Multithreaded Programming
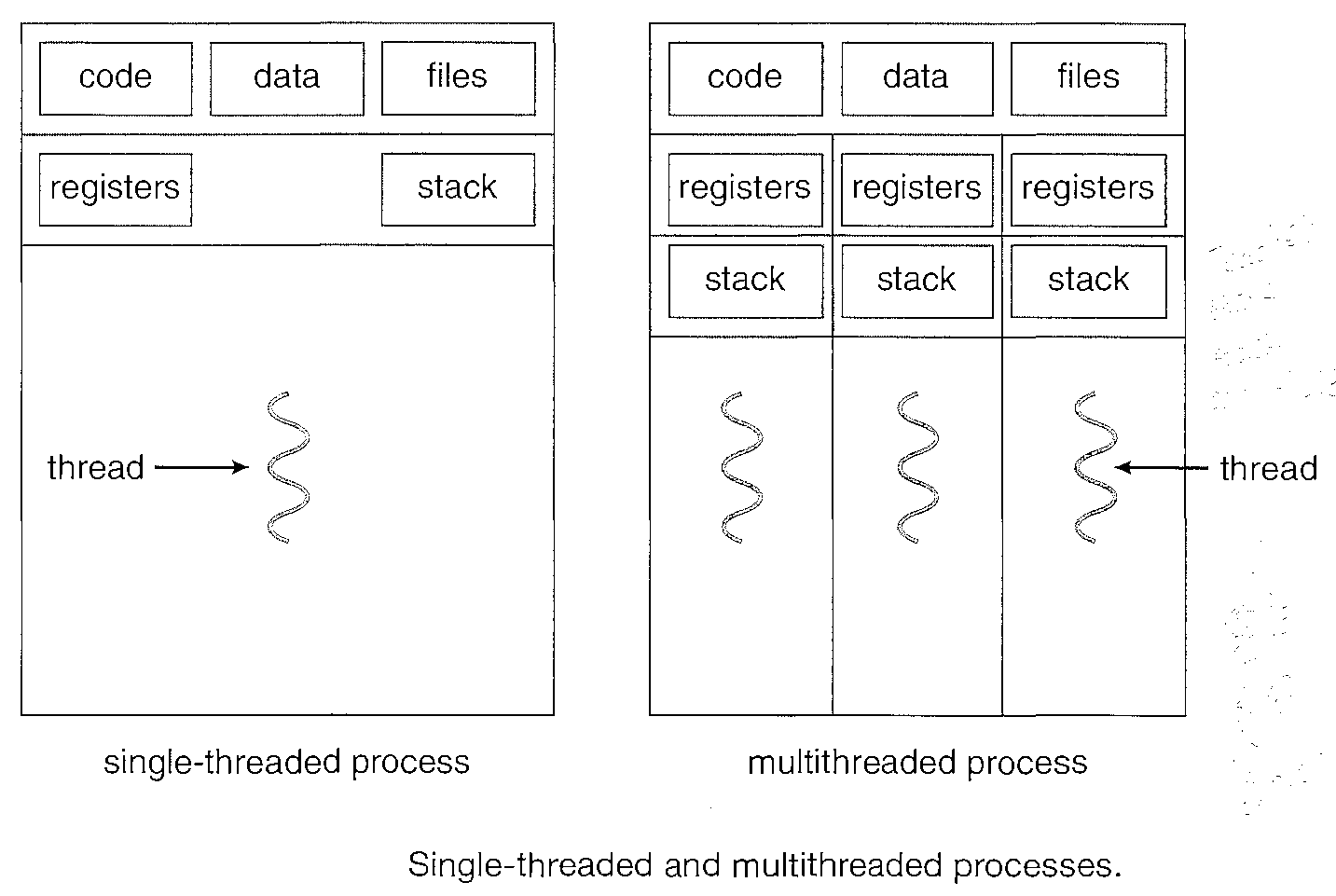
A thread is a basic unit of CPU utilization; it comprises a thread ID, a program counter, a register set, and a stack.
It shares with other threads belonging to the same process its code section, data section, and other operating-system resources, such as open files and signals.
Example :A Web browser might have one thread display images or text while another thread retrieves data from the network
If a server has to serve many requests and it is a single thread then there will be delays in servicing all clients. Hence if a process is busy servicing one client and another request comes the server will create another process to service the new request.
Process creation is time consuming and resource intensive. It is generally more efficient to use one process that contains multiple threads.
If the Web-server process is multithreaded, the server will create a separate thread that listens for client requests. When a request is made, rather than creating another process, the server will create a new thread to service the request and resume listening for additional requests.
Multicore Programming
This places multiple computing cores on a single chip, where each core appears as a separate processor to the operating system.
