Hashing
A hash table is an effective data structure for implementing dictionaries. Although searching for an element in a hash table can take as long as searching for an element in a linked list—Θ(n) time in the worst case—in practice, hashing performs extremely well. The average time to search for an element in a hash table is O(1).
Many applications require a dynamic set that supports only the dictionary operations INSERT, SEARCH, and DELETE. For example, a compiler that translates a programming language maintains a symbol table, in which the keys of elements are arbitrary character strings corresponding to identifiers in the language.
A hash table generalizes the simpler notion of an ordinary array. Directly addressing into an ordinary array makes effective use of our ability to examine an arbitrary position in an array in O(1) time.
Direct addressing is a simple technique that works well when the universe U of keys is reasonably small. Suppose that an application needs a dynamic set in which each element has a key drawn from the universe U = {0,1, 2 ..., m-1} ,where 'm' is not too large. We shall assume that no two elements have the same key
To represent the dynamic set, we use an array, or direct-address table, denoted by T[0...m - 1], in which each position, or slot, corresponds to a key in the universe U. Figure below illustrates the approach; slot k points to an element in the set with key k. If the set contains no element with key k, then T[k] = NIL.
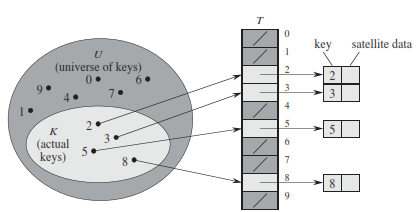
Hash Tables
The downside of direct addressing is obvious: if the universe U is large, storing a table T of size |U| may be impractical given the memory available on a typical computer. Also, the set K of keys actually stored may be so small relative to U that most of the space allocated for T would be wasted.
With direct addressing, an element with key k is stored in slot k. With hashing, this element is stored in slot h(k); that is, we use a hash function h to compute the slot from the key k. Here, h maps the universe U of keys into the slots of a hash table T[0 ... m-1]: h : U -> {0,1 ... m-1}
The size m of the hash table is typically much less than |U| . We say that an element with key k hashes to slot h(k); we also say that h(k) is the hash value of key k.
There is one hitch: two keys may hash to the same slot. We call this situation a collision.
In chaining, we place all the elements that hash to the same slot into the same linked list
The worst-case running time for insertion is O(1). The insertion procedure is fast in part because it assumes that the element x being inserted is not already present in the table; if necessary, we can check this assumption (at additional cost) by searching for an element whose key is x.key before we insert.
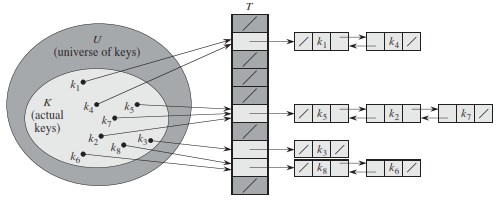
Hash Functions
A good hash function satisfies (approximately) the assumption of simple uniform hashing: each key is equally likely to hash to any of the m slots, independently of where any other key has hashed to.
In the division method for creating hash functions, we map a key k into one of m slots by taking the remainder of k divided by m. That is, the hash function is h(k) = k mod m;
The multiplication method for creating hash functions operates in two steps. First, we multiply the key k by a constant A in the range 0 < A < 1and extract the fractional part of kA. Then, we multiply this value by m and take the floor of the result. In short, the hash function is h(k) = floor(m(kA mod 1))
kA mod 1 = fractional part of kA. An advantage of the multiplication method is that the value of m is not critical. We typically choose it to be a power of 2 (m = 2p for some integer p),
If a malicious adversary chooses the keys to be hashed by some fixed hash function, then the adversary can choose n keys that all hash to the same slot, yielding an average retrieval time of Θ(n). Any fixed hash function is vulnerable to such terrible worst-case behavior; the only effective way to improve the situation is to choose the hash function randomly in a way that is independent of the keys that are actually going to be stored. This approach, called universal hashing, can yield provably good performance on average, no matter which keys the adversary chooses.
