T(n/23) + 1 + 1 + 1
This substitution is done iteratively for 'k' times
>= T(n/2k) + 1 + 1 + 1 ... (k times)
Now we assume 2k = n; k = log2n
= T(1) + k
T(n) = log2n (As T(1) = 1 and k = log2n)
Q. \( T(n) = \left\{\begin{matrix} T(n-1) + log n & n > 1 \\ 1 & n = 1 \end{matrix}\right. \)
T(n) = T(n-1) + log n
= T(n-2) + log (n-1) + log n
= T(n-3) + log (n-2) + log (n-1) + log n
Repeating the above iteration '(n-1)' times
= T(1) + log 1 + log 2 + ... + log (n-2) + log (n-1) + log n
We know that the series log 1 + log 2 + ... + log (n-2) + log (n-1) + log n = n log n
= n log n
Ans . O(n log n)
Q. \( T(n) = \left\{\begin{matrix} 2T(n/2) + 2 & n > 1 \\ 1 & n = 1 \end{matrix}\right. \)
T(n) = 2T(n/2) + 2
= 2{2 T(n/22) + 2} + 2
= 22 T(n/22) + 22 + 2
= 22 {2 T(n/23) + 2} + 22 + 2
= 23 T(n/23) + 23 + 22 + 2
We know that the above series if repeated 'k' times we get
= 2k T(n/2k) + 2k + 2k-1 + ... + 2
The geometric series is 2k + 2k-1 + ... + 2 = \( \frac{2(2^k -1)}{(2 - 1)} \)
= 2k T(1) + 2(n-1) (As 2k = n)
= n + 2n - 1 (As 2k = n)
Ans . O(n)
Q. \( T(n) = \left\{\begin{matrix} 8T(n/2) + n^2 & n > 1 \\ 1 & n = 1 \end{matrix}\right. \)
T(n) = 8T(n/2) + n2
= 8{8 T(n/22) + (n/2)2} + n2
= 82 T(n/22) + (n2/22) + n2
= 82 {8 T(n/23) + (n/22)2} + (n2/22) + n2
= 83 T(n/23) + (n2/22)2 + (n2/22) + n2
We know that the above series if repeated 'k' times we get
= 8k T(n/2k) + (n2/22)k-1 + ... + (n2/22)1 + (n2/22)0
2k = n; k = log2 n
= \( (2^3)^k T(1) + n^2 [ \frac{1}{(2^2)^{k-1}} + ... + \frac{1}{(2^2)^{1}} + \frac{1}{(2^2)^{0}}] \)
This series is decreasing and the value is approx = 1 which is equal to the last term of the series; i.e. \( [ \frac{1}{(2^2)^{k-1}} + ... + \frac{1}{(2^2)^{1}} + \frac{1}{(2^2)^{0}}] \)
So, = \( n^3 + n^2[1] \)
Ans . O(n3)