Multithreaded programming provides a mechanism for more efficient use of multiple cores and improved concurrency.
On a system with multiple cores concurrency means that the threads can run in parallel, as the system can assign a separate thread to each core.
A provides the programmer with an API for creating and managing threads.
Three main thread libraries are in use today: (1) POSIX Pthreads, (2) Win32, and (3) Java.
On Windows systems, Java threads are typically implemented using the Win32 API; UNIX and Linux systems often use Pthreads.
Process Scheduling
CPU scheduling is the basis of multiprogrammed operating systems. By switching the CPU among processes, the operating system can make the computer more productive.
On operating systems that support them., it is kernel-level threads not processes that are being scheduled by the operating system.
In a single-processor system, only one process can run at a time; any others must wait until the CPU is free and can be rescheduled.
The objective of multiprogramming is to have some process running at all times, to maximize CPU utilization.
A process is executed until it must wait, typically for the completion of some I/O request, the CPU then just sits idle
With multiprogramming, we try to use this time productively. Several processes are kept in memory at one time. When one process has to wait, the operating system takes the CPU away from that process and gives the CPU to another process. This pattern continues. Every time one process has to wait, another process can take over use of the CPU.
CPU-i/O Burst Cycle
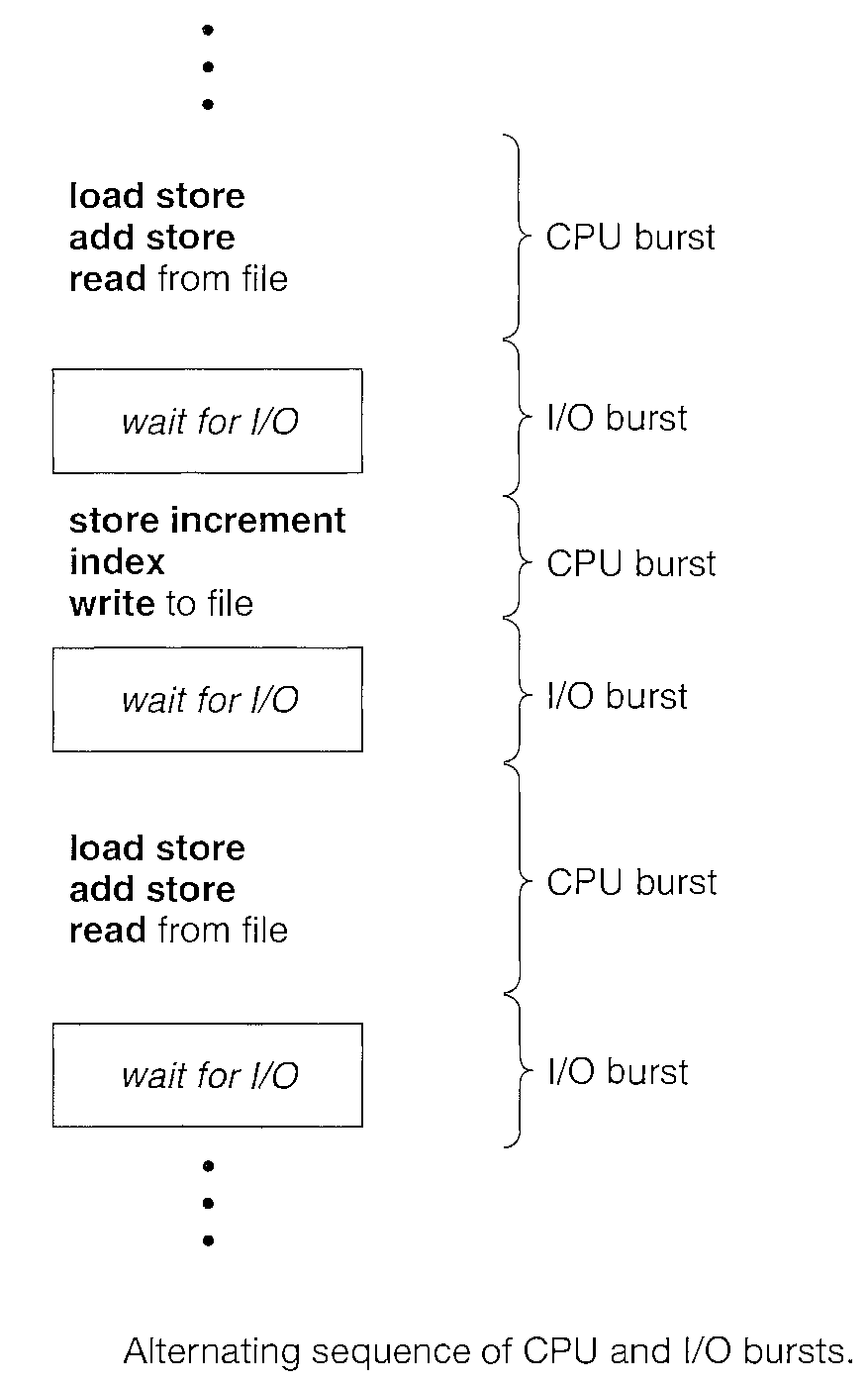
The success of CPU scheduling depends on an observed property of processes: process execution consists of a cycle of CPU execution and I/0 wait.