In universal hashing, at the beginning of execution we select the hash function at random from a carefully designed class of functions. Because we randomly select the hash function, the algorithm can behave differently on each execution, even for the same input, guaranteeing good average-case performance for any input.
hab = ((ak + p) mod p) mod m
Hpm = {hab : a ∈ Z'p and b ∈ Zp }
p = large prime number such that every key k is in range 0 to p-1
Zp = {0,1, ... , p-1} and Z'p = {1,2, ... , p-1}
Hpm = family of hash functions
Open Addressing - Hash Functions
In open addressing, all elements occupy the hash table itself. That is, each table entry contains either an element of the dynamic set or NIL. When searching for an element, we systematically examine table slots until either we find the desired element or we have ascertained that the element is not in the table.
We could store the linked lists for chaining inside the hash table, in the otherwise unused hash-table slots
To perform insertion using open addressing, we successively examine, or probe, the hash table until we find an empty slot in which to put the key.
Linear probing : In which the interval between probes is fixed — often set to 1. In these schemes, each cell of a hash table stores a single key–value pair. When the hash function causes a collision by mapping a new key to a cell of the hash table that is already occupied by another key, linear probing searches the table for the closest following free location and inserts the new key there. Look-ups are performed in the same way, by searching the table sequentially starting at the position given by the hash function, until finding a cell with a matching key or an empty cell. E.g: H + 1 , H + 2, H + 3 ... H + k
Quadratic probing : In which the interval between probes increases linearly (hence, the indices are described by a quadratic function). E.g: \( H + 1^2 , H + 2^2, H + 3^2 ... H + k^2 \)
Double hashing : In which the interval between probes is fixed for each record but is computed by another hash function.


Binary Search Tree
The search binary tree data structure supports many dynamic-set operations, including SEARCH, MINIMUM, MAXIMUM, PREDECESSOR, SUCCESSOR, INSERT,and DELETE. Thus, we can use a search tree both as a dictionary and as a priority queue.
Basic operations on a binary search tree take time proportional to the height of the tree. For a complete binary tree with n nodes, such operations run in Θ(lg n). If the tree is a linear chain of n nodes, however, the same operations take Θ(n) worst-case time.
A tree by a linked data structure in which each node is an object. In addition to a key and satellite data, each node contains attributes left, right,and p that point to the nodes corresponding to its left child, right child and parent node respectively.
If a child or the parent is missing, the appropriate attribute contains the value NIL. The root node is the only node in the tree whose parent is NIL.
Binary search Tree property states that: Let x be a node in a binary search tree. If y is a node in the left subtree of x, then y.key ≤ x.key. If y is a node in the right subtree of x,then y.key ≥ x.key.
The binary-search-tree property allows us to print out all the keys in a binary search tree in sorted order by a simple recursive algorithm, called an inorder tree walk. This algorithm is so named because it prints the key of the root of a subtree between printing the values in its left subtree and printing those in its right subtree. (Similarly, a preorder tree walk prints the root before the values in either subtree, and a postorder tree walk prints the root after the values in its subtrees.)
Binary Search Tree - Operations
INORDER-TREE-WALK(x)
if x ≠ NIL
INORDER-TREE-WALK(x.left)
print(x.key)
INORDER-TREE-WALK(x.right)
If x is the root of an n-node subtree, then the call INORDER-TREE-WALK(x) takes Θ(n) time.
TREE-SEARCH(x,k)
if x ==NIL OR k == x.key
return x
if k < x.key
return TREE-SEARCH(x.left,k)
else return TREE-SEARCH(x.right,k)
Running time of TREE-SEARCH is O(h), where h is the height of the tree.
TREE-Minimum(x)
while x.left ≠ NIL
x = x.left
return x
TREE-Maximum(x)
while x.right ≠ NIL
x = x.right
return x
Running time of TREE-Minimum(x) and TREE-Minimum(x) is O(h), where h is the height of the tree.
TREE-Successor(x)
if x.right ≠ NIL
return TREE-Minimum(x.right)
y = x.p
while y ≠ NIL and x == y.right
x = y
y = y.p
return y
Running time of TREE-Successor(x) and TREE-Predecessor(x) is O(h), where h is the height of the tree.
TREE-INSERT(T,z)
y = NIL
x = T.root
while x ≠ NIL
y = x
if z.key < x.key
x = x.left
else x = x.right
z.p = y
if y == NIL
T.root = z
else if z.key < y.key
y.left = z
else y.right = z
Like the other primitive operations on search trees, the procedure T REE-INSERT runs in O(h) time on a tree of height h.
