Quicksort
The quicksort algorithm has a worst-case running time of Θ(n2)on an input array of n numbers.
Despite this slow worst-case running time, quicksort is often the best practical choice for sorting because it is remarkably efficient on the average: its expected running time is Θ(n lg n), and the constant factors hidden in the Θ(n lg n) notation are quite small.
It also has the advantage of sorting in place and it works well even in virtual-memory environments.
Quicksort Steps
Quick-sort, like merge sort, applies the divide-and-conquer paradigm . The three-step divide-and-conquer process for sorting a typical subarray A[p ... r]
Divide: Partition (rearrange) the array A[p... r] into two (possibly empty) sub-arrays A[p... q-1] and A[q+1 ...r] such that each element of A[p...q - 1] is less than or equal to A[q], which is, in turn, less than or equal to each element of A[q + 1 ... r]. Compute the index q as part of this partitioning procedure.
Conquer: Sort the two sub-arrays A[p ... q-1] and A[q+1 ... r] by recursive calls to quick-sort.
Combine: Because the subarrays are already sorted, no work is needed to combine them: the entire array A[p...r] is now sorted.
Quicksort Pseudocode:
QUICKSORT(A,p,r)
if p < r
q = PARTITION(A,p,r)
QUICKSORT(A,p,q-1)
QUICKSORT(A,q+1,r)
PARTITION(A,p,r)
x = A[r]
i = p - 1
for j = p to r - 1
if A[j] ≤ x
i = i + 1
exchange A[i] with A[j]
exchange A[i+1] with A[r]
return i + 1
Operation of Quicksort
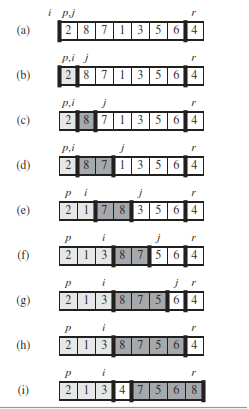
The operation of PARTITION on a sample array. Array entry A[r] becomes the pivot element x. Lightly shaded array elements are all in the first partition with values no greater than x. Heavily shaded elements are in the second partition with values greater than x.
The unshaded elements have not yet been put in one of the first two partitions, and the final white element is the pivot x.
Fig (a) The initial array and variable settings. None of the elements have been placed in either of the first two partitions. Fig(b) The value 2 is “swapped with itself” and put in the partition of smaller values.
Fig (c)–(d) The values 8 and 7 are added to the partition of larger values. (e) The values 1 and 8 are swapped, and the smaller partition grows. (f) The values 3 and 7 are swapped, and the smaller partition grows.
Fig (g)–(h) The larger partition grows to include 5 and 6, and the loop terminates. Fig (i) In lines 7–8, the pivot element is swapped so that it lies between the two partitions
Worst-case partitioning
The worst-case behavior for quicksort occurs when the partitioning routine produces one subproblem with n - 1 elements and one with 0 elements.
The worst-case running time of quicksort is when the input array is already completely sorted Θ(n2)
T(n) = Θ(n lg n) occurs when the PARTITION function produces balanced partition.
Sorts in place. If the subarrays are balanced, then quicksort can run as fast as mergesort. If they are unbalanced, then quicksort can run as slowly as insertion sort.
Worst-case partitioning: Recurrance Relation
T (n) = T (n − 1) + T (0) + Θ(n)
= T (n − 1) + Θ(n)
= Θ(n2)
Best-case partitioning: Recurrance Relation
T (n) = 2T (n/2) + Θ(n)
= Θ(n lg n)
Randomized version of quicksort
We have assumed that all input permutations are equally likely. This is not always true. To correct this, we add randomization to quicksort.
We could randomly permute the input array.
Instead, we use random sampling, or picking one element at random.
Don't always use A[r] as the pivot. Instead, randomly pick an element from the subarray that is being sorted. We add this randomization by not always using A[r] as the pivot, but instead randomly picking an element from the subarray that is being sorted. Randomly selecting the pivot element will, on average, cause the split of the input array to be reasonably well balanced.
RANDOMIZED-PARTITION( A, p, r )
i ← RANDOM( p, r )
exchange A[r] ↔ A[i]
return PARTITION( A, p, r )
RANDOMIZED-QUICKSORT( A, p, r )
if p < r
then q ← RANDOMIZED-PARTITION( A, p, r )
RANDOMIZED-QUICKSORT( A, p, q − 1)
RANDOMIZED-QUICKSORT( A, q + 1, r)
Quicksort v/s Mergesort
| Quicksort | Mergesort |
|---|---|
| O(nlogn) is the best case and average case time complexity whereas \(O(n^2)\) is worst case. | The time complexity is independent of the dataset and is O(nlogn) in all cases. |
| Not a stable sort | Stable sort |
| Additional space is not required. Superior in terms of space | Extra space is required to store elements during merge. |
| It has smaller constants in O(nlogn) as compared to merge sort | |
| Quicksort is preferred when the amount of data can fit into main memory. (RAM / internal memory) | For huge amounts of data go for Merge sort |
| Quick sort is preferred for arrays as lots of restructuring and random access is required as usage of linked list can be expensive | It accesses data sequentially and hence linked lists can be used preferably |
Counting sort
Counting sort assumes that each of the n input elements is an integer in the range 0 to k, for some integer k. When k = O(n), the sort runs in Θ(n) time.