Processes alternate between these two states. Process execution begins with a CPU burst. That is followed by an I/O burst, which is followed by another CPU burst, then another I/0 burst, and so on. Eventually, the final CPU burst ends with a system request to terminate execution
The durations of CPU bursts have been measured to show a large number of short CPU bursts and a small number of long CPU bursts.
An I/O-bound program typically has many short CPU bursts. A CPU-bound program might have a few long CPU bursts. This distribution can be important in the selection of an appropriate CPU-scheduling algorithm.
CPU Scheduler
Whenever the CPU becomes idle, the operating system must select one of the processes in the ready queue to be executed. The selection process is carried out by the short-term scheduler.
The scheduler selects a process from the processes in memory that are ready to execute and allocates the CPU to that process.
The records in the queues are generally process control blocks (PCBs) of the processes.
Preemptive Scheduling
CPU-scheduling decisions may take place under the following four circum stances:
When a process switches from the running state to the waiting state as the result of an I/0 request or any other reason.
When a process switches from the numing state to the ready state i.e when an interrupt occurs)
When a process switches from the waiting state to the ready state i.e. at completion of I/0)
When a process terminates
For situations 1 and 4, there is no choice in terms of scheduling. A new process (if one exists in the ready queue) must be selected for execution. There is a choice, however, for situations 2 and 3
When scheduling takes place only under circumstances 1 and 4, we say that the scheduling scheme is nonpreemptive or cooperative; otherwise, it is preemptive.
Under nonpreemptive scheduling, once the CPU has been allocated to a process, the process keeps the CPU until it releases the CPU either by terminating or by switching to the waiting state.
Cooperative scheduling does not require the special hardware (for example, a timer) needed for preemptive scheduling.
Problems with Pre-emptive scheduling
Consider the case of two processes that share data. While one is updating the data, it is preempted so that the second process can run.
The second process then tries to read the data, which are in an inconsistent state. In such situations, we need new mechanisms to coordinate access to shared data;
Preemption also affects the design of the operating-system kernel.
During the processing of a system call, the kernel may be busy with an activity on behalf of a process.
Such activities may involve changing important kernel data (for instance, I/0 queues).
Chaos could happen if the process is preempted in the middle of these changes and the kernel (or the device driver) needs to read or modify the same structure.
Dispatcher
The dispatcher is the module that gives control of the CPU to the process selected by the short-term scheduler. This function involves the following:
Switching context
Switching to user mode
Jumping to the proper location in the user program to restart that program
The dispatcher should be as fast as possible, since it is invoked during every process switch. The time it takes for the dispatcher to stop one process and start another running is known as the dispatch latency
Criteria of CPU-scheduling algorithms
CPU utilization : CPU utilization can range from 0 to 100 percent. In a real system, it should range from 40 percent (for a lightly loaded system) to 90 percent (for a heavily used system).
Throughput. The number of processes that are completed per time unit, called throughput. For long processes, this rate may be one process per hour; for short transactions, it may be ten processes per second.
Turnaround time. The interval from the time of submission of a process to the time of completion is the turnaround time. Turnaround time is the sum of the periods spent waiting to get into memory, waiting in the ready queue, executing on the CPU, and doing I/0.
Waiting time. The CPU-scheduling algorithm does not affect the amount of time during which a process executes or does I/0; it affects only the amount of time that a process spends waiting in the ready queue. Waiting time is the sum of the periods spent waiting in the ready queue.
Response time. In an interactive system, turnaround time may not be the best criterion. Often, a process can produce some output fairly early and can continue computing new results while previous results are being output to the user. Thus, another measure is the time from the submission of a request until the first response is produced. This measure, called response time, is the tince it takes to start responding, not the time it takes to output the response. The turnaround time is generally limited by the speed of the output device.
Optimization of CPU Scheduling
It is desirable to maximize CPU utilization and throughput and to minimize turnaround time, waiting time, and response time.
In most cases, we optimize the average measure. However, under some circumstances, it is desirable to optimize the minimum or maximum values rather than the average. For example, to guarantee that all users get good service, we may want to minimize the maximum response time.
For interactive systems (such as time sharing systerns), it is more important to minimize the variance in the response time than to minimize the average response time.
A system with reasonable and predictable response time may be considered more desirable than a system that is faster on the average but is highly variable