Binary Search Tree - Deletion Operation
If z (node to be deleted) has no children, then we simply remove it by modifying its parent to replace z with NIL as its child.
If z has just one child, then we elevate that child to take z’s position in the tree by modifying z’s parent to replace z by z’s child.
If z has two children, then we find z’s successor y — which must be in z’s right subtree - and have y take z’s position in the tree. The rest of z’s original right subtree becomes y’s new right subtree, and z’s left subtree becomes y’s new left subtree.
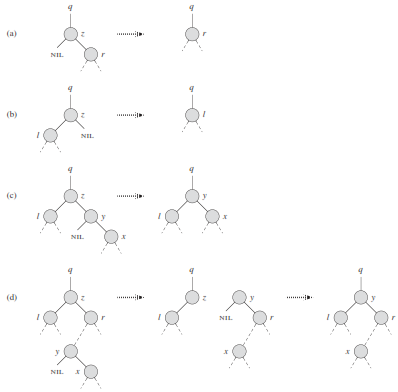
TREE-DELETE(T,z)
if z.LEFT == NIL
TRANSPLANT(T,z,z.right)
elseif z.RIGHT == NIL
TRANSPLANT(T,z,z.left)
else y = TREE-MINIMUM.(z.right)
if y.p ≠ z
TRANSPLANT(T,y,y.right)
y.right = z.right
y.right.p = y
TRANSPLANT(T,z,y)
y.left = z.left
y.left.p = y
TRANSPLANT(T,u,v)
if u.p == NIL
T.root = v
elseif u == u.p.left
u.p.left = v
else u.p.right = v
if v ≠ NIL
v.p = u.p
TREE-DELETE runs in O(h) time on a tree of height h.
Binary Search Tree - Solved Questions
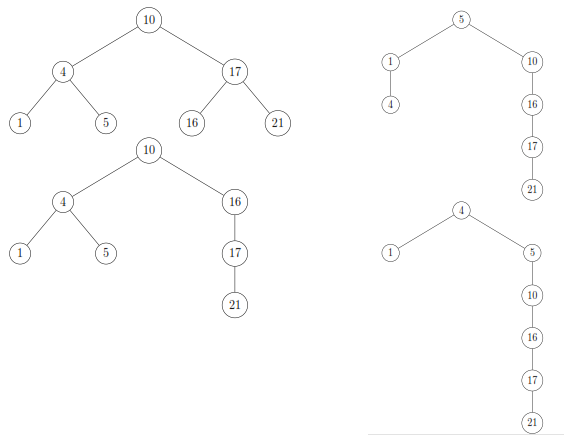
Q. For the set of {1; 4; 5; 10; 16; 17; 21} of keys, draw binary search trees of heights 2, 3, 4, 5, and 6.
Q. Suppose that we have numbers between 1 and 1000 in a binary search tree, and we want to search for the number 363. Which of the following sequences could not be the sequence of nodes examined?
a. 2, 252, 401, 398, 330, 344, 397, 363.
b. 924, 220, 911, 244, 898, 258, 362, 363.
c. 925, 202, 911, 240, 912, 245, 363.
d. 2, 399, 387, 219, 266, 382, 381, 278, 363.
e. 935, 278, 347, 621, 299, 392, 358, 363.
Option c could not be the sequence of nodes explored because we take the left child from the 911 node, and yet somehow manage to get to the 912 node which cannot belong the left subtree of 911 because it is greater. Option e is also impossible because we take the right subtree on the 347 node and yet later come across the 299 node.
Q. Write recursive versions of TREE-MINIMUM and TREE-MAXIMUM.
Algorithm 3: TREE-MINIMUM(x)
if x:left ≠ NIL then
return TREE - MINIMUM(x.left)
else
return x
end if
Algorithm 4: TREE-MAXIMUM(x)
if x:right ≠ NIL then
return TREE - MAXIMUM(x.right)
else
return x
end if
Write the TREE-PREDECESSOR procedure.
