GATE CS 2008
Ans .
A
- Explanation :
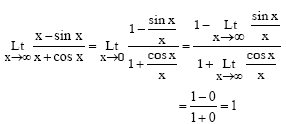
Ans .
D
- Explanation :
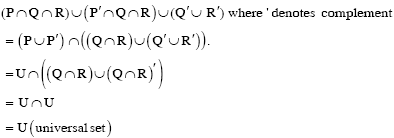
Ans .
E
- Explanation :
The choice E was not there in GATE paper. We have added it as the given 4 choices don't seem correct. Augment the given matrix as
1 1 2 | 1
1 2 3 | 2
1 4 a | 4
Apply R2 <- R2 - R1 and R3 <- R3 - R1
1 1 2 | 1
0 1 1 | 1
0 3 a-2 | 3
Apply R3 <- R3 - 3R2
1 1 2 | 1
0 1 1 | 1
0 0 a-5 | 0
So for the system of equations to have a unique solution,
a - 5 != 0
or
a != 5
or
a = R - {5}
Ans .
D
- Explanation :
Ans .
D
- Explanation :
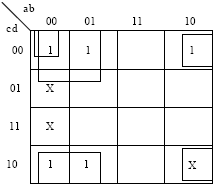
Ans .
D
- Explanation :
As we can see 121 contains digit ' 2 ' which can ' t be represented directly in base ' 2 ' ( as digits should be less than base ) so number system must have " r>2 " . Ans (D) part.
Ans .
A
- Explanation :
Turing machine can be designed for ap using the concept of ' Sieve of Eratosthenes ' .
Suppose we are given an integer ' n ' and we want to find out all the prime numbers less than or equal to ' n '. We repeat the following steps. We find the smallest number in the list declare it prime and eliminate all the multiples of that number from the list. We keep doing this until each element has been declared prime or eliminated from the list.
Now, if p = 0 or p = 1 we reject the input. Else we replace the first and the last ' a ' with symbol $.
In the above steps, what we do is we find the first non-black symbol from the left. Let this symbol occur at position 'x '. Suppose ' x ' is a prime number. If this non-blank symbol is $ input string will be accepted. But if the symbol is ' a ' we mark it as a * and replace all the multiples of ' x ' with the symbol ' blank '. If at the end, symbol $ is replaced with ' blank ' we reject the input string ( because p will be multiple of some ' x ' in that case ). Else we go back and repeat the steps.
Thus the input is neither regular nor context-free but is accepted by a Turing machine.
Please comment below if you find anything wrong in the above post.
Ans .
A
- Explanation :
( A ) Intersection of two regular languages is regular and checking if a regular language is infinite is decidable. ( B ) Deciding regularity of a context free language is undecidable. We check if L ( CFG ) contains any string with length between n and 2n - 1 where n is the pumping lemma constant. If so, L ( CFG ) is infinite otherwise it is finite.
( C ) Equality problem is undecidable for all languages except in case of finite automata i.e. for regular languages. ( D ) We have to check if the grammar obeys the rules of CFG. If, it obeys such rules then it is decidable.
Thus option ( B ) is correct.
Ans .
A
- Explanation :
Let ' s first understand the terminology used here. LR Parsing - Here ' L ' stands for Left to Right screening of input string and ' R ' stands for Right Most Derivation in Reverse ( because it is about bottom up parsing ).
Sentential Form Suppose For a given Context Free Grammar G, we have a start symbol S then to define Language generated by Grammar G i.e. L ( G ) we start the derivation starting from S using the production rules of the grammar. After one complete derivation we get a string w which consists of only terminal symbols i.e. w belongs to L ( G ).
Then we can say that w is a sentence of the Grammar G. Now while the derivation process if it gets some form q where q may contain some Non terminal then we say that q is a sentential form of the Grammar G. Even the start symbol S is also the sentential form of the Grammar G ( because it also contains Non-terminal S (.
For Ex :
Grammar is :
S-> aAcBe
A->Ab|b
B->d
Input string : abbcde
Derivation : ( Top-Down, Right Most Derivation)
S - > aAcBe
- > aAcde
- > aAbcde
- > abbcde
: abbcde - > aAbcde ( using A - > b ) - > aAcde ( using A - > Ab ) - > aAcBe ( using B - > d ) - > S ( using S - > aAcBe )
Ans .
