GATE-CS-2002
Ans .
C
- Explanation :
Rank of the matrix is defined as the maximum number of linearly independent vectors (or) the number of non-zero rows in its row-echelon matrix. A = | 1 1| | 0 0| Since, the matrix A is already in echelon form, Just count the number of non-zero rows to get the rank of the matrix = 1.
Ans .
C
- Explanation :
The error term for the Trapezoidal rule involves f00, the rule gives the exact result when applied to any function whose second derivative is identically zero. That is, the Trapezoidal rule gives the exact result for polynomials of degree up to or equal to one..
Ans .
B
- Explanation :
T (2k) = 3 T (2k-1) + 1 = 32 T (2k-2) + 1 + 3 = 33 T (2k-3) + 1 + 3 + 9 . . . (k steps of recursion (recursion depth)) = 3k T (2k-k) + (1 + 3 + 9 + 27 + ... + 3k-1) = 3k + ( ( 3k - 1 ) / 2 ) = ( (2 * 3k) + 3k - 1 )/2 = ( (3 * 3k) - 1 ) / 2 = (3k+1 - 1) / 2 Hence, B is the correct choice. .
Ans .
D
- Explanation :
We need 3 colors to color a odd cycle and 2 colors to color an even cycle.
Ans .
D
- Explanation :
Singly linked list has uni - directional flow, i.e., it has only one pointer for moving (the next pointer). In the worst case, for searching an element in the singly linked list, we will have to traverse the whole list (the case when the required element is either the last element or is not present in the list). So, in the worst case for a list of length n, we will have to go to each node for comparison and thus, we would be needing 'n' comparisons. Thus, D is the correct choice.
Ans .
B
- Explanation :
A group is a set of elements such that any two elements of the group combine to form a third element of the same group. Also, a group must satisfy certain properties: Closure Property - Any two elements of the set when operated open by an operator form a third element that must also be in the set. Associative Property - For an expression with three or more operands having the same operator between them, the order of operation does not matter as long as the sequence of operands are not changed. For example, (a + b) + c = a + (b + c). Identity element Property - Each set must have an identity element, which is an element of the set such that when operated upon with another element of the set, it gives the element itself. For example, a + 0 = a. Here, 0 is the identity element. Invertibility Property - For each element of the set, inverse should exist. Now, for the given statements, we have A is incorrect as it does not satisfies closure property. If we take two negative numbers and multiply them, we get a positive number which is not in the set. B is correct. The matrices in the set must be non - singular, i.e., their determinant should not be zero, for the inverse to exist (Invertibility Property). C is incorrect as the inverse of a singular (determinant = 0) matrix does not exist (Invertibility Property violated). Thus, B is the correct option
Ans .
B
- Explanation :
Pushdown automata is used for context free languages, i.e., languages in which the length of elements is unrestricted and length of one element is related to other. To resolve this problem, we use a stack with no restrictions on length. But in the given case, length of stack is restricted. Thus, this pushdown automata can only accept languages which can also be accepted by finite state automata and a finite state automata accepts only regular languages. Thus, B is the correct choice.
Ans .
A
- Explanation :
The statement "If X then Y unless Z" means, if Z doesn't occur, X implies Y i.e. ¬Z→(X→Y), which is equivalent to Z∨(X→Y) (since P→Q ≡ ¬P∨Q), which is then equivalent to Z∨(¬X∨Y). Now we can look into options which one matches with this. So option (a) is (X∧¬Z)→Y = ¬((X∧¬Z))∨Y = (¬X∨Z)∨Y, which matches our expression. So option A is correct.
Ans .
D
- Explanation :
Program counter is the register which has the next location of the program to be executed next. JMP & CALL changes the value of PC. PCHL instruction copies content of registers H & L to PC. ADD instruction after completion increments program counter. So program counter is modified in all cases. Hence (D) is correct option.
Ans .
A
- Explanation :
In serial communication, the sender & receiver needs to be synchronized with each other. '0' is added in the beginning of data as start bit and '1' is added at the end as a stop bit. The start signal tells the receiver about the arrival of data and the stop signal resets the receiver's state for the arrival of a new data. Thus, in serial communication receiver is to be synchronized for byte reception.
Ans .
B
- Explanation :
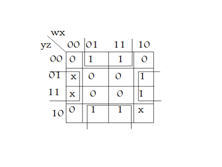 .
.
Ans .
C
- Explanation :
Instruction Cache - Used for storing instructions that are frequently used Instruction Register - Part of CPU's control unit that stores the instruction currently being executed Instruction Opcode - It is the portion of a machine language instruction that specifies the operation to be performed Translation Lookaside Buffer - It is a memory cache that stores recent translations of virtual memory to physical addresses for faster access. So, all the above except Instruction Opcode are memories. Thus, C is the correct choice..
