Process Management
A process can be thought of as a program in execution. A process will need certain resources-such as CPU time, memory, files, and 1/0 devices -to accomplish its task. These resources are allocated to the process either when it is created or while it is executing.
A process is the unit of work in most systems. Systems consist of a collection of processes: Operating-system processes execute system code, and user processes execute user code. All these processes may execute concurrently.
Although traditionally a process contained only a single thread of control as it ran, most modem operating systems now support processes that have multiple threads.
The operating system is responsible for the following activities in connection with process and thread management: the creation and deletion of both user and system processes; the scheduling of processes; and the provision of mechanisms for synchronization, communication, and deadlock handling for processes.
The Process
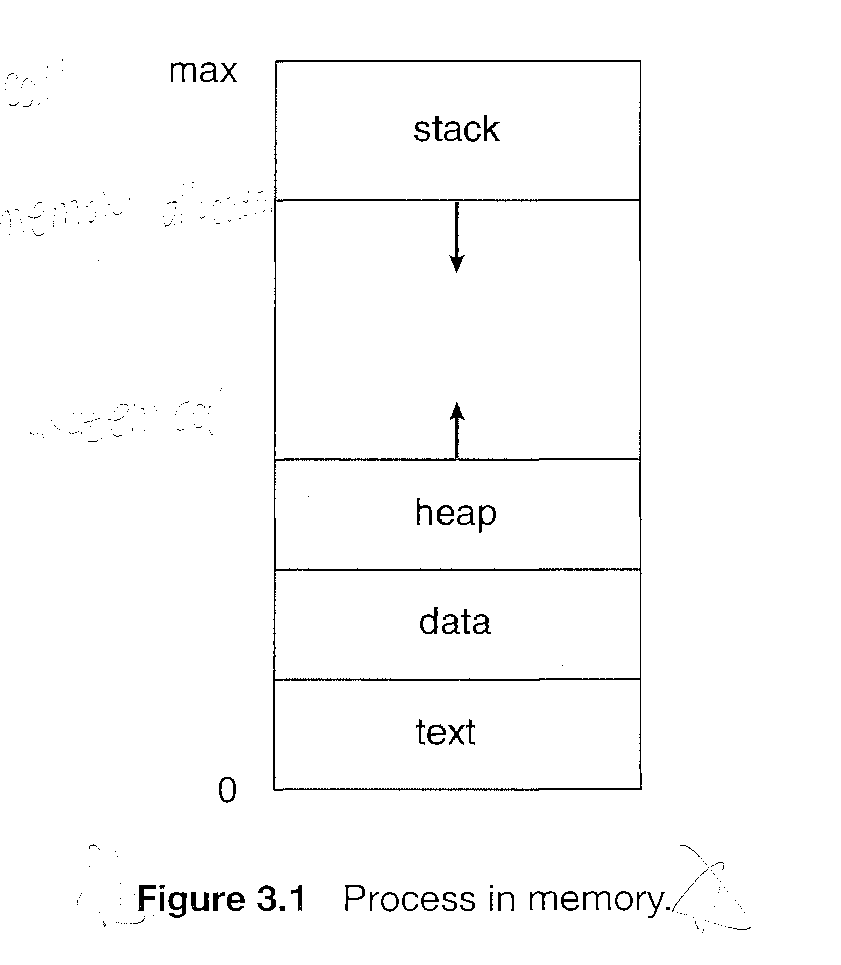
A process is more than the program code, which is sometimes known as the text section.
It also includes the current activity, as represented by the value of the program counter and the contents of the processor's registers.
A process generally also includes the process stack, which contains temporary data (such as function parameters, return addresses, and local variables), and a data section, which contains global variables.
A process may also include a heap, which is memory thatis dynamically allocated during process run time.