Algorithm 5: TREE-PREDECESSOR(x)
if x:left ≠ NIL then
return TREE - MAXIMUM(x.left)
end if
y = x.p
while y ≠ NIL and x == y.left do
x = y
y = y.p
end while
return y
Q.8 The height of a tree is the length of the longest root-to-leaf path in it. The maximum and minimum number of nodes in a binary tree of height 5 are.(GATE 2015 Set1)
63 and 6
64 and 5
32 and 6
31 and 5
Ans (A)
Number of nodes is maximum for a perfect binary tree. A perfect binary tree of height h has \( 2^h+1 - 1 \) nodes Number of nodes is minimum for a skewed binary tree. A perfect binary tree of height h has h+1 nodes.
Q. We can sort a given set of n numbers by first building a binary search tree containing these numbers (using TREE-INSERT repeatedly to insert the numbers one by one) and then printing the numbers by an inorder tree walk. What are the worstcase and best-case running times for this sorting algorithm?
The worst case is that the tree formed has height n because we were inserting them in already sorted order. This will result in a runtime of Θ(n2). In the best case, the tree formed is approximately balanced. This will mean that the height doesn't exceed O(lg(n)). Note that it can't have a smaller height, because a complete binary tree of height h only has Θ(2h) elements. This will result in a rutime of O(n lg(n).
Solved Question Papers
Q.2 What are the worst-case complexities of insertion and deletion of a key in a binary search tree?(Gate 2015 Set1)
Θ(logn) for both insertion and deletion
Θ(n) for both insertion and deletion
Θ (n) for insertion and (logn) for deletion
Θ(logn) for insertion and (n) for deletion
Ans (B)
The time taken by search, insert and delete on a BST is always proportional to height of BST. Height may become O(n) in worst case. 4
Q.1.Let G = (V,E) be a graph. Define ξ(G) = ∑ d id x d, where id is the number of vertices of degree d in G. If S and T are two different trees with ξ(S) = ξ(T),then(GATE 2010)
|S| = 2|T|]
|S| = |T|-1
|S| = |T|
|S| = |T|+1
Ans . 3
Since δ(V) = 2e
ξ(S) = ξ(T)
Hence, |S| = |T|
Q.5.A hash table of length 10 uses open addressing with hash function h(k)=k mod 10, and linear probing. After inserting 6 values into an empty hash table, the table is as shown below. Which one of the following choices gives a possible order in which the key values could have been inserted in the table?(GATE 2010)

46, 42, 34, 52, 23, 33
34, 42, 23, 52, 33, 46
46, 34, 42, 23, 52, 33
42, 46, 33, 23, 34, 52
Ans . 3
The sequence (A) doesn’t create the hash table as the element 52 appears before 23 in this sequence.
The sequence (B) doesn’t create the hash table as the element 33 appears before 46 in this sequence.
The sequence (C) creates the hash table as 42, 23 and 34 appear before 52 and 33, and 46 appears before 33.
The sequence (D) doesn’t create the hash table as the element 33 appears before 23 in this sequence.
Hence 3.
Q.6.How many different insertion sequences of the key values using the same hash function and linear probing will result in the hash table shown above?(GATE 2010)
10
20
30
40
Ans . 3
In a valid insertion sequence, the elements 42, 23 and 34 must appear before 52 and 33, and 46 must appear before 33.
Total number of different sequences = 3! x 5 = 30
In the above expression, 3! is for elements 42, 23 and 34 as they can appear in any order, and 5 is for element 46 as it can appear at 5 different places.
Hence 3.
Q. Consider the tree arcs of a BFS traversal from a source node W in an
unweighted, connected, undirected graph. The tree T formed by the tree arcs
is a data structure for computing.
(GATE 2014 SET 2)
The shortest path between every pair of vertices.
The shortest path from W to every vertex in graph.
The shortest paths from w to only nodes that are leaves of T.
The longest path in graph
Ans . 2
solution
BFS produces shortest path from source to all other vertices
Q.5An operator delete (i) for a binary heap data structure is to be designed to delete the item in the ith node. Assume that the heap is implemented in an array and i refers to the ith index of the array. If the heap tree has depth d (number of edges on the path from the root to the farthest leaf), then what is the time complexity to refix the heap efficiently after the removal of the element? (GATE 2016 SET A)
O(1)
O(d) but not O(1)
O(2d) but not O(d)
O(d2d) but not O(2d)
Ans : (B)
Solution steps:
The time complexity to refix the heap efficeincy after removal of element is always in the worst case is proportional to the depth of heap. Thus O(d) but not O(1).