Ans .
B
- Explanation :
We have 0.2510 0.25 * 2 = 0.50 0 (whole part) 0.50 * 2 = 1.00 1 (whole part) So, 0.2510 = 0.012 Thus, B is the correct choice.
Ans .
D
- Explanation :
We have -1510 = 1 11112 1's complement of -15 = 1 0000 (Here, 1 represents negative sign) 2's complement of -15 = 1 0001 Hence, D is the correct choice.
Ans .
D
- Explanation :
Sign extension is the operation, in computer arithmetic, of increasing the number of bits of a binary number while preserving the number's sign (positive/negative) and value. This is done by appending digits to the most significant side of the number, following a procedure dependent on the particular signed number representation used.
Ans .
B
- Explanation :
The portion of the stack used for an invocation of a function is called the function’s stack frame or activation record. An activation record is another name for Stack Frame. It's the data structure that composes a call stack. It is generally composed of:
Locals to the callee
Return address to the caller
Parameters of the callee
The Call Stack is thus composed of any number of activation records that get added to the stack as new subroutines are added, and removed from the stack (usually) as they return. In C language the program execution starts with main function, so it is the first activation record in the function stack. Now looking at each option-: Option a- The statement is false as any number of functions can be called from the main. It might not be necessary that at-most one activation record exist and activation record of main. For example- as in case of recursion.
Recurse (int n)
{
if(n==0)
return ;
else
recurse(n-1);
}
In above example activation record of main and recurse(4) will have activation record of recurse(5), recurse(6) (more than one) if we pass n=6 initially to the function. Option b- True as soon as a function is called its activation record is created in the function stack. Option c- In C language variables are statically scoped not dynamically, the global variables are statically assigned address space when the execution starts not depending on when and where they are used. Option d- The functions are stored in the same each time recursive call is made, considering the above recurse function
Recurse(4)
Recurse(5)
Recurse(6)
Main().
Ans .
D
- Explanation :
The result is updated since the updated values are returned back to the original variable. In call by reference, any change in the variable reflects immediately.
Ans .
A
- Explanation :
If a relational schema is in BCNF then all redundancy based on functional dependency has been removed, although other types of redundancy may still exist.
Ans .
C
- Explanation :
A query can be formulated in relational calculus if and only if it can be formulated in relational algebra. So, relational algebra has the same power as relational calculus.
But, it is possible to write syntactically correct relational calculus queries that have infinite number of answers. Such queries are unsafe. Queries that have an finite number of answers are safe relational calculus queries.
Thus, Relational algebra has the same power as safe relational calculus.
Thus, option (C) is the answer.
Ans .
B
- Explanation :
is flagged when the carries from sign bit and previous bit DO NOT match.
Ans .
B
- Explanation :
Round Robin - Preemption takes place when the time quantum expires First In First Out - No Preemption, the process once started completes before the other process takes over Multi Level Queue Scheduling - Preemption takes place when a process of higher priority arrives Multi Level Queue Scheduling with Feedback - Preemption takes a place when process of higher priority arrives or when the quantum of high priority queue expires and we need to move the process to low priority queue So, B is the correct choice. Please comment below if you find anything wrong in the above post.
Ans .
D
- Explanation :
The optimal page replacement algorithm will select the page whose next occurrence will be after the longest time in future. For example, if we need to swap a page and there are two options from which we can swap, say one would be used after 10s and the other after 5s, then the algorithm will swap out the page that would be required 10s later. Thus, B is the correct choice. Please comment below if you find anything wrong in the above post.
Ans .
B
- Explanation :
(b) is the answer. Absolute addressing mode means address of operand is given in the instruction. (a) operand is inside the instruction -> immediate addressing (c) -> register addressing (d) -> implicit addressing
Ans .
B
- Explanation :
Background required - Basic Combinatorics Since the given graph is undirected, that means the order of edges doesn't matter. Since we have to insert an edge between all possible pair of vertices, therefore problem reduces to finding the count of the number of subsets of size 2 chosen from the set of vertices. Since the set of vertices has size n, the number of such subsets is given by the binomial coefficient C(n,2) (also known as "n choose 2"). Using the formula for binomial coefficients, C(n,2) = n(n-1)/2
Ans .
A
- Explanation :
F = (A1’A0’I0 + A1’A0I1 + A1A0’I2 + A1A0I3) * EN F = (XYZ' +XYZ + Y'ZY + ZY')Z' F = (XYZ' +XYZ + ZY'(Y + 1))Z' F = (XYZ' +XYZ + ZY' * 1)Z' F = (XY(Z’ + Z) + ZY’)Z’ F = (XY + ZY’)Z’ F = XYZ’ + 0 F = XYZ' Thus, option (A) is correct.
Ans .