In the code for counting sort, we assume that the input is an array A[1 ... n],and thus A.length = n. We require two other arrays: the array B[1..n] holds the sorted output, and the array C[0...k] provides temporary working storage.
Algorithm of Counting Sort
COUNTING-SORT(A,B,k)
let C[0...k] be a new array
for i = 0 to k
C[i] = 0
for j = 1 to A.length
C[A[j]] = C[A[j]] + 1
// C[i] now contains the number of elements equal to i.
for i = 1 to k
C[i] = C[i] + C[i-1]
// C[i] now contains the number of elements less than or equal to i
for j = A.length downto 1
B[C[A[j]]] = A[j]
C[A[j]] = C[A[j]] - 1
Working of Counting Sort
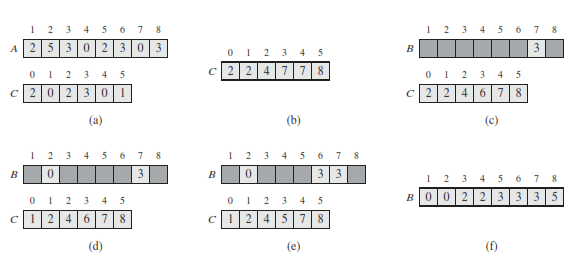
The operation of COUNTING-SORT on an input array A[1...8], where each element of A is a nonnegative integer no larger than k = 5. (a) The array A and the auxiliary array C after line 5. (b) The array C after line 8. (c)–(e) The output array B and the auxiliary array C after one, two, and three iterations of the loop in lines 10–12, respectively. Only the lightly shaded elements of array B have been filled in. (f) The final sorted output array B
After the for loop of lines 2–3 initializes the array C to all zeros, the for loop of lines 4–5 inspects each input element. If the value of an input element is i , we increment C[i]. Thus, after line 5, C[i] holds the number of input elements equal to i for each integer i = {0; 1; ...; k}. Lines 7–8 determine for each i = {0; 1; ...; k} how many input elements are less than or equal to i by keeping a running sum of the array C.
Finally, the for loop of lines 10–12 places each element A[j] into its correct sorted position in the output array B.If all n elements are distinct, then when we first enter line 10, for each A[j] ,the value C[A[j]] is the correct final position of A[j] in the output array, since there are C[A[j]] elements less than or equal to A[j].
Because the elements might not be distinct, we decrement C[A[j]] each time we place a value A[j] into the B array. Decrementing C[A[j]] causes the next input element with a value equal to A[j], if one exists, to go to the position immediately before A[j] in the output array.
Runtime of Counting Sort
The Ω(n lg n) is the lower bound for sorting of category of comparison sort.
An important property of counting sort is that it is stable so numbers with the same value appear in the output array in the same order as they do in the input array.
Runtime is Θ(n)
Exercises of Counting Sort
Q. illustrate the operation of COUNTING-SORT on the array A = {6; 0; 2; 0; 1; 3; 4; 6; 1; 3; 2}.
We have that C = {2; 4; 6; 8; 9; 9; 11}. Then, after successive iterations of the loop on lines 10-12, we have B = {; ; ; ; ; 2; ; ; ; ; } B = { ; ; ; ; ; 2; ; 3; ; ; } ,B = { ; ; ; 1; ; 2; ; 3; ; ; } and at the end, B = {0; 0; 1; 1; 2; 2; 3; 3; 4; 6; 6}
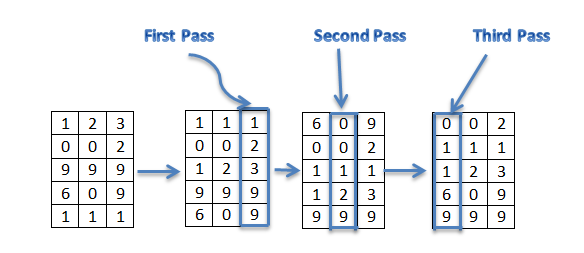
Radix sort
Radix sort solves the problem of card sorting counter intuitively by sorting on the least significant digit first.
The algorithm then combines the cards into a single deck, with the cards in the 0 bin preceding the cards in the 1 bin preceding the cards in the 2 bin, and so on.