Q. The pre order traversal of a binary search tree is given by 12, 8, 6, 2, 7, 9, 10, 16, 15, 19, 17, 20. Then the post-order traversal of this tree is: (GATE 2017 Paper 2)
-
2,6,7,8,9,10,12,15,16,17,19,20
-
2,7,6,10,9,8,15,17,20,19,16,12
-
7,2,6,8,9,10,20,17,19,15,16,12
-
7,6,2,10,9,8,15,16,17,20,19,12
Ans. 2
Given: Preorder: 12, 8, 6, 2, 7, 9, 10, 16, 15, 19, 17, 20
BST in order will give ascending order
In order: 2, 6, 7, 8, 9, 10, 12, 15, 16, 17, 19, 20
Corresponding BST is
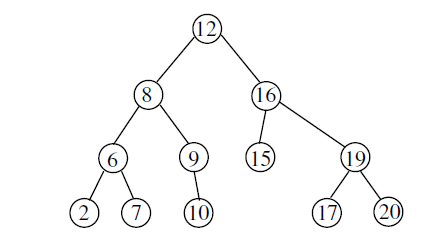
Post order is 2, 7, 6, 10, 9, 8, 15, 17, 20, 19, 16, 12
Q. Which one of the following is the tightest upper bound that represents the time complexity of inserting an object into a binary search tree of n nodes? (GATE 2013 SET D)
\(O(1)\)
\(O(\log n)\)
\(O(n)\)
\(O(n \log n)\)
Ans . 3
When inserting a new element we need to find it’s position in a tree.Time for this operation is upper bounded by the height of the binary tree.
Since, the tree is unbalanced, we don’t need to perform balancing operations upon insertion, so only time consumes in finding its right position.
The time consumed in finding the position is equal to height of the tree.
For binary search tree on n nodes, the tightest upper bound to insert a node is O(n)
Q. The preorder traversal sequence of a binary search tree is 30, 20, 10, 15, 25, 23, 39, 35, 42. Which one of the following is the postorder traversal sequence of the same tree? (GATE 2013 SET D)
10,20,15,23,25,35,42,39,30
15,10,25,23,20,42,35,39,30
15,20,10,23,25,42,35,39,30
15,10,23,25,20,35,42,39,30
Ans . 4
Preorder:30,20,10,15,25,23,39,35,42
Inorder:10,15,20,23,25,30,35,39,42
Q.3 We are given a set of n distinct elements and an unlabeled binary tree with n nodes. In how many ways can we populate the tree with the given set so that it becomes a binary search tree? (GATE 2011)
0
1
n!
(1/(n+1)).2nCn
Ans .(D)
Q. You are given the postorder traversal, P, of a binary search tree on the n elements 1, 2, ..., n. You have to determine the unique binary search tree that has P as its postorder traversal. What is the time complexity of the most efficient algorithm for doing this?(GATE Paper-2008)
O(Logn)
O(n)
O(nLogn)
none of the above, as the tree cannot be uniquely determined
Ans . (2)
Explanation :
One important thing to note is, it is Binary Search Tree, not Binary Tree. In BST, inorder traversal can always be obtained by sorting all keys.
Q.How many distinct binary search trees can be created out of 4 distinct keys?(GATE 2005)
- 5
- 14
- 24
- 42
Ans. 14
Solution:- If there are n nodes, then for each choice of root node, there are n – 1 non-root nodes and these non-root nodes must be partitioned into those that are less than a chosen root and those that are greater than the chosen root.
Q.2 Suppose we have a balanced binary search tree T holding n numbers. We are given two numbers L and H and wish to sum up all the numbers in T that lie between L and H. Suppose there are m such numbers in T. If the tightest upper bound on the time to compute the sum is O(nalogb n + mc logd n), the value of a + 10b + 100c + 1000d is ____. (GATE 2014 SET 3)
60
110
210
50
Ans . 110

Q.5 Consider the pseudocode given below. The function DoSomething() takes as argument a pointer to the root of an arbitrary tree represented by the leftMostChild-rightSibling representation. Each node of the tree is of type treeNode.

