GATE-CS-2016 (Set 2)
Ans .
B
- Explanation :
University considered as an organization that's why article the used before university. And Post of security is a general post, so article a has been used for security guard. So, option (B) is true.
Ans .
A
- Explanation :
put up with - is a phrasal verb Meaning : to accept somebody/something that is annoying, unpleasant without complaining.
Ans .
C
- Explanation :
mock : tease deride : poke/laugh at praise : gratitude jerk : fool So except praise, all others are describing negative things.
Ans .
D
- Explanation :
In the given options apart from Option D, characters at odd positions are consecutive alphabets in increasing order and similarly characters at even positions also are consecutive alphabets in increasing order. Option A: CADBE C,D,E(characters at 1st,3rd and 5th positions are consecutive alphabets in increasing order) similarly A,B(characters at 2nd and 4th positions are consecutive alphabets in increasing order). Option D: ONPMQ O,P,Q(characters at 1st,3rd and 5th positions are consecutive alphabets in increasing order) but N,M(characters at 2nd and 4th positions are not increasing order)
Ans .
B
- Explanation :
(a^n + ß^n)/ (1/a^n +1/ß^n) (a^n + ß^n)/ (ß^n + a^n )*(a^n * ß^n) (a^n * ß^n) aß^n 4^n .
Ans .
A
- Explanation :
Suppose n(F) : number of faculty connected through facebook n(W) : number of faculty connected through whatsapp n(F ? W) : number of faculty connected through either facebook and whatsapp n(F n W) : number of faculty connected through both facebook and whatsapp n(F ? W) = (total faculty - faculty not connected to anything) = (150-30) = 120 From number theory: n(F ? W) = n(F) + n(W) - n(F n W) n(F) - n(F n W) = n(F ? W) - n(W) n(F) - N(F n W) = (120-85) = 35 n(F)- n(F n W) is the faculty that has only facebook account, Hence answer is 35.
Ans .
D
- Explanation :
Author has not said anything against internet and mobile computing but is talking about the surprising usage of these. "Many believe that the internet itself is an unintended consequence of the original invention." The author says that many believe that 'internet itself' is unplanned but actually both internet and mobile computers are unplanned(unintended) inventions.
Ans .
D
- Explanation :
Given statement doesn't say that - "All hill-stations have a lake" but any place having a lake is surely a hill station. ---> Ooty may or may not be a hill station Hence (i) is false ---> Here, it is not a compulsion that a place need to have exactly one lake to be a hill station. Hence (ii) is also false
Ans .
C
- Explanation :
To form a rectangle, we must choose two horizontal sides and two vertical sides. So, number of rectangles we can form is mC2 * nC2. Since there are three horizontal lines, we can choose the horizontal sides in 3C2 ways. Since there are five vertical lines, we can choose the vertical sides in 5C2 ways. The number of rectangles we can form is = 5C2 * 3C2 = {(5*4)/2}*{(3*2)/2} = 10*3 = 30 So, option (C) is correct.
Ans .
C
- Explanation :
Simply, there are two test cases: ---> In graph, at x = 1, f(x) = 2 Let's find the values at x = 1 in given options: A) f(1) = 1 - |1-1| = 1 - 0 = 1 B) f(1) = 1 + |1-1| = 1 + 0 = 1 C) f(1) = 2 - |1-1| = 2 - 0 = 2 D) f(1) = 2 + |1-1| = 2 + 0 = 2 Hence (A) and (B) are incorrect. Now, ---> In the graph, at x=0, f(x) = 1 Let's find the values at x = 1 in the remaining options, i.e. C and D. (c) f(0) = 2 - |0-1| = 2 - 1 = 1 (d) f(0) = 2 + |0-1| = 2 + 1 = 3 Hence, C is the correct answer.
Ans .
C
- Explanation :

Ans .C
C
- Explanation :
f(x) can be either an even function or an odd function. If f(x) was an odd function, then f(x) + f(-x) = 0, but here it has been given that it has degree 10. So, it must be an even function. Therefore, f(x) = f(-x) => f'(x) = -f'(-x) Also, it has been mentioned that g(x) is the derivative of f(x). So, g(x) = f'(x) and g(-x) = -f'(-x) => g(x) - g(-x) = f'(x) - (-f'(-x)) => g(x) - g(-x) = f'(x) + f'(x) => g(x) - g(-x) = 2 * f'(x) But, f'(x) will have degree 9. Thus, C is the correct option.
