Concurrency Control
When several transactions execute concurrently in the database, however, the isolation property may no longer be preserved.
To ensure that it is, the system must control the interaction among the concurrent transactions; this control is achieved through one of a variety of mechanisms called concurrency control schemes.
Lock-Based Protocols
To ensure isolation we require that data items be accessed in a mutually exclusive manner; that is, while one transaction is accessing a data item, no other transaction can modify that data item.
The most common method used to implement this requirement is to allow a transaction to access a data item only if it is currently holding a lock on that item.
There are two modes in which a data item may be locked :-
Shared : If Ti has obtained a shared mode lock on item Q, then Ti can read Q but not write Q.
Exclusive : If Ti has obtained an exclusive mode lock on item Q, then Ti can read Q and write Q.
The transaction makes the request to the concurrency-control manager. The transaction can proceed with the operation only after the concurrency-control manager grants the lock to the transaction.
The use of these two lock modes allows multiple transactions to read a data item but limits write access to just one transaction at a time.
Shared mode is compatible with shared mode, but not with exclusive mode. At any time, several shared-mode locks can be held simultaneously (by different transactions) on a particular data item. A subsequent exclusive-mode lock request has to wait until the currently held shared-mode locks are released.
Deadlock is a situation that is created when locking mechanism is used. The transactions wait for each other indefinitely in a deadlock. This situation can be resolved by rolling back a few transactions and unlocking data-items held by them.
Granting of Locks - Starvation
Suppose a data item Q is present and a transaction T1 holds a shared lock on it.
T2 requests for an exclusive lock on Q but has to wait as locks are incompatible.
However a second transaction T3 that request shared lock may be granted it. Now T2 has to wait for T3 to be over.
Thus, T2 may never get its lock granted as shared lock requests may come from other transactions. This situation is called starvation of T2.
We can avoid starvation of transactions by granting locks in the following manner: When a transaction Ti requests a lock on a data item Q in a particular mode M, the concurrency-control manager grants the lock provided that:
There is no other transaction holding a lock on Q in a mode that conflicts with M.
There is no other transaction that is waiting for a lock on Q and that made its lock request before Ti.
The Two-Phase Locking Protocol
This protocol requires that each transaction issue lock and unlock requests in two phases:
Growing phase : A transaction may obtain locks, but may not release any lock.
Shrinking phase : A transaction may release locks, but may not obtain any new locks.
Initially, a transaction is in the growing phase. The transaction acquires locks as needed. Once the transaction releases a lock, it enters the shrinking phase, and it can issue no more lock requests.
The two-phase locking protocol ensures conflict serializability.
Two-phase locking does not ensure freedom from deadlock.
Cascading rollback may occur under two-phase locking.
T3 and T4 are in Two phase (deadlocked) but T1 and T2 are not in two phase.
Note that the unlock instructions do not need to appear at the end of the transaction.
Although T5, T6, T7 are in two phase but a failure of T5 leads to cascading rollback of T6 and T7.

Strict two-phase locking protocol.
Cascading rollbacks can be avoided by a modification of two-phase locking called the strict two-phase locking protocol.
This protocol requires not only that locking be two phase, but also that all exclusive-mode locks taken by a transaction be held until that transaction commits.
This requirement ensures that any data written by an uncommitted transaction are locked in exclusive mode until the transaction commits, preventing any other transaction from reading the data.
Rigorous two-phase locking protocol
Requires that all locks be held until the transaction commits.
With rigorous two-phase locking, transactions can be serialized in the order in which they commit.
Deadlock Handling
There are two principal methods for dealing with the deadlock problem. We can use a deadlock prevention protocol to ensure that the system will never enter a deadlock state.
Alternatively, we can allow the system to enter a deadlock state, and then try to recover by using a deadlock detection and deadlock recovery scheme.
Both methods may result in transaction rollback. Prevention is commonly used if the probability that the system would enter a deadlock state is relatively high; otherwise, detection and recovery are more efficient.
Note that a detection and recovery scheme requires overhead that includes not only the run-time cost of maintaining the necessary information and of executing the detection algorithm, but also the potential losses inherent in recovery from a deadlock.
Deadlock Prevention
There are two approaches to deadlock prevention.
One approach ensures that no cyclic waits can occur by ordering the requests for locks, or requiring all locks to be acquired together.
The other approach is closer to deadlock recovery, and performs transaction rollback instead of waiting for a lock, whenever the wait could potentially result in a deadlock
First approach requires that :-
each transaction locks all its data items before it begins execution
either all are locked in one step or none are locked
There are two main disadvantages to this protocol :
it is often hard to predict, before the transaction begins, what data items need to be locked;
data-item utilization may be very low, since many of the data items may be locked but unused for a long time.
Second approach for preventing deadlocks is : -
To impose an ordering of all data items, and to require that a transaction lock data items only in a sequence consistent with the ordering.
A variation of this approach is to use a total order of data items, in conjunction with two-phase locking.
Once a transaction has locked a particular item, it cannot request locks on items that precede that item in the ordering.
This scheme is easy to implement, as long as the set of data items accessed by a transaction is known when the transaction starts execution.