Although two processes may be associated with the same program, they are nevertheless considered two separate execution sequences. For instance, several users may be running different copies of the mail program, or the same user may invoke many copies of the Web browser program. Each of these is a separate process; and although the text sections are equivalent, the data, heap, and stack sections vary. It is also common to have a process that spawns many processes as it runs. It is important to realize that only one process can be running on any processor at any instant. Many processes may be ready and waiting
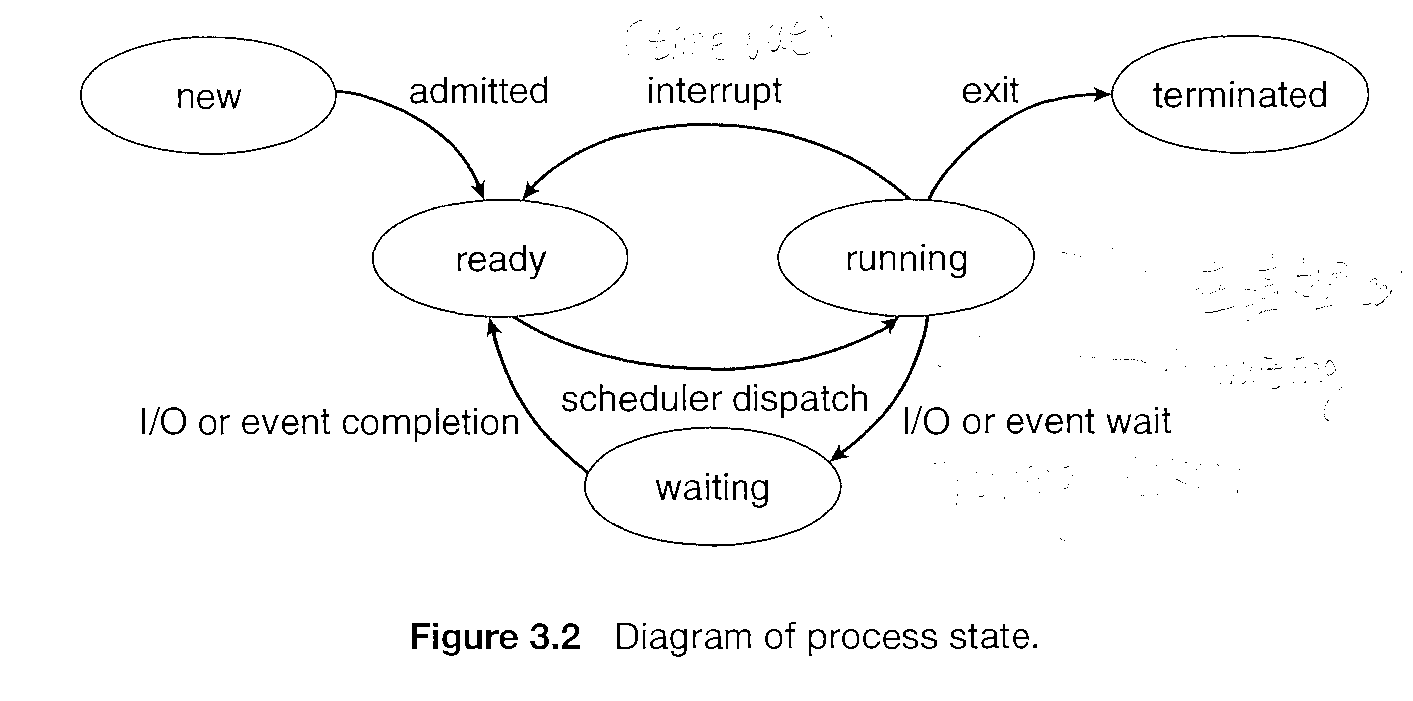
Each process may be in one of the following states:
New. The process is being created.
Running. Instructions are being executed
Waiting. The process is waiting for some event to occur (such as an I/0 completion or reception of a signal).
Ready. The process is waiting to be assigned to a processor.
Terminated. The process has finished execution
Process Control Block
Each process is represented in the OS by a Process control block. The PCB simply serves as the repository for any information that may vary from process to process.
Process state. The state may be new, ready running, waiting, halted, and so on
Program counter. The counter indicates the address of the next instruction to be executed for this process
CPU registers. The registers vary in number and type, depending on the computer architecture. They include accumulators, index registers, stack pointers, and general-purpose registers, plus any condition-code information. Along with the program counter, this state information must be saved when an interrupt occurs, to allow the process to be continued correctly afterward
CPU-scheduling information. This information includes a process priority, pointers to scheduling queues, and any other scheduling parameters.