C
- Explanation :
Simplified expression for given function 'g' is :
g = f( f(x + y, y), z) g = f( ((x + y)’ + y), z) g = f( (x’y’ + y), z) g = f( ((y + y’) * (x’ + y)), z) g = f( (1 * (x’ + y)), z) g = f( (x’ + y), z) g = (x’ + y)’ + z) g = xy’ + z
Thus, option (C) is correct.
Ans .
C
- Explanation :
First we load 5D in L register But we have not stored it to the accumulator So, when we load 6B in L register, it overwrites 5D in L register and the same value 6BH is copied to accumulator Now A = 6BH L = 6BH ADD L i.e. A = A + L It will generate internal carry i.e. B + B = 22 i.e. 22 - 16 = 6 adding 2 to 6 + 6 => we get 14 => D Hence answer is D6 Since there is internal carry only, no final carry as 14 < 16 So, Auxillary carry flag(AC) = 1 Carry Flag(CY) = 0
Ans .
D
- Explanation :
We assume the input string to be 1101. 1. (A, 1) --> (B, 01) Here, previous input bit + present input bit = 0 + 1 = 01 = output
2. (B, 1) --> (C, 10) Here, previous input bit + present input bit = 1 + 1 = 10 = output
3. (C, 0) --> (A, 01) Here, previous input bit + present input bit = 1 + 0 = 01 = output
4. (A, 1) --> (B, 01) Here, previous input bit + present input bit = 0 + 1 = 01 = output
Thus, option (A) is correct.
Ans .
D
- Explanation :
Pipelining is a method to execute a program breaking it in several independent sequence of stages. In that case pipeline stages can’t have different delays ,no dependency among consecutive instructions and sharing of hardware resources should not be there. So option (D) is correct
Ans .
D
- Explanation :
In horizontal microprogramming the instruction size is less as compared to vertical microprogramming. So, there is no need for decoding.
But, one bit is used for all control signals to execute the microinstruction. If the bit is set to ‘1’ the control signal field is activated. If the bit is set to ‘0’ the control signal field is deactivated
Ans .
D
- Explanation :
Program counter is the register which has the next location of the program to be executed next. JMP & CALL changes the value of PC. PCHL instruction copies content of registers H & L to PC. ADD instruction after completion increments program counter. So program counter is modified in all cases. Hence (D) is correct option.
Ans .
D
- Explanation :
Address of a[40][50] =
Base address + 40*100*element_size + 50*element_size
0 + 4000*1 + 50*1
4050
Ans .
D
- Explanation :
Let L be the number of leaf nodes and I be the number of internal nodes, then following relation holds for above given tree
L = (3-1)I + 1 = 2I + 1
Total number of nodes(n) is sum of leaf nodes and internal nodes
n = L + I
After solving above two, we get L = (2n+1)/3
Ans .
A
- Explanation :
Let expected number of comparisons be E. Value of E is sum of following expression for all the possible cases.
number_of_comparisons_for_a_case * probability_for_the_case
Case 1
If A[i] is found in the first attempt
number of comparisons = 1
probability of the case = 1/n
Case 2
If A[i] is found in the second attempt
number of comparisons = 2
probability of the case = (n-1)/n*1/n
Case 3
If A[i] is found in the third attempt
number of comparisons = 2
probability of the case = (n-1)/n*(n-1)/n*1/n
There are actually infinite such cases. So, we have following infinite series for E.
E = 1/n + [(n-1)/n]*[1/n]*2 + [(n-1)/n]*[(n-1)/n]*[1/n]*3 + …. (1)
After multiplying equation (1) with (n-1)/n, we get
E (n-1)/n = [(n-1)/n]*[1/n] + [(n-1)/n]*[(n-1)/n]*[1/n]*2 +
[(n-1)/n]*[(n-1)/n]*[(n-1)/n]*[1/n]*3 ……….(2)
Subtracting (2) from (1), we get
E/n = 1/n + (n-1)/n*1/n + (n-1)/n*(n-1)/n*1/n + …………
The expression on right side is a GP with infinite elements. Let us apply the sum formula (a/(1-r))
E/n = [1/n]/[1-(n-1)/n] = 1
E = n
Ans .
D
- Explanation :
Let L be the number of leaf nodes and I be the number of internal nodes, then following relation holds for above given tree
L = (3-1)I + 1 = 2I + 1
Total number of nodes(n) is sum of leaf nodes and internal nodes
n = L + I
After solving above two, we get L = (2n+1)/3
Ans .