The alternate strategy allows system uses these timestamps to decide whether a transaction should wait for a resource or roll back. Two different deadlock-prevention schemes using timestamps have been proposed:
Wait die (nonpreemptive technique) : When transaction Ti requests a dataitem currently held by Tj , Ti is allowed to wait only if it has a timestamp smaller than that of Tj. Otherwise, Ti is rolled back (dies).
Wound wait (preemptive technique) : When transaction Ti requests a dataitem currently held by Tj , Ti is allowed to wait only if it has a timestamp larger than that of Tj. Otherwise, Tj is rolled back.
The major problem with both of these schemes is that unnecessary rollbacks may occur.
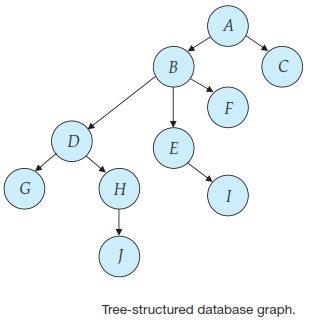
Graph-Based Protocols - tree protocol
In the tree protocol, the only lock instruction allowed is lock - X. Each transaction Ti can lock a data item at most once, and must observe the following rules:
The first lock by Ti may be on any data item.
Subsequently, a data item Q can be locked by Ti only if the parent of Q is currently locked by Ti.
Data items may be unlocked at any time.
A data item that has been locked and unlocked by Ti cannot subsequently be relocked by Ti.
All schedules that are legal under the tree protocol are conflict serializable.
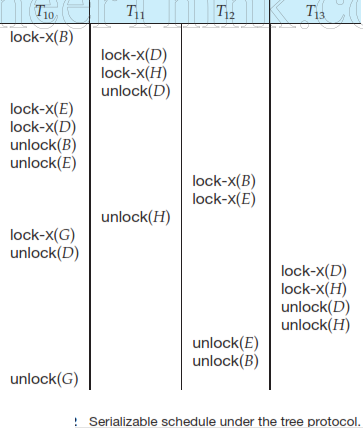
T10 : lock-X(B); lock-X(E); lock-X(D); unlock(B); unlock(E); lock-X(G); unlock(D); unlock(G)
T11 : lock-X(D); lock-X(H); unlock(D); unlock(H)
T12 : lock-X(B); lock-X(E); unlock(E); unlock(B).
T13 : lock-X(D); lock-X(H); unlock(D); unlock(H).
Tree protocol ensures freedom from deadlock. It does not ensure recoverability and cascadelessness. To ensure recoverability and cascadelessness, the protocol can be modified to not permit release of exclusive locks until the end of the transaction.
The tree-locking protocol has an advantage over the two-phase locking protocol in that unlocking may occur earlier. Earlier unlocking may lead to shorter waiting times, and to an increase in concurrency.
However, the protocol has the disadvantage that, in some cases, a transaction may have to lock data items that it does not access. For example, a transaction that needs to access data items A and J in the database graph of Figure above must lock not only A and J,but also data items B, D and H.
This additional locking results in increased locking overhead, the possibility of additional waiting time, and a potential decrease in concurrency. Further, without prior knowledge of what data items will need to be locked, transactions will have to lock the root of the tree, and that can reduce concurrency greatly.
Deadlock Detection - wait-for graph
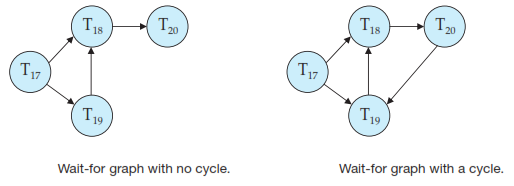
Deadlocks can be described precisely in terms of a directed graph called a wait-for graph. This graph consists of a pair G =(V, E), where V is a set of vertices and E is a set of edges. The set of vertices consists of all the transactions in the system.
If there is an edge from Ti to Tj in the wait for graph, this means that Ti is waiting for transaction Tj to release a data item that it needs.
A deadlock exists in the system if and only if the wait-for graph contains a cycle. Each transaction involved in the cycle is said to be deadlocked.
To detect deadlocks, the system needs to maintain the wait-for graph, and periodically to invoke an algorithm that searches for a cycle in the graph.
VIEW SERIALIZABILITY
Consider two schedules S and S' where the same set of transactions participates in both schedules. The schedules S and S' are said to be view equivalent if three conditions are met:
For each data item Q, if transaction Ti reads the initial value of Q in schedule S, then transaction Ti must, in schedule S', also read the initial value of Q.
For each data item Q, if transaction Ti executes read(Q) in schedule S, and if that value was produced by a write(Q) operation executed by transaction Tj, then the read(Q) operation of transaction Ti must, in schedule S' , also read the value of Q that was produced by the same write(Q) operation of transaction Tj.
For each data item Q, the transaction (if any) that performs the final write(Q) operation in schedule S must perform the final write(Q) operation in schedule S'.
Every conflict-serializable schedule is also view serializable, but there are view-serializable schedules that are not conflict serializable.
Blind writes are Write(Q) operations without Read(Q) they appear in a view-serializable schedule that is not conflict serializable.