A
- Explanation :
Option ( B )is also true. But the main purpose of doing some code-optimization on intermediate code generation is to enhance the portability of the compiler to target processors. So Option ( A ) is more suitable here. Intermediate code is machine architecture independent code. So a compiler can optimize it without worrying about the architecture on which the code is going to execute ( it may be the same or the other ).
So that kind of compiler can be used by multiple different architectures. In contrast to that, suppose code optimization is done on target code, which is machine architecture dependent, then the compiler has be specific about the optimizations on that kind of code.
In this case the compiler cant be used by multiple different architectures because the target code produced on different architectures would be different. Hence portability reduces here.
Ans .
A
- Explanation :
If L is recursively enumerable then L ' is recursively enumerable if and only if L is also recursive.
Ans .
A
- Explanation :
The default TCP Maximum Segment Size is 536. Where a host wishes to set the maximum segment size to a value other than the default, the maximum segment size is specified as a TCP option, initially in the TCP SYN packet during the TCP handshake. Because the maximum segment size parameter is controlled by a TCP option, a host can change the value in any later segment.
Ans .
A
- Explanation :
A clustering index as the name suggests is created when the data can be grouped in the form of clusters.
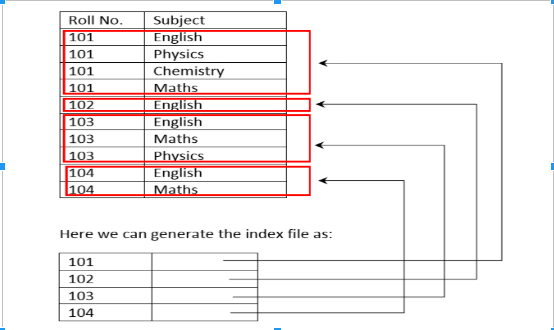
Ans .
A
- Explanation :
socket ( ) creates a new socket of a certain socket type identified by an integer number and allocates system resources to it. bind ( ) is typically used on the server side, and associates a socket with a socket address structure i.e. a specified local port number and IP address
listen( ) is used on the server side, and causes a bound TCP socket to enter listening state. connect( ) is used on the client side, and assigns a free local port number to a socket. In case of a TCP socket it causes an attempt to establish a new TCP connection. When connect ( ) is called by client following three way handshake happens to establish the connection in TCP.
1 ) The client requests a connection by sending a SYN ( synchronize ) message to the server. 2 ) The server acknowledges this request by sending SYN ACK back to the client. 3 ) The client responds with an ACK and the connection is established. Sources Berkeley sockets TCP Connection Establishment and Termination
Ans .
A
- Explanation :
The given expression assigns maximum among three elements ( x y and z ) to a.
Ans .
A
- Explanation :
Number of connected components in undirected graph can simply calculated by doing a BFS or DFS. The best possible time complexity of BFS and DFS is O ( m + n ).
Ans .
A
- Explanation :
The Unix file system uses an extension of indexed allocation. It uses direct blocks, single indirect blocks, double indirect blocks and triple indirect blocks. Following diagram shows implementation of Unix file system. The diagram is taken from Operating System Concept book.
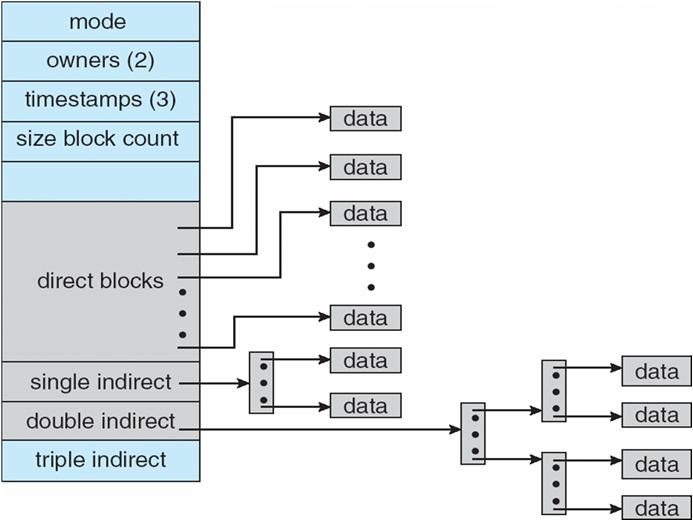
Ans .