Q. 2T(n/2) + n
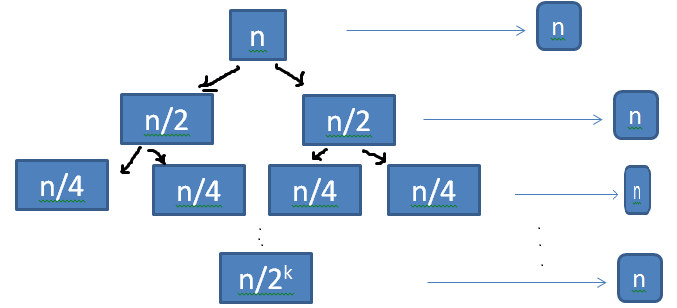
From recurrence tree we assume, \( 2^k = n, k = log_2 n \)
T(n) = n * k
T(n) = \( n log_2 n \)
Ans . T(n) = \( n log_2 n \)
Q. T(n) = 5T(n/5) + n
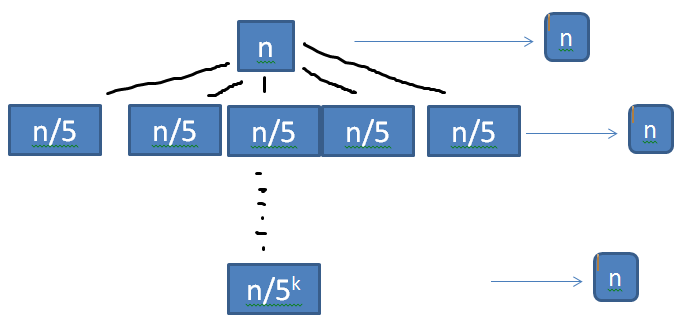
From recurrence tree we assume, \( 5^k = n, k = log_5 n \)
T(n) = n * k
T(n) = \( n log_5 n \)
Ans . T(n) = \( n log_5 n \)
Q. T(n) = T(n/3) + T(2n/3) + n
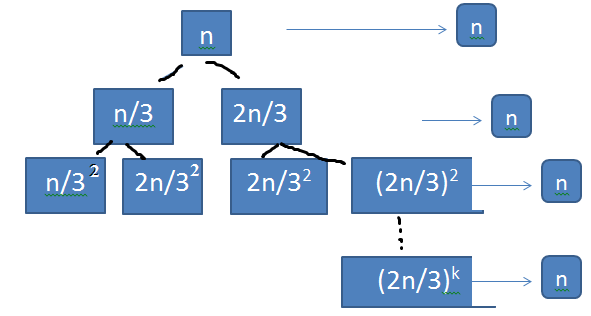
From recurrence tree we make assumption, \( (3/2)^k = n \) so \( k = log_{3/2} n \)
\( T(n) = n log_{3/2} n \)
Ans . T(n) = \( n log_{3/2} n \)
Q. T(n) = T(n/5) + T(4n/5) + n
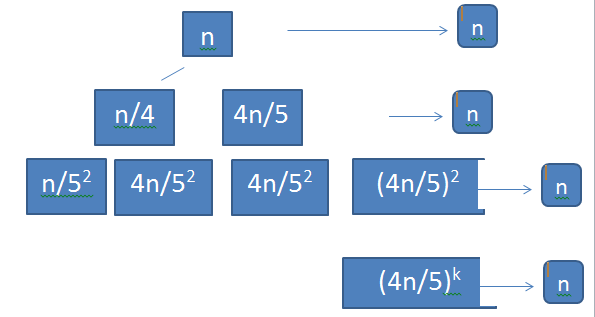
From recurrence tree we make assumption, \( (5/4)^k = n\) so \( k = log_{5/4} n \)
\( T(n) = n log_{5/4} n \)
Ans . \( T(n) = n log_{5/4} n \)
Q. T(n) = T(n/5) + T(3n/5) + n
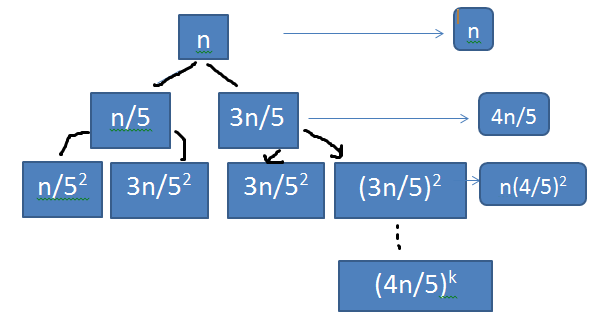
From the recurrence tree, we get assumption as \( n = (5/4)^k\)
T(n) = \( \frac{4n}{5} + (\frac{4}{5})^2n + ... + (\frac{4}{5})^kn \)
= \( n[\frac{(4/5)(1-(4/5)^k)}{(1-4/5)}] \)
= \( n[\frac{(4/5)(1)}{(1/5)}] \)
Ans . T(n) = O(n)
Q. T(n) = 3T(n/4) + n2
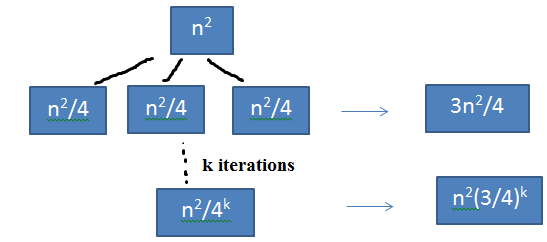
From the recurrence tree n = (3/4)k
T(n) = \( \frac{3n^2}{4} + (\frac{3}{4})^2n^2 + ... + (\frac{3}{4})^kn^2 \)
= \( n^2[ \frac{(3/4)(1 - (3/4)^k)}{(1/4)} ] \)
T(n) = O(n2)
Ans . T(n) = O(n2)
Master's Theorem
Since divide and conquer algorithms occur quite frequently and produce recursive equations for their run times, it is important to be able to solve recursive equations. For problems that have a fixed number of identical sized recursive pieces there is a much simpler method known as the master theorem that can be used to solve certain recursive equations almost "by inspection".