Ans D
D
- Explanation :
A planar graph is a graph on a plane where no two edges are crossing each other. The set of regions of a map can be represented more abstractly as an undirected graph that has a vertex for each region and an edge for every pair of regions that share a boundary segment. Hence the four color theorem is applied here. Here is a property of a planar graph that a planar graph does not require more than 4 colors to color its vertices such that no two vertices have same color. This is known four color theorem.
Ans C
C
- Explanation :
For 'n' variables, we need atleast 'n' linear equations in terms of the given variable to find value of each variable. If no. of equations > no. of variables then also we can find the value of each variable. Here, m : No. of linear equations n : No. of variables For solution, m > or = n.
Ans A
A
- Explanation :
The question is based on Bayes' Theorem. P(LED is Type 1) = 1/2 P(LED is type 2) = 1/2 Now, we need to see conditional probabilities. P( LED lasting more than 100 hours / LED is Type 1) = 0.7 P( LED lasting more than 100 hours / LED is Type 2) = 0.4 P(LED lasts more than 100 hours) = P( LED is Type1)* P(LED lasting more than 100 hours / LED is Type 1) + P(LED is Type 2) * P( lasting more than 100 hours / Type 2) = 0.5 * 0.7 + 0.5 * 0.4 = 0.35 + 0.20 = 0.55 Thus, A is the correct choice.
Ans A
A
- Explanation :
1/8 Determinant of A = 1*4*2 = 8 which is product of Eigen values. Determinant of A-1 = 1/8 as determinant of inverse of matrix is inverse of determinant. Determinant of Transpose (A-1) = 1/8 since determinant of transpose of matrix remains same as original one.
Ans A
A
- Explanation :
Here "longest latency for the sum to stabilize" means maximum delay that ripple carry adder would take to add A and B, we are given value of A and need to find the value of B. The Delay in Ripple Carry Adder is as follows - For sum there are 2 XOR gates. - For carry there is 1 XOR,1 AND and 1 OR gate. i.e total 3 gate delays in case of carry and 2 gate delays in sum. If we do 2's complement of 1 in 8 bit we get "00000001". same we do for each option -1 : "11111111" 2 : "00000010" 1 : "00000001" -2 : "11111110" So in case of -1 the carry bit will change and thus it will take 1 extra gate delay, hence we could see that the maximum delay we could get when input at B will be -1, i.e. add "00000001" with "11111111" and would get Maximum delay.
Ans C
C
- Explanation :
First we rearrange the terms, x1?x2?x3?x4 = 0 x1?x3?x2?x4 = 0 x1?x3 = x2?x4 Then use a?b=a'?b'a?b=a'?b' to get (C). x'1?x'3=x'2?x'4 Another approach : You can take a counter example to disprove other options. You can take x1 = x2 = x3 = x4 = 1. Only option (C) is correct.
Ans A
A
- Explanation :
Answer: For n bits, Distinct values represented in 2's complement is -2^n-1 to 2^n-1 -1 Distinct values represented in Signed Magnitude is -(2^(n-1) -1) to 2^(n-1) -1 For example if n = 8, we can represent numbers from -128 to 127 in 2's complement representation and numbers from -127 to 127 in signed magnitude representation. Difference is 1. The difference of 1 is there because there are two different representations of +0 and -0 in signed magnitude representation. But in 2's complement representation, there is one representation of 0.