Memory-management information. This information may include such information as the value of the base and limit registers, the page tables, or the segment tables, depending on the memory system used by the operating system
Accounting information. This information includes the amount of CPU and real time used, time limits, account numbers, job or process numbers, and so on
I/O status information. This information includes the list of I/O devices allocated to the process, a list of open files, and so on
Process Scheduling
The objective of multiprogramming is to have some process nnming at all times, to maximize CPU utilization.
The objective of time sharing is to switch the CPU among processes so frequently that users can interact with each program while it is run.ning.
To meet these objectives, the process scheduler selects an available process (possibly from a set of several available processes) for program execution on the CPU.
For a single-processor system, there will never be more than one running process. If there are more processes, the rest will have to wait until the CPU is free and can be rescheduled.
Scheduling Queues
As processes enter the system, they are put into a job queue, which consists of all processes in the system. The processes that are residing in main memory and are ready and waiting to execute are kept on a list called the ready queue.
The process control block in the Linux operating system is represented by the C structure task_struct.
pid_t pid; //* process identifier // long state; // state of the process // unsigned int time_slice // scheduling information // struct task_struct *parent; // this process's parent // struct list__head children; // this process's children // struct files_struct *files; // list of open files // struct mm_struct *mm; // address space of this process //
Within the Linux kernel, all active processes are represented using a doubly linked list of task_struct, and the kernel maintains a pointer -current - to the process currently executing on the system.
The list of processes waiting for a particular I/0 device is called a device queue. Each device has its own device queue.
A new process is initially put in the ready queue. It waits there until it is selected for execution, or is dispatched.
Once a process terminates it is removed from all queues and has its PCB and resources deallocated.
Schedulers
A process migrates among the various scheduling queues throughout its lifetime. The operating system must select, for scheduling purposes, processes from these queues in some fashion. The selection process is carried out by the appropriate scheduler.
Often, in a batch system, more processes are submitted than can be executed immediately. These processes are spooled to a mass-storage device (typically a disk), where they are kept for later execution.
The long-term scheduler, or job scheduler, selects processes from this pool and loads them into memory for execution.
The short-term scheduler, or CPU scheduler, selects from among the processes that are ready to execute and allocates the CPU to one of them.
The primary distinction between these two schedulers lies in frequency of execution. The short-term scheduler must select a new process for the CPU frequently. A process may execute for only a few milliseconds before waiting for an I/0 request.
Often, the short-term scheduler executes at least once every 100 milliseconds. Because of the short time between executions, the short-term scheduler must be fast.
The long-term scheduler executes much less freqvently; minutes may sep arate the creation of one new process and the next. The long-term scheduler controls the degree of multiprogramming (the number of processes in mem ory).
It is important that the long-term scheduler select a good process mix of I/O-bound (process that perform only I/O) and CPU-bound (processes that do only computations) processes. If all processes are I/0 bound, the ready queue will almost always be empty, and the short-term scheduler will have little to do. If all processes are CPU bound, the I/0 waiting queue will almost always be empty, devices will go unused, and again the system will be unbalanced. The system with the best performance will thus have a combination of CPU-bound and I/O-bound processes.