Master Theorem
The master theorem can be employed to solve recursive equations of the form
\( T(n) = a T(n/b) + f(n) \)
where a ≥ 1, b > 1, and f(n) is asymptotically positive. Intuitively for divide and conquer algorithms, this equation represents dividing the problem up into a subproblems of size n/b with a combine time of f(n). For example, for merge sort a = 2, b = 2, and f(n) = Θ(n). Note that floors and ceilings for n/b do not affect the asymptotic behavior or the results derived using the theorem.
If the recursion is in the form shown above, then the recurrence can be solved depending on one of three cases (which relate the dominance of the recursive term to the combine term):
Case 1
If
\( f(n) = O(n^{{log_b}^a - \epsilon}) \)
for some constant ε > 0, then the solution to the recurrence is given by
\( T(n) = \Theta(n^{{log_b}^a}) \)
In this case, f(n) is polynomially bounded above by \( n^{{log_b}^a} \) (which represents the run time of the recursive term), i.e. the recursive term dominates the run time.
Case 2
If
\( f(n) = \Theta(n^{{log_b}^a}) \)
then the solution to the recurrence is given by
\( T(n) = \Theta(n^{{log_b}^a} lg n) \)
In this case, f(n) is "equal" to \( n^{{log_b}^a} lg n\) , i.e. neither term dominates thus the extra term to get the bound.
Case 3
If
\( f(n) = \Omega(n^{{log_b}^a + \epsilon }) \)
for some constant ε > 0 AND if a f(n/b) ≤ c f(n) for some constant c < 1 and sufficiently large n (this additional constraint is known as the regularity condition), then the solution to the recurrence is given by
\( T(n) = \Theta(f(n))\)
In this case, f(n) is polynomially bounded below by \( n^{{log_b}^a} \) (which represents the run time of the recursive term) with the additional regularity condition, i.e. the combine term dominates the run time.
Thus in all three cases it is important to compute the recursive term run time \( n^{{log_b}^a} \) and compare it asymptotically to the combine term run time to determine which case holds. If the recursive equation satifies either case 1 or case 2, the solution can then be written by inspection. If the recursive equation satisfies case 3, then the regularity condition must be verified in order to write down the solution.
Note: There are gaps between the cases where the theorem cannot be applied (as well as recursive equations that do not fit the form required by the theorem exactly). In these cases, other techniques must be used which we will see next lecture.