A
- Explanation :
A planar graph is a graph which can drawn on a plan without any pair of edges crossing each other. A is FALSE A disconnected graph can be planar as it can be drawn on a plane without crossing edges. B is FALSE An Eulerian Graph may or may not be planar. An undirected graph is eulerian if all vertices have even degree. For example, the following graph is Eulerian, but not planar Complete graph K5.svg C is TRUE: D is FALSE:
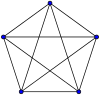
Ans .
A
- Explanation :
Ans .
A
- Explanation :
Ans .
A
- Explanation :
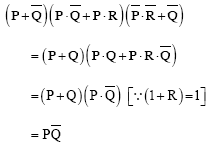
Ans .
A
- Explanation :

Ans .
A
- Explanation :
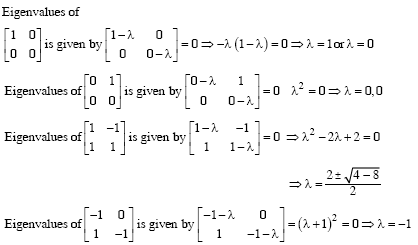
Ans .
A
- Explanation :
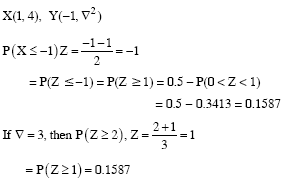
Ans .
A
- Explanation :
Whenever head moves from one track to other then its speed and direction changes which is noting but change in motion or the case of inertia. So answer B
Ans .
A
- Explanation :
In auto-increment addressing mode the address where next data block to be stored is generated automatically depending upon the size of single data item required to store. Self relocating code takes always some address in memory and statement says that this mode is used for self relocating code so option 1 is incorrect and no additional ALU is required
Ans .
A
- Explanation :
I and II are same by Demorgan's law The IIIrd can be simplified to I.
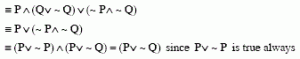
Ans .
A
- Explanation :
RFE Return From Exception is a privileged trap instruction that is executed when exception occurs so an exception is not allowed to execute. In computer architecture for a general purpose processor, an exception can be defined as an abrupt transfer of control to the operating system. Exceptions are broadly classified into 3 main categories: a. Interrupt: it is mainly caused due to I/O device. b. Trap: It is caused by the program making a syscall. c. Fault: It is accidentally caused by the program that is under execution such as( a divide by zero, or null pointer exception etc). The processor’s fetch instruction unit makes a poll for the interrupts. If it finds something unusual happening in the machine operation it inserts an interrupt pseudo- instruction in the pipeline in place of the normal instruction. Then going through the pipeline it starts handling the interrupts. The operating system explicitly makes a transition from kernel mode to user mode, generally at the end of an interrupt handle pr kernel call by using a privileged instruction RFE Return From Exception instruction.
Ans .
A
- Explanation :
Answer is B i.e. i and iv are true. Because inclusion says the L2 cache should be Superset of L1 cache. If Write Through update" is not used and Write Back update is used at L1 cache then the modified data in L1 cache will not be present in L2 cache for some time unless the block in L1 cache is replaced by some other block. Hence Write Through Update should be used. Associativity dose not matter. L2 cache must be at least as large as L1 cache since all the words in L1 are also is L2.
Ans .
A
- Explanation :
I - False Bypassing cannot handle all RAW hazard consider when any instruction depends on the result of LOAD instruction, now LOAD updates register value at Memory Access Stage MA so data will not be available directly on Execute stage. II True register renaming can eliminate all WAR Hazard. III False It cannot completely eliminate though it can reduce Control Hazard Penalties
Ans .
A
- Explanation :
I is true as by using multiple register windows we eliminate the need to access the variable values again and again from the memory. Rather we store them in the registers. II is false as register saves and restores would still be required for each and every variable. III is also false as instruction fetch is not affected by memory access using multiple register windows. So only I is true. Hence A is the correct option. Please comment below if you find anything wrong in the above post.
Ans .
A
- Explanation :
When we calculate effective address first of all we access TLB to access the Frame number. Logical address generated by CPU breaks in two parts page number and page offset for faster accessing of data we place some page table entries in a small hardware TLB whose access time is same as cache memory. So initially when page no. is mapped to find the corresponding frame no. first it is look up in TLB and then in page table in case if TLB miss. During effective address calculation TLB is accessed. So B is correct option.