Ans A
A
- Explanation :
Answer: 6 bits are needed for 40 distinct instructions ( because, 32 < 40 < 64 ) 5 bits are needed for 24 general purpose registers( because, 16< 24 < 32) 32-bit instruction word has an opcode(6 bit), two register operands(total 10 bits) and an immediate operand (x bits). The number of bits available for the immediate operand field => x = 32 - ( 6 + 10 ) = 16 bits
Ans A
A
- Explanation :
Answer: 6 It would be node number 31 for given distance 4. For example if we consider at distance 2, below highlighted node G can be the farthest node at position 7. A / \ B C / \ / \ D E F G Alternative Solution : t is the n-th vertex in this BFS traversal at distance four from the root. So height of tree is 4. Max number of nodes = 2^{h+1} - 1 = 2^{5} - 1 = 31 At distance four, last node is 31. option (C)
Ans A
C
- Explanation :
Answer: 6 It would be node number 31 for given distance 4. For example if we consider at distance 2, below highlighted node G can be the farthest node at position 7. A / \ B C / \ / \ D E F G Alternative Solution : t is the n-th vertex in this BFS traversal at distance four from the root. So height of tree is 4. Max number of nodes = 2^{h+1} - 1 = 2^{5} - 1 = 31 At distance four, last node is 31. option (C)
Ans C
C
- #include"stdio.h" void f(int* p, int m) { m = m + 5; *p = *p + m; return; } int main() { int i=5, j=10; f(&i, j); printf("%d", i+j); } For i, address is passed. For j, value is passed. So in function f, p will contain address of i and m will contain value 10. Ist statement of f() will change m to 15. Then 15 will be added to value at address p. It will make i = 5+15 = 20. j will remain 10. print statement will print 20+10 = 30. So answer is C.
Ans C
C
- Given an array in ascending order, Recurrence relation for total number of comparisons for quicksort will be T(n) = T(n-1)+O(n) //partition algo will take O(n) comparisons in any case. = O(n^2) II. Bubble Sort runs in T(n^2) time If an array is in ascending order, we could make a small modification in Bubble Sort Inner for loop which is responsible for bubbling the kth largest element to the end in kth iteration. Whenever there is no swap after the completion of inner for loop of bubble sort in any iteration, we can declare that array is sorted in case of Bubble Sort taking O(n) time in Best Case. III. Merge Sort runs in T(n) time Merge Sort relies on Divide and Conquer paradigm to sort an array and there is no such worst or best case input for merge sort. For any sequence, Time complexity will be given by following recurrence relation, T(n) = 2T(n/2) + T(n) // In-Place Merge algorithm will take T(n) due to copying an entire array. = T(nlogn) IV. Insertion sort runs in T(n) time Whenever a new element which will be greater than all the elements of the intermediate sorted sub-array ( because given array is sorted) is added, there won't be any swap but a single comparison. In n-1 passes we will be having 0 swaps and n-1 comparisons. Total time complexity = O(n)
Ans C
C
- Floyd Warshall Algorithm is a Dynamic Programming based algorithm. It finds all pairs shortest paths using following recursive nature of problem. For every pair (i, j) of source and destination vertices respectively, there are two possible cases. 1) k is not an intermediate vertex in shortest path from i to j. We keep the value of dist[i][j] as it is. 2) k is an intermediate vertex in shortest path from i to j. We update the value of dist[i][j] as dist[i][k] + dist[k][j]. The following figure is taken from the Cormen book. It shows the above optimal substructure property in the all-pairs shortest path problem.Since there are overlapping subproblems in recursion, it uses dynamic programming.
Ans C
C
- The time complexity of decrease-key operation is T(1) since we have the pointer to the record where we have to perform the operation. However, we must keep the doubly linked list sorted and after the decrease-key operation we need to find the new location of the key. This step will take T(N) time and since there are T(N) decrease-key operations, the time complexity becomes O(N²). Note that the other three operations have a lower bound than this one.
Ans A
A
- The minimum no of state is 2.
Ans C
C
- L1 has the property that no of a's should be equal to no of b's in a string, and all a's should precede all b's . Hence extra memory will be required to check this property of a string ( Finite Automaton can't be built for this type of language). Hence this is not regular language. Therefore P is False. L2 has the property that no of a's should be equal to no of b's, but order of a's and b's is different here, it is (ab)*, which will require no extra memory to be accepted.( Finite Automaton can be built for this language). Hence L2 is regular language. Therefore Q is True.
Ans D
D
- St 1: As L3 is Recursive and recursive languages are closed under complementation, L3’ will also be recursive. L3’ U L4 is also recursive as recursive languages are closed under union. St 2: As L2 is Context- Free, it will be recursive as well. L2 U L3 is recursive because as recursive languages are closed under union. St 3: L1* is regular because regular languages are closed under kleene –closure. L1* U L2 is context free as union of regular and context free is context free. St 4: L2’ may or may not be context free because CFL are not closed under complementation. So it is not true. So I, II and III are correct.
Ans B
B
- Lexical analysis uses Regular expression to recognize identifiers. Top down parsing uses Left Most Derivation to generate the string the of the language. Type checking is done at Semantic analysis phase of the compiler. Activation records of a function are loaded into stack memory at Run time.
Ans D
D
- In some situations FIFO page replacement gives more page faults when increasing the number of page frames. This situation is Belady’s anomaly. Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm. For example, if we consider reference string 3 2 1 0 3 2 4 3 2 1 0 4 and 3 slots, we get 9 total page faults, but if we increase slots to 4, we get 10 page faults.
Ans A
A
- In both B Tree and B+ trees, depth (length of root to leaf paths) of all leaf nodes is same. This is made sure by the insertion and deletion operations. In these trees, we do insertions in a way that if we have increase height of tree after insertion, we increase height from root. This is different from BST where height increases from leaf nodes. Similarly, if we have to decrease height after deletion, we move the root one level down. This is also different from BST which shrinks from bottom. The above ways of insertion and deletion make sure that depth of every leaf node is same.
Ans A
A
- Sender uses its private key to digitally sign a document. Receiver uses public key of sender to verify. So option A is correct.
Ans A
A
- An Ethernet is the most popularly and widely used LAN network for data transmission. It is a protocol of data link layer and it tells how the data can be formatted to transmit and how to place the data on network for transmission. Now considering the Ethernet protocol we will discuss all the options one by one (A) This option is false as in Ethernet the station is not required to stop to sense for the channel prior frame transmission. (B) A signal is jammed to inform all the other devices or stations about collision that has occurred so that further data transmission is stopped. Thus this option is also false (C) Once the collision has occurred the data transmission is stopped as the jam signal is sent. Thus this option is also incorrect. (D) To reduce the probability of collision on retransmissions an exponential back off mechanism is used.
Ans C
C
- Whenever the client request for a webpage, the query is made in the form say www.geeksforgeeks.org. As soon as the query is made the server makes the DNS query to identify the Domain Name Space. DNS query is the process to identify the IP address of the DNS such as www.org. The client’s computer will make a DNS query to one of its internet service provider’s DNS server. Step 2 : As soon as DNS server is located a TCP connection is to be established for the further communication. The TCP protocol requests the server to establishing a connection by sending a TCP SYN message. Which is further responded by the server using SYN_ ACK from server to client and then ACK back to server from client (3- way hand shaking protocol). Step 3 : Once the connection has been established the HTTP protocol comes into picture. It requests for the webpage using its GET method and thus, sending an HTTP GET request. Hence, the correct sequence for the transmission of packets is DNS query, TCP SYN, HTTP GET request.
Ans B
B
- THEORY: REFLEXTIVE RELATION: A relation ‘R’ on a set ‘A’ is said to be reflexive if, (xRx) for every x£A. Ex. If A= {1,2} And R, and P be a relation on AxA, defined as, R= {(2,2),(1,1)} => R is reflexive as it contains all pair of type (xRx). P= {(1,1)} => P is not reflexive relation on A, as it doesn’t contain (2,2). TRANSITIVE RELATION: A relation ‘R’ on set ‘A’ is said to be transitive if (xRy) and (yRz), then (xRz) for every x,y,z £A. Ex: if A= {1,2} Let R be a relation on AxA, defined as, R= {(1,1),(1,2),(2,1)} => R is transitive. SOLUTION: Given, (a, b) R (c, d) if a <= c or b <= d i.Check for reflexivity: if an element of set be (a,b) then, (a,b)R(a,b) should hold true. Here, a<=a or b<=b. So, (a,b)R(a,b) holds true. Hence, ‘R’ is reflexive. ii. Check for transitivity: if elements of set be (2,3),(3,1) and(1,1) Then, (2,3)R(3,1) as 2<=3 And (3,1)R(1,1) as 1<=1 But (2,3)R(1,1) doesn’t hold true as 2>=1 and 3>=1. Hence, R is reflexive but not transitive.
Ans D
D
- Suppose if there are two statements P and Q, P=>Q = ~PvQ i.e. The only situation where implication fails is (=>) when P is true and Q is false. i.e. A truth statement can't imply a false statement. So, for these type of questions it will be better to take option and check for some arbitrary condition By looking options, we are pretty sure that A,B are correct Suppose X is any number and statement is P(x) = X is a prime number Q(x) = X is a non-prime number If we look at option D, Before Implication :- For all x, x is either prime or non-prime which is true After Implication :- For all x, x is prime or for all x, x is non-prime which is obviously false i.e. here, truth statement implies a false statement which is not valid. If we carefully look at option C, There exists a number x, which is both prime and non-prime which is false and a false statement can imply either true or false. So option (C) is correct So Answer is Option (D)
Ans D
D
- Suppose if there are two statements P and Q, P=>Q = ~PvQ i.e. The only situation where implication fails is (=>) when P is true and Q is false. i.e. A truth statement can't imply a false statement. So, for these type of questions it will be better to take option and check for some arbitrary condition By looking options, we are pretty sure that A,B are correct Suppose X is any number and statement is P(x) = X is a prime number Q(x) = X is a non-prime number If we look at option D, Before Implication :- For all x, x is either prime or non-prime which is true After Implication :- For all x, x is prime or for all x, x is non-prime which is obviously false i.e. here, truth statement implies a false statement which is not valid. If we carefully look at option C, There exists a number x, which is both prime and non-prime which is false and a false statement can imply either true or false. So option (C) is correct So Answer is Option (D)
Ans B
B
- Answer is B. This a graph theory question. "\" is the set difference operation. Same as U - S. Since U is universal set, U\S would give complement of S = S' Let S contains Compounds numbered {1,2,3...8, 9} so U\S contains Compounds {10, 11, 12.... 22, 23} Consider these compounds to be vertices of a graph. An edge b/w two vertices indicate that the compounds react with each other. This graph has NO multiple edge cause that doesn't make sense. There are no directed edges cause if one compound reacts with other it also means other reacts with it too. Single edge represent reaction b/w both. It has NO Loops cause compound don't react with itself. Hence graph is simple undirected graph. We know that "An undirected graph has even number of vertices of odd degree" 9 vertices of this graph have degree 3 (odd degree) cause 9 compounds react with 3 other compounds. Hence there must be at LEAST 1 more vertex which must have an odd degree. This extra compound must belong to U\S cause 9 compounds in S have already been accounted for. This implies statement II in the question is TRUE. Other 2 statements are False. Statement III - Consider that all 9 compounds in S react with the same 3 compounds in U\S say with {20, 21, 22} hence all compounds in U\S either react with Zero or 9 compounds but not Even number. Similarly Statement I can be proved wrong by visualizing the graph.
Ans A
A
- Answer is A. Answer: We have 13 * 13 * 13 * ... * 13 (total 99 terms) By remainder theorem, => (-4) * (-4) * ... * (-4) (total 99 terms) => 16 * 16 * ... * 16 * (-4) (total 50 terms, 49 terms for 16 and one term for -4) Reapplying remainder theorem, => (-1) * (-1) * ... * (-1) * (-4) (total 50 terms, 49 terms for -1 and one term for -4) => (-1) * (-4) => 4 Thus, A is the correct option.
Ans A
A
- Background:Explanation: Pipelining is an implementation technique where multiple instructions are overlapped in execution. The stages are connected one to the next to form a pipe - instructions enter at one end, progress through the stages, and exit at the other end. Pipelining does not decrease the time for individual instruction execution. Instead, it increases instruction throughput. The throughput of the instruction pipeline is determined by how often an instruction exits the pipeline. The same concept is used in pipelining. Bottleneck here is UF as it takes 5 ns while UG takes 3ns only. We have to do 10 such calculations and we have 2 instances of UF and UG respectively. Since there are two functional units, each unit get 5 numbers of units to compute on. Suppose computation starts at time 0. which means G starts at 0 and F starts at 3rd second since G finishes computing first element at third second. So, UF can be done in 5*10/2=25 nano seconds. For the start UF needs to wait for UG output for 3 ns and rest all are pipelined and hence no more wait. So, answer is 3+25=28
Ans D
D
- Answer: One instruction is divided into five parts, 1) The opcode- As we have instruction set of size 12, an instruction opcode can be identified by 4 bits, as 2^4=16 and we cannot go any less. 2) & (3) Two source register identifiers- As there are total 64 registers, they can be identified by 6 bits. As they are two i.e. 6 bit + 6 bit. 4) One destination register identifier- Again it will be 6 bits. 5) A twelve bit immediate value- 12 bit. Adding them all we get, 4 + 6 + 6 + 6 + 12 = 34 bit = 34/8 byte = 4.25 byte. As there are 100 instructions, We have a size of 425 byte, which can be stored in 500 byte memory from the given options. Hence (D) 500 is the answer.
Ans A
A
- Answer: We know cache size = no.of.sets* lines-per-set* block-size Let us assume no of sets = 2^x And block size= 2^y So applying it in formula. 2^19 = 2^x + 8 + 2^y; So x+y = 16 Now we know that to address block size and set number we need 16 bits so remaining bits must be for tag i.e., 40 - 16 = 24 The answer is 24 bits
Ans A
A
- Answer: We know cache size = no.of.sets* lines-per-set* block-size Let us assume no of sets = 2^x And block size= 2^y So applying it in formula. 2^19 = 2^x + 8 + 2^y; So x+y = 16 Now we know that to address block size and set number we need 16 bits so remaining bits must be for tag i.e., 40 - 16 = 24 The answer is 24 bits
Ans B
B
- Answer: Consider this pipeline (V1) --> (V2) --> (V3) Can be written as (V) --> (4V/3) --> (V/2) Where given V = V1 = 3V2/4 = 2V3 Largest stage is stage 2 with 4V/3 seconds time required. Speed of processor is limited by this stage only. In fact this is the speed of the processor. Frequency given is 3Ghz, which means processor can execute 3 Giga clock cycle.... in 1 second Or 1 clock cycle .....in (1/3G) secs (G for giga) But we know that stage latency of the largest stage in pipeline limits the time of 1 clock cycle. Hence 4V/3 = 1 clock cycle = 1/3G secs V = 1/4G...........(1) Now largest stage that is stage 2 is split into equal size, so new pipeline is (V)-->(2V/3)-->(2V/3)-->(V/2) Now largest stage is V seconds Hence, In V seconds do 1 clock cycle In 1 second do 1/V clock cycles But V = 1/4G So in 1 second do 4 Ghz. {ANS}
Ans C
C
- Answer: here node with integer 1 has to be at root only. Now for maximum depth of the tree the following arrangement can be taken. Take root as level 1. make node 2 at level 2 as a child node of node 1. make node 3 at level 3 as the child node of node 2. .. .. and so on for nodes 4,5,6,7 .. make node 8 at level 8 as the child node of node 7. make node 9 at level 9 as the child node of node 8. Putting other nodes properly, this arrangement of the the complete binary tree will follow the property of min heap. So total levels are 9. node 9 is at level 9 and depth of node 9 is 8 from the root.
Ans C
C
- We can solve this question taking any two values for X and Y. Suppose X= 2 and Y= 5, now this code will calculate Looking at each iteration separately Before iteration 1 – X=2 Y= 5 a=2 , b=5, res=1 Iteration 1 – since b%2 !=0 we go to else part Therefore after iteration 1, X=2, Y=5, a=2, b=4, res=2 Iteration 2 – since b%2=0 we go to if part Therefore after iteration 2 , X=2, Y=5, a=4, b=2, res=2 Iteration 3 – since b%2=0 we go to if part Therefore after iteration 3 , X=2, Y=5, a=16, b=1, res=2 Iteration 4 – since b%2!=0 we go to else part Therefore after iteration 4 , X=2, Y=5, a=16, b=0, res=32 Now putting the values of X, Y , a, b, res in the equations given in options after each iteration we can see only equation c is correct. This solution is contributed by Parul sharma. Another solution In option C Before Iteration 1: X^Y=64 res * (a^b)=64 Before Iteration 2: X^Y=64 res * (a^b)=64 Before Iteration 3: X^Y=64 res * (a^b)=64
Ans C
C
- Reverse Polish expression is derived through Post-Order i.e. 1) Visit Left Node 2) Visit Right Node (L R N) 3) Visit Root Node --- Acc. to Ques. New Order algorithm is : 1) Visit Root Node 2) Visit Right Node (N R L) 3) Visit Left Node ie. New Order Expression will be a total reverse of the Post-Order algorithm Post-Order Expression : 3 4 * 5 – 2 ˆ 6 7 * 1 + – Hence , New Order Expression : – + 1 * 7 6 ^ 2 – 5 * 4 3
Ans B
B

Ans A
A
- We have many ways to do matrix chain multiplication because matrix multiplication is associative. In other words, no matter how we parenthesize the product, the result of the matrix chain multiplication obtained will remain the same. Here we have four matrices A1, A2, A3, and A4, we would have: ((A1A2)A3)A4 = ((A1(A2A3))A4) = (A1A2)(A3A4) = A1((A2A3)A4) = A1(A2(A3A4)). However, the order in which we parenthesize the product affects the number of simple arithmetic operations needed to compute the product, or the efficiency. Here, A1 is a 10 × 5 matrix, A2 is a 5 x 20 matrix, and A3 is a 20 x 10 matrix, and A4 is 10 x 5. If we multiply two matrices A and B of order l x m and m x n respectively,then the number of scalar multiplications in the multiplication of A and B will be lxmxn. Then, The number of scalar multiplications required in the following sequence of matrices will be : A1((A2A3)A4) = (5 x 20 x 10) + (5 x 10 x 5) + (10 x 5 x 5) = 1000 + 250 + 250 = 1500. All other parenthesized options will require number of multiplications more than 1500.
Ans A
A
- The time complexity of a recurrence relation is the worst case time complexity. First we have to find out the number of function calls in worst case from the flow chart. The worst case will be when all the conditions (diamond boxes) turn out towards non-returning paths taking the longest root. In the longest path we have 5 function calls.
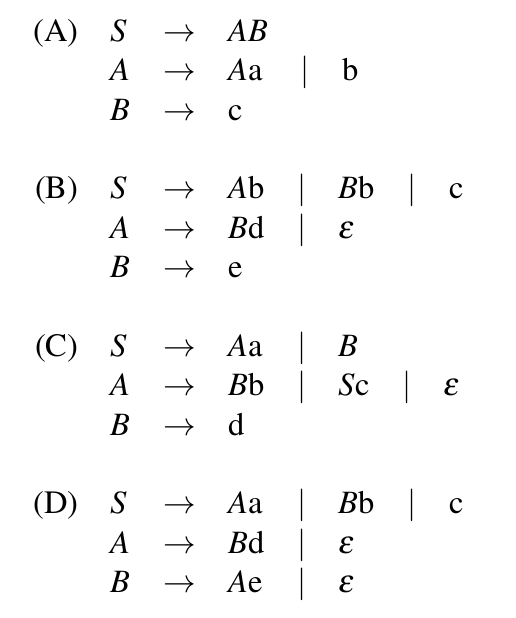 So the recurrence relation will be – A(n) = 5A(n/2) + O(1) (O(1) because rest of the statements have O(1) complexity.) Solving this recurrence relation using Master theorem – a = 5 , b= 2 , f(n) =O(1) , nlogb a= nlog2 5 (case 1 master theorem) A(n) =nlogb a value of log 25 is 2.3219, so, the best option is option a
So the recurrence relation will be – A(n) = 5A(n/2) + O(1) (O(1) because rest of the statements have O(1) complexity.) Solving this recurrence relation using Master theorem – a = 5 , b= 2 , f(n) =O(1) , nlogb a= nlog2 5 (case 1 master theorem) A(n) =nlogb a value of log 25 is 2.3219, so, the best option is option a
Ans C
C
- Answer: To get height 6, we need to put either 1 or 7 at root. So count can be written as T(n) = 2*T(n-1) with T(1) = 1 7 / [1..6] 1 \ [2..7] Therefore count is 26 