Solved Questions - Master's Theorem
Q. T(n) = 9T(n/3) + n
For this recurrence we have a = 9, b = 3, f(n) = n and we have that
\( n^{log_{b}a} = n^{log_{3}9} \)
= Θ (n2)
Since f(n) = O(\( n^{log_{3}{9 - \epsilon}} \) where ε = 1. Here we can apply Case 1: of Master's theorem and we get
Ans . T(n) = Θ(n2)
Q. T(n) = T(2n/3) + 1;
We have a = 1, b = 3/2, f(n) = 1 and we have
\( n^{log_{b}a} = n^{log_{3/2}1} = n^0 = 1\)
Since we have f(n) = Θ(\( n^{log_{b}a} = \Theta(1) \))
The solution we get is
Ans . T(n) = Θ(lg n)
Q. T(n) = 3T(n/4) + n lg n
We have a = 3, b = 4, f(n) = n lg n
\( n^{log_{b}a} = n^{log_{4}3} = O(n^{0.793}) \)
Since we have f(n) = Ω(\( n^{log_4{3+\epsilon}} \)) where ε = 0.2
We can show that case 3: applies here since af(n/b) ≤ cf(n) for c = 3/4. So we get
Ans . T(n) = Θ(n lg n)
Q. T(n) = 2T(n/2) + n lg n
We know that a = 2, b = 2, f(n) = n lg n and \( n^{log_b{a}} = n\)
f(n) = n lg n is asymptotically larger than \( n^{log_b{a}} = n\). But it is not polynomially large since the ratio \( \frac{f(n)}{n^{log_b{a}}} = \frac{n lg n}{n} = lg n\) is asymptotically less than \( n^{\epsilon} \) for any positive constant ε
Ans . Cant be solved using masters theorem
Q. T(n) = 2T(n/2) + Θ(n)
We have a = 2, b = 2 and f(n) = Θ(n) and we have
\( n^{log_b{a}} = n^{log_2{2}} = n\)
Case 2 of masters theorem applies since f(n) = Θ(n)
Ans . T(n) = Θ(n lg n)
Q. T(n) = 8T(n/2) + Θ(n2)
We have a = 8, b = 2, f(n) = Θ(n2)
\( n^{log_b{a}} = n^{log_2{8}} = n^3 \)
Since n3 is polynomially larger than f(n) i.e. f(n) = O(\( n^{3-\epsilon} \)) for ε = 1
Case 1: applies and we get T(n) = Θ(n3)
Ans . T(n) = Θ(n3)
Q. T(n) = 7T(n/2) + Θ(n2)
We have a = 7, b = 2, f(n) = Θ(n2)
\( n^{log_b{a}} = n^{log_2{7}} = n^{2.81} \)
Since f(n) = O(\( n^{lg 7 - \epsilon} \)) for ε = 0.8
Case 1: applies and we get T(n) = Θ(nlg 7)
Ans . T(n) = Θ(nlg 7)
Q. T(n) = 4T(n/2) + n2
We have a = 4, b = 2, f(n) = n2
\( n^{log_b{a}} = n^{log_2{4}} = n^{2} \)
Since f(n) = \( \Theta( n^{log_2{4}} )\)
Case 2: applies and we get T(n) = Θ(n2 log n)
Ans . T(n) = Θ(n2 log n)
Q. T(n) = 2nT(n/2) + nn
Since a is not a number, we cannot solve the recurrance using masters theorem.
Q. T(n) = 2T(n/2) + n / log n
We have a = 2, b = 2, f(n) = n / log n
\( n^{log_b{a}} = n^{log_2{2}} = n^{1} = n\)
Since difference of f(n) and \( n^{log_b{a}} \) is not polynomial we cannot solve recurrence using masters theorem
Q. T(n) = 0.5T(n/2) + n
We have a = 0.5, b = 2, f(n) = n
Since a < 1, we cannot solve recurrence using masters theorem
Q. T(n) = 64T(n/8) - n2 log n
We have a = 64, b = 8, f(n) = - n2 log n
Since the combination time i.e. f(n) = - n2 log n is not positive, we cannot solve this recurrence using masters theorem
Probabilistic Analysis
Probabilistic analysis is the use of probability in the analysis of problems. We use probabilistic analysis to study the running time of an algorithm.
Describe an implementation of the procedure RANDOM(a,b) that only makes calls to RANDOM(0,1). What is the expected running time of your procedure, as a function of a and b?