B
- Explanation :
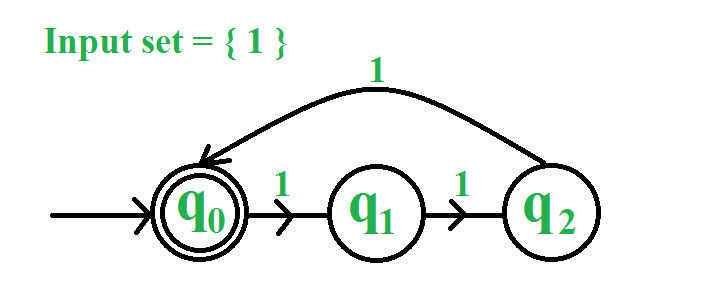
Ans .
A
- Explanation :
http://en.wikipedia.org/wiki/Recursive_language#Closure_properties
Ans .
A
- Explanation :
X2 = 3
f(x) = X2 - 3
Xn + 1 = Xn - (Xn2 - 3) / (2*Xn)
= (Xn/2) + 3/(2xn)
Ans .
C
- Explanation :
There are only two cases (when all head or all tail) against the given output. So the required probability is (16-2)/16 = 7/8.
Ans .
D
- Explanation :
Reflexive : A relation is reflexive if every element of set is paired with itself. Here none of the element of A is paired with themselves, so S is not reflexive.
Symmetric : This property says that if there is a pair (a, b) in S, then there must be a pair (b, a) in S. Since there is no pair here in S, this is trivially true, so S is symmetric.
Transitive : This says that if there are pairs (a, b) and (b, c) in S, then there must be pair (a,c) in S. Again, this condition is trivially true, so S is transitive. Thus, option (D) is correct.
Ans .
A
- Explanation :
Most programming languages including C, C++, Java and Pascal can be approximated by context-free grammar and compilers for them have been developed based on properties of context-free languages
Ans .
A
- Explanation :
Any expression can be converted into Postfix or Prefix form.
Prefix and postfix evaluation can be done using a single stack.
For example : Expression '10 2 8 * + 3 -' is given. PUSH 10 in the stack. PUSH 2 in the stack. PUSH 8 in the stack. When operator '*' occurs, POP 2 and 8 from the stack. PUSH 2 * 8 = 16 in the stack. When operator '+' occurs, POP 16 and 10 from the stack. PUSH 10 * 16 = 26 in the stack. PUSH 3 in the stack. When operator '-' occurs, POP 26 and 3 from the stack. PUSH 26 - 3 = 23 in the stack. So, 23 is the answer obtained using single stack. Thus, option (A) is correct.
Ans .
B
- Explanation :
Static Linking and Static Libraries is the result of the linker making copy of all used library functions to the executable file. Static Linking creates larger binary files, and need more space on disk and main memory. Examples of static libraries (libraries which are statically linked) are, .a files in Linux and .lib files in Windows. Dynamic linking and Dynamic Libraries Dynamic Linking doesn’t require the code to be copied, it is done by just placing name of the library in the binary file. The actual linking happens when the program is run, when both the binary file and the library are in memory. Examples of Dynamic libraries (libraries which are linked at run-time) are, .so in Linux and .dll in Windows. In Dynamic Linking,the path for searching dynamic libraries is not known till runtime
Ans .
B
- Explanation :
(a) More than one program may be loaded into main memory
at the same time for execution.
True: Only done in a multiprogrammed OS, not in single
programmed OS
(b) If a program waits for certain events such as I/O,
another program is immediately scheduled for execution.
True: Only done in a multiprogrammed OS, not in single
programmed OS
(c) If the execution of program terminates, another program
is immediately scheduled for execution.
False: Done in both Multiprogrammed and single
programmed OSs
Ans .
B
- Explanation :
In the index allocation method, an index block stores the address of all the blocks allocated to a file.
When indexes are created, the maximum number of blocks given to a file depends upon the size of the index which tells how many blocks can be there and size of each block(i.e. same as depending upon the number of blocks for storing the indexes and size of each index block). Thus, option (B) is correct.
Ans .
C
- Explanation :
Size of 1 record = 8 + 4 = 12 Let the order be N. No. of index values per block = N - 1 (N - 1) 12 + 4 = 512 12N - 12 + 4 = 512 16N = 1009 N = 43.3333
Ans .
C
- Explanation :
Answer is (C) since to identify BCNF we need BCNF definition. One relation which satisfies will be in BCNF and other will be in 3NF. 1st is wrong because dependency may be preserved by both 3NF and BCNF. 2nd is wrong Because both 3NF and BCNF decomposition can be lossless. 4th is wrong because 3NF and BCNF both are in 3NF also.
Ans .
C
- Explanation :
Generally Normalization is done on the schema itself. From the relational instance given,we may strike out FD s that do not hold. e.g.B does not functionally determine C(This is true). But we cannot say that A functionally determines B for the entire relation itself. This is because that, A->B holds for this instance, but in future there might be some tuples added to the instance that may violate A->B. So overall on the relation we cannot conclude that A->B, from the relational instance which is just a subset of an entire relation