Then it sorts the entire deck again on the second-least significant digit and recombines the deck in a like manner. The process continues until the cards have been sorted on all d digits. Remarkably, at that point the cards are fully sorted on the d-digit number. Thus, only d passes through the deck are required to sort.
Example of Radix Sort
Original, unsorted list: 170, 45, 75, 90, 802, 2, 24, 66
Sorting by least significant digit (1s place) gives: 170, 90, 802, 2, 24, 45, 75, 66. Notice that we keep 802 before 2, because 802 occurred before 2 in the original list, and similarly for pairs 170 & 90 and 45 & 75
Sorting by next digit (10s place) gives: 802, 2, 24, 45, 66, 170, 75, 90 Notice that 802 again comes before 2 as 802 comes before 2 in the previous list.
Sorting by most significant digit (100s place) gives: 2, 24, 45, 66, 75, 90, 170, 802. It is important to realize that each of the above steps requires just a single pass over the data, since each item can be placed in its correct bucket without having to be compared with other items.
RADIX-SORT(A,d)
for i = 1 to d
use a stable sort to sort array A on digit i
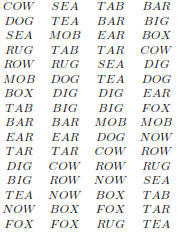
Q. illustrate the operation of RADIX-SORT on the following list of English words: COW, DOG, SEA, RUG, ROW, MOB, BOX, TAB, BAR, EAR, TAR, DIG, BIG, TEA, NOW, FOX.
Starting with the unsorted words on the left, and stable sorting by progressively more important positions.
Bucket sort
BUCKET-SORT(A)
let B[0...n-1] be a new array
n = A.length
for i = 0 to n - 1
make B[i] an empty list
for i = 1 to n
insert A[i] into list B[nA[i]]
for i = 0 to n - 1
sort list B[i] with insertion sort
concatenate the lists B[0]; B[1]; : : : ; B[n-1] together in order
Average-case running time for bucket sort is Θ(n)
Working of Bucket Sort
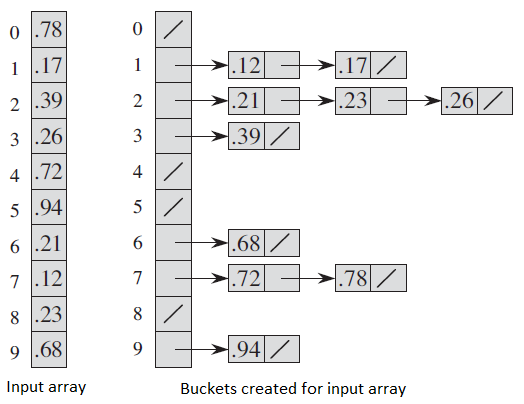
The operation of BUCKET-SORT for n = 10. (a) The input array A[1...10]. (b) The array B[0...9] of sorted lists (buckets) after line 8 of the algorithm.
Bucket i holds values in the half-open interval [i/10, (i + 1)/10).
The sorted output consists of a concatenation in order of the lists B[0]; B[1]; .... ; B[9].
Solved Question Papers
Q.1 Which one of the following is the recurrence equation for the worst case time complexity of the Quicksort algorithm for sorting (n > = 2) numbers? In the recurrence equations given in the options below, c is a constant.(Gate 2015 Set1)
T(n) = 2T(n=2) + cn
T(n) = T(n – 1) + T(0) + cn
T(n) = 2T(n – 2) + cn
T(n) = T(n=2) + cn
Ans: (B)
In worst case, the chosen pivot is always placed at a corner position and recursive call is made for following. a) for subarray on left of pivot which is of size n-1 in worst case. b) for subarray on right of pivot which is of size 0 in worst case.