Algorithm 1: RANDOM(a,b)
n = lg(b - a + 1)
Initialize an array A of length n
while true do
for i = 1 to n do
A[i] = RANDOM(0, 1)
end for
if A holds the binary representation of one of the numbers in a through b then
return number represented by A
end if
end while
Each iteration of the while loop takes n time to run. The probability that the while loop stops on a given iteration is (b-a+1)/2n. Thus the expected running time is the expected number of times run times n. This is given by:
\( n\sum_{i \ge 1} i (1 - \frac{b-a+1}{2^n})^{i-1}(\frac{b-a+1}{2^n}) \)
\( n( \frac{b-a+1}{2^n})(\frac{2^n}{b-a+1})^2 \)
\( n(\frac{2^n}{b-a+1}) \)
O(lg(b-a)).
The hiring problem - Probabilisitc Analysis
Scenario: You are using an employment agency to hire a new office assistant. The agency sends you one candidate each day. You interview the candidate and must immediately decide whether or not to hire that person. But if you hire, you must also fire your current office assistant even if its someone you have recently hired.
Cost to interview is ci per candidate (interview fee paid to agency). Cost to hire is ch per candidate (includes cost to fire current office assistant + hiring fee paid to agency). Assume that ch > ci. You are committed to having hired, at all times, the best candidate seen so far. Meaning that whenever you interview a candidate who is better than your current office assistant, you must fire the current office assistant and hire the candidate. Since you must have someone hired at all times, you will always hire the first candidate that you interview.
Goal: Determine what the price of this strategy will be.
Pseudocode to model this scenario: Assumes that the candidates are numbered 1 to n and that after interviewing each candidate, we can determine if he is better than the current office assistant. Uses a dummy candidate '0' that is worse than all others, so that the first candidate is always hired.
HIRE-ASSISTANT(n)
best ← 0 ; candidate 0 is a least-qualified dummy candidate
for i ← 1 to n
do interview candidate i
if candidate i is better than candidate best
then best ← i
hire candidate i
Cost: If n candidates, and we hire m of them, the cost is O(nci + mch)
Have to pay nci to interview, no matter how many we hire.
So we focus on analyzing the hiring cost mch. mch varies with each run i.e. it depends on the order in which we interview the candidates.
This is a model of a common paradigm: we need to Þnd the maximum or minimum in a sequence by examining each element and maintaining a current winner. The variable m denotes how many times we change our notion of which element is currently winning.
Worst Case Analysis:
In the worst case, we hire all n candidates.
This happens if each one is better than all who came before. In other words, if the candidates appear in increasing order of quality.
If we hire all n, then the cost is O(nci + mch) = O(nch) (Since ch > ci)
Probabilistic analysis:
We have no control over the order in which candidates appear.So we could assume that they come in a random order:
The ordered list {rank(1), rank(2),...,rank(n)} is a permutation of the candidate numbers {1, 2,...,n}.
The list of ranks is equally likely to be any one of the n!permutations.
Equivalently, the ranks form a uniform random permutation: each of the possible n! permutations appears with equal probability.
Essential idea of probabilistic analysis:
We must use knowledge of, or make assumptions about, the distribution of inputs.
The expectation is over this distribution.
This technique requires that we can make a reasonable characterization of the input distribution.
Randomized algorithms:
We might not know the distribution of inputs, or we might not be able to model it computationally.
Instead, we use randomization within the algorithm in order to impose a distribution on the inputs.
For the hiring problem: Change the scenario:
The employment agency sends us a list of all 'n' candidates in advance.
On each day, we randomly choose a candidate from the list to interview (but considering only those we have not yet interviewed).
Instead of relying on the candidates being presented to us in a random order, we take control of the process and enforce a random order.
What makes an algorithm randomized: An algorithm is randomized if its behavior is determined in part by values produced by a random-number generator.
RANDOM(a, b) returns an integer r , where a ≤ r ≤ b and each of the b − a + 1 possible values of r is equally likely.