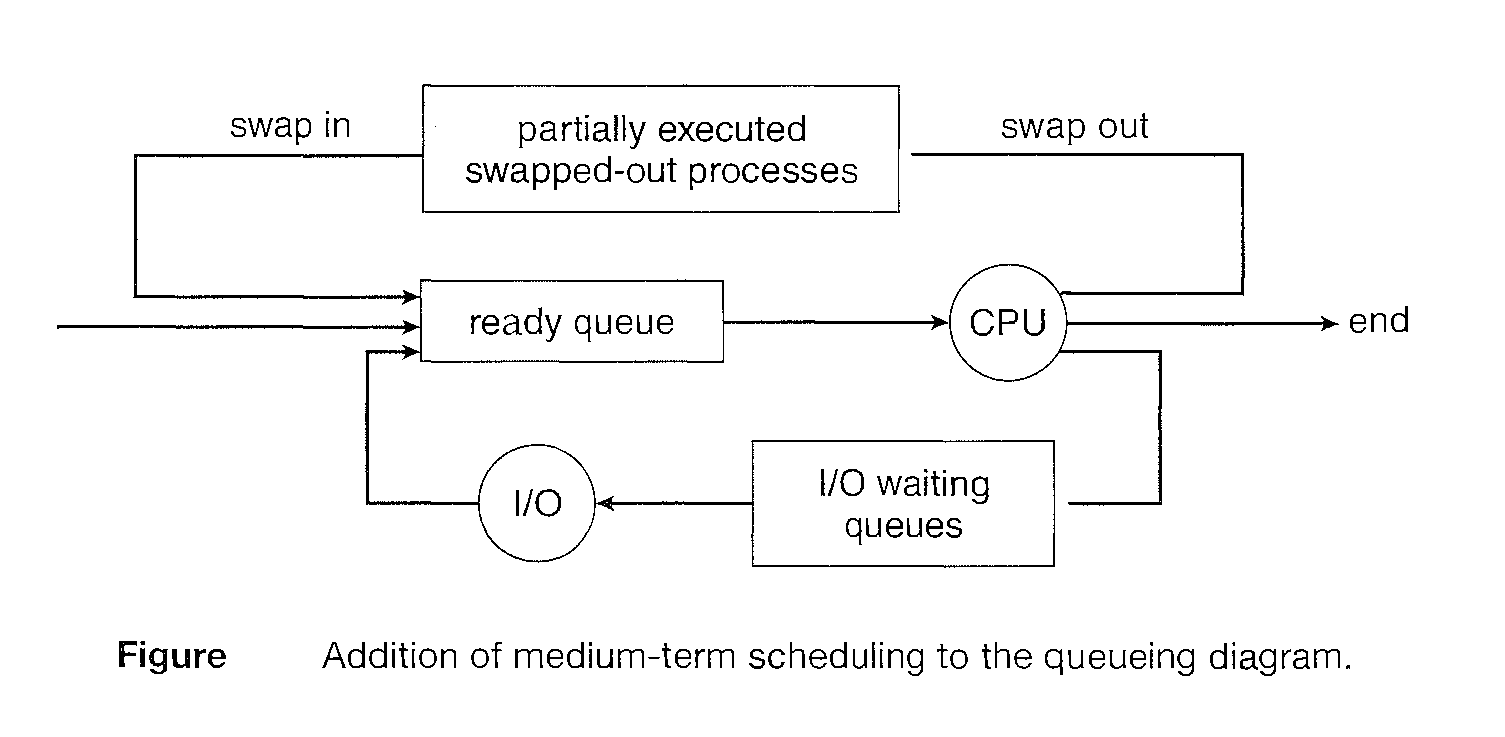
Medium-term scheduler
On some systems, the long-term scheduler may be absent or minimal. For example, time-sharing systems such as UNIX and Microsoft Windows systems often have no long-term scheduler but simply put every new process in memory for the short-term scheduler.
Some operating systems, such as time-sharing systems, may introduce an additional, intermediate level of scheduling.
The key idea behind a medium-term scheduler is that sometimes it can be advantageous to remove processes from mem ory (and from active contention for the CPU) and thus reduce the degree of multiprogramrning.
Later, the process can be reintroduced into memory, and its execution can be continued where it left off. This scheme is called swapping.
The process is swapped out, and is later swapped in, by the medium-term scheduler. Swapping may be necessary to improve the pro cess mix or because a change in memory requirements has overcommitted available memory, requiring memory to be freed up.
Context Switch
Interrupts cause the operating system to change a CPU from its current task and to run a kernel routine. Such operations happen frequently on general-purpose systems. When an interrupt occurs, the system needs to save the current of the process running on the CPU so that it can restore that context when its processing is done, essentially suspending the process and then resuming it.
The context is represented in the PCB of the process; it includes the value of the CPU registers, the process state and memory-management information.
Switching the CPU to another process requires performing a state save of the current process and a state restore of a different process. This task is known as a context switch.
When a context switch occurs, the kernel saves the context of the old process in its PCB and loads the saved context of the new process scheduled to run. Context-switch time is pure overhead, because the system does no useful work while switching