Q. A max-heap is a heap where the value of each parent is greater than or equal to the value of its children. Which of the following is a max-heap? (GATE 2011)
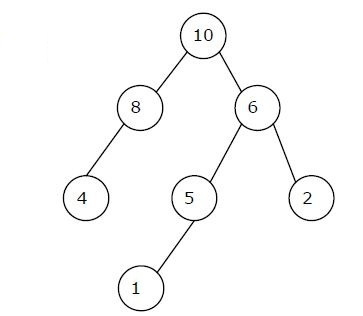
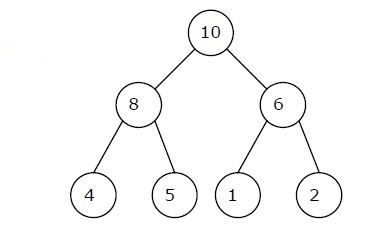
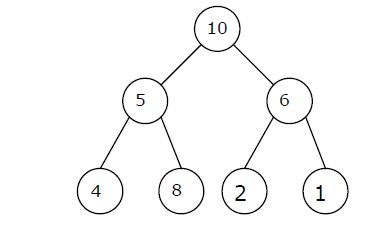
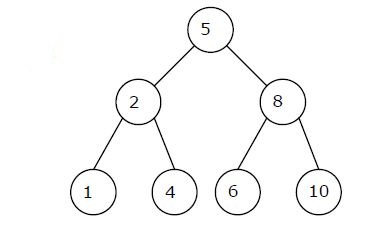
Ans . 2
Heap is a complete binary tree
Q. In quick sort, for sorting n elements, the the smallest element is selected as pivot using an O(n) time algorithm. What is the worst case time complexity of the quick sort? (GATE 2009)
(A)Θ(n)
(B) Θ(nlogn)
(C)Θ(n^2)
(D)Θ(n^2logn)
Ans . B
The recursion expression becomes:
T(n) = T(n/4) + T(3n/4) + cn
which is the average case complexity. And average case complexity of quick sort is θ(nlogn)
Q. Consider the Quicksort algorithm. Suppose there is a procedure for finding a pivot element which splits the list into two sub-lists each of which contains at least one-fifth of the elements. Let T(n) be the number of comparisons required to sort n elements. Then (GATE Paper-2008)
T(n) <= 2T(n/5) + n
T(n) <= T(n/5) + T(4n/5) + n
T(n) <= 2T(4n/5) + n
T(n) <= 2T(n/2) + n
Ans . (3)
Explanation :
For the case where n/5 elements are in one subset, T(n/5) comparisons are needed for the first subset with n/5 elements, T(4n/5) is for the rest 4n/5 elements, and n is for finding the pivot. If there are more than n/5 elements in one set then other set will have less than 4n/5 elements and time complexity will be less than T(n/5) + T(4n/5) + n because recursion tree will be more balanced.
Q.1 You have an array of n elements. Suppose you implement quicksort by always choosing the central element of the array as the pivot. Then the tightest upper bound for the worst case performance is (GATE 2014 SET 3)
- \( O{(n)^2} \)
- \(O(n\log n)\)
- \(\theta (n\log n)\)
- \(O{\left( n \right)^3}\)
Ans . \( O{\left( n \right)^2}\)
The central element may always be an extreme element, therefore time complexity in worst case becomes \(O{\left( n \right)^2}\)
(SET April 2017 Paper-II A)
Q. Merging 4 sorted files containing 50, 10, 25 and 15 records will take ______ time
(A) O(100)
(B) O(200)
(C) O(175)
(D) O(125)
Ans. (A) O(100)
- Explanation:
Time Complexity of Merge sort is O(n log n). But Combine step or Merging a total of 'n' elements taking O(n) time. So, O(100) is the correct option here as total 100 records to merged.
(SET April 2017 Paper-III A)
Q. For sorting ______ algorithm scans the list by swapping the entries whenever pair of adjacent keys are out of desired order.
(A) Quick sort
(B) Shell sort
(C) Insertion sort
(D) Bubble Sort
Ans. (D) Bubble Sort
- Explanation:
As in bubble sort always we swap the adjacent keys if they are not in desired order.
Q. For the following:
To solve a problem linear algorithm must perform faster than quadratic algorithm
An algorithm with worst case time behavior = 3n takes 30 operations for every input of size n=10
(A) Both (i) and (ii) are false
(B) Both (i) and (ii) are true
(C) (i) is false and (ii) is true
(D) (i) is true and (ii) is false
Ans. (D) (i) is true and (ii) is false
- Explanation:
As the first statement is true according to the definition of linear algorithms, the second is false as 30 operations are not needed.
Q. The best/worst case time complexity of quick sort is:
(A) O(n)/O(n2)
(B) O(n)/O(n log n)
(C) O(n log n)/O(n2)
(D) O(n log n)/O(n log n)
Ans. (C) O(n log n)/O(n2)
- Explanation:
For quick sort best case time complexity is O(n log n) & worst case time complexity is O(n2).
Q 5. What is the number of swaps required to sort n elements using selection sort, in the worst case?(GATE 2009)
θ(n)
θ(n Log n)
θ(n*n)
θ(n*nLog n)
Ans: A
Q 6.In quick sort, for sorting n elements, the (n/4)th smallest element is selected as pivot using an O(n) time algorithm. What is the worst case time complexity of the quick sort? (GATE 2009)
θ(n)
θ(n Log n)
θ(n*n)
θ(n*nLog n)
Ans: B
Q 7.
I. There exist parsing algorithms for some programming languages
whose complexities are less than O(n3).
II. A programming language which allows recursion can be implemented
with static storage allocation.
III. No L-attributed definition can be evaluated in The framework
of bottom-up parsing.
IV. Code improving transformations can be performed at both source
language and intermediate code level. (GATE 2009)
I and II
I and IV
III and IV
I,III and IV
Ans: B