In practice, RANDOM is implemented by a pseudorandom-number generator, which is a deterministic method returning numbers that look random and pass statistical tests.
Solved Question Papers
Q. Which one of the following correctly determines the solution of the
recurrence relation with T(1) = 1?
T(n) = 2T(n/2) + Logn (GATE 2014 SET 2)
Θ(n)
Θ(nLogn)
Θ(n * n)
Θ(logn)
Ans . 1
solution
By master's theorem
a = 1,b=2 k =1
therefore T(n) = Θ(n)
Q. The running time of an algorithm is represented by the following recurrence relation: (GATE 2009)
if n <= 3 then T(n) = n
else T(n) = T(n/3) + cn
Q 2Which of the given options provides the increasing order of asymptotic
complexity of functions f1,f2,f3 and f4?
f1(n)=2n; f2(n)=n3/2 ; f3(n)=nlog2n ; f4(n)=n(log2n)
(GATE 2011)
f3,f2,f4,f1
f3,f2,f1,f4
f2,f3,f1,f4
f2,f3,f4,f1
Ans . (A)
Let n=1024
f1(n)=21024
f2(n)=215
f3(n)=10 * 210
f4(n)=102410=2100
Therefore f3 , f2 , f4 , f1 is the required increasing order.
Q. Suppose T(n) = 2T (n/2) + n, T(0) = T(1) = 1 Which one of the following is FALSE? (GATE 2005)
T(n) = O((n2)
T(n) = Θ(n log n)
T(n) = Ω(n^2)
T(n) = O(n log n)
Ans . (c)
T(n) = 2T (n/2) + n ---eqn(a)
T(n/2)=2T(n/22)+n/2 ---eqn(b)
Substitute (b) in (a)
T(n) = 2[2T(n/22)+n/2]+n
= 22T(n/22)+2n
By generalizing,
T(n) = 2kT(n/2k)+kn ---eqn(c)
The base condition is T(1)=1,
so n/2k = 1 then k=log n.
Substitute k=log n in eqn(c)
T(n) = nT(1)+(log n)n
= O(nlogn)
can also be written as O(n2)
Hence,Ω(n^2)
Q.5 Suppose there are ⌈log n⌉ sorted lists of ⌊n/log n⌋ elements each. The time complexity of producing a sorted list of all these elements is : (GATE 2005)
O(n log log n)
Θ(n log n)
Ω(n log n)
Ω(n3⁄2)
Ans . (a)
We can merge x arrays of each size y in in O(xy*Logy) time using Min Heap.
x = n/Logn
y = Logn
We get O(n/Logn * Logn * Log Log n) which is O(nLogLogn)
Common data for Q.6 and Q.7
Consider the following C-function:
double foo (int n)
{
int i;
double sum;
if (n = = 0) return 1.0;
else
{
sum = 0.0;
for (i = 0; i < n; i++)
sum += foo (i);
return sum;
}
}
Q.6 The space complexity of the above function is: (GATE 2005)
O(1)
O(n)
O(n!)
O(nn)
Ans . (b)
The function foo() is recursive. Space complexity is O(n) as there can be at most O(n) active functions (function call frames) at a time.
Q.7 Suppose we modify the above function foo() and store the values of foo (i), 0 < = i < n, as and when they are computed. With this modification, the time complexity for function foo() is significantly reduced. The space complexity of the modified function would be: (GATE 2005)
O(1)
O(n)
O(n!)
O(nn)
Ans . (b)
Space complexity now is also O(n). We would need an array of size O(n). The space required for recursive calls would be O(1) as the values would be taken from stored array rather than making function calls again and again.
Q. The running time of an algorithm is represented by the following recurrence relation:
if n <= 3 then T(n) = n
else T(n) = T(n/3) + cn
Which one of the following represents the time complexity of the algorithm?
(A) \theta(n) (B) \theta(n log n) (C) \theta(n^2) (D) \theta(n^2log n)(GATE 2009)
A
B
C
D
Ans: A