When the pointer to the root of a tree is passed as the argument to DoSomething, the value returned by the function corresponds to the(GATE 2014 SET 3)
number of internal nodes in the tree.
height of the tree.
number of nodes without a right sibling in the tree.
number of leaf nodes in the tree.
Ans . 4.number of leaf nodes in the tree.
The function counts leaf nodes for a tree represented using leftMostChild-rightSibling representation.
Below is function with comments added to demonstrate how function works.

Q. Which one of the following is a key factor for preferring B+ -trees to binary search trees for indexing database relations? (GATE 2005)
Database relations have a large number of records
Database relations are sorted on the primary key
B+ -trees require less memory than binary search trees
Data transfer from disks is in blocks
Ans . (d)
Database queries can be executed faster when disk reads and writes whole blocks of data at once.But, nodes of binary search tree store a single key. So, in case of binary search tree, data transfer can not be done in blocks. B+ tree is a balanced tree and multiple keys are stored in each node of a B+ tree. Thus, disk can transfer data in blocks when B+ tree is used for indexing database relations.
Q.8 Postorder traversal of a given binary search tree T produces the following sequence of keys
10, 9, 23, 22, 27, 25, 15, 50, 95, 60, 40, 29
Which one of the following sequences of keys can be the result of an inorder traversal of the tree T? (GATE 2005)
9, 10, 15, 22, 23, 25, 27, 29, 40, 50, 60, 95
9, 10, 15, 22, 40, 50, 60, 95, 23, 25, 27, 29
29, 15, 9, 10, 25, 22, 23, 27, 40, 60, 50, 95
95, 50, 60, 40, 27, 23, 22, 25, 10, 9, 15, 29
Ans . (a)
Inorder traversal of a BST always gives elements in increasing order. Among all four options, (a) is the only increasing order sequence.
Q.9 In a complete k-ary tree, every internal node has exactly k children. The number of leaves in such a tree with n internal nodes is (GATE 2005)
nk
(n – 1)k + 1
n(k – 1) + 1
n(k – 1)
Ans . (c)
Let T(n) be number of leaves in a tree having n internal nodes.
T(n) = T(n-1) - 1 + k = T(n-1) + k -1
= T(n-2) + 2*(k-1) Solving By Substitution Method
= T(n-3) + 3*(k-1)
.
.
.
= T(n-(n-1)) + (n-1)*(k-1)
= T(1) + (n-1)*(k-1)
= k + (n-1)*(k-1) Forming Base Case : T(1) = k
= n(k – 1) + 1
Q.1 Which one of the following is the tightest upper bound that represents the time complexity of inserting an object into a binary search tree of n nodes? (GATE 2013)
O(1)
- O(log n)
- O(n)
- O(n log n)
Ans . 3
To insert an element, we need to search for its place first. The search operation may take O(n) for a skewed tree like following.
To insert 50, we will have to traverse all nodes. 10 - 20 - 30 - 40
Solution:
Q. The height of a binary tree is the maximum number of edges in any root to leaf path. The maximum number of nodes in a binary tree of height h is: (GATE 2007)
-
\(2^{h}-1\)
-
\(2^{h-1}-1\)
-
\(2^{h+1}-1\)
-
\(2^{h+1}\)
Ans. 3
Q. The worst case running time to search for an element in a balanced binary search tree with \(n^{2n}\) elements is (GATE 2012)
Θ(n log n)
Θ\((n2^n)\)
Θ(n)
Θ(log n)
Ans . 3
The worst case search time in a balanced BST on ‘x’ nodes is log x.
In the given senario
x = \(n2^n\), then log(\(n2^n\)) = log n + log(\(2^n\)) = log n + n log 2 = log n + n = θ(n)
Que 4: The worst case running time to search for an element in a balanced binary search tree with n2n elements is (GATE 2016 SET B)
Θ(n log n)
Θ(n2n)
Θ(n)
Θ(log n)
Ans . C
The worst case search time in a balanced BST on 'x' nodes is logx. So, if x = n2n, then log(n2n) = logn + log(2n) = logn + n = θ(n)