Ans .
A
- Explanation :

Ans .
A
- Explanation :

Ans .
A
- Explanation :

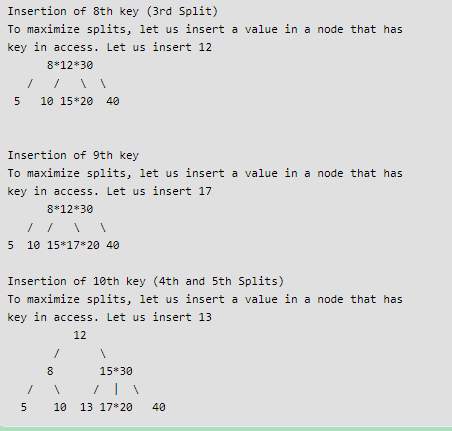
Ans .
A
- Explanation :

Ans .
A
- Explanation :

Ans .
A
- Explanation :
One important thing to note is it is Binary Search Tree not Binary Tree. In BST inorder traversal can always be obtained by sorting all keys.
Ans .
A
- Explanation :
A language is recursively enumerable if there exists a Turing machine that accepts every string of the language and does not accept strings that are not in the language. Strings that are not in the language may be rejected or may cause the Turing machine to go into an infinite loop. A recursive language can't go into an infinite loop it has to clearly reject the string, but a recursively enumerable language can go into an infinite loop. So every recursive language is also recursively enumerable. Thus the statement Every subset of a recursively enumerable set is recursive is false. Thus option D is the answer.
Ans .
A
- Explanation :
I is true as we can always remove left recursion from any given grammar. For better understanding, see this. II is false as we can remove all epsilon productions only if grammar doesnt contain epsilon in the language. III is true as it is the definition of regular grammar. For better understanding see type 3 languages in this article. IV is true because in chomsky normal form all the productions are of type X gives YZ or X gives t where X Y Z are variables and t is terminal string. When we draw the derivation tree for every node there are at most 2 children. Thats why Derivation trees of grammars in chomsky normal form are Binary trees.For better understanding, see this. Thus C is the correct choice.
Ans .
A
- Explanation :
If L is recursively enumerable then L ' is recursively enumerable if and only if L is also recursive.
Ans .
A
- Explanation :
Turing machine can be designed for ap using the concept of ' Sieve of Eratosthenes ' .
Suppose we are given an integer ' n ' and we want to find out all the prime numbers less than or equal to ' n '. We repeat the following steps. We find the smallest number in the list declare it prime and eliminate all the multiples of that number from the list. We keep doing this until each element has been declared prime or eliminated from the list.
Now, if p = 0 or p = 1 we reject the input. Else we replace the first and the last ' a ' with symbol $.
In the above steps, what we do is we find the first non-black symbol from the left. Let this symbol occur at position 'x '. Suppose ' x ' is a prime number. If this non-blank symbol is $ input string will be accepted. But if the symbol is ' a ' we mark it as a * and replace all the multiples of ' x ' with the symbol ' blank '. If at the end, symbol $ is replaced with ' blank ' we reject the input string ( because p will be multiple of some ' x ' in that case ). Else we go back and repeat the steps.
Thus the input is neither regular nor context-free but is accepted by a Turing machine.
Please comment below if you find anything wrong in the above post.
Ans .
D
- Explanation :
Ans .
A
- Explanation :
Number of connected components in undirected graph can simply calculated by doing a BFS or DFS. The best possible time complexity of BFS and DFS is O ( m + n ).
Ans .
E
- Explanation :
The choice E was not there in GATE paper. We have added it as the given 4 choices don't seem correct. Augment the given matrix as
1 1 2 | 1
1 2 3 | 2
1 4 a | 4
Apply R2 <- R2 - R1 and R3 <- R3 - R1
1 1 2 | 1
0 1 1 | 1
0 3 a-2 | 3
Apply R3 <- R3 - 3R2
1 1 2 | 1
0 1 1 | 1
0 0 a-5 | 0
So for the system of equations to have a unique solution,
a - 5 != 0
or
a != 5
or
a = R - {5}
Ans .
A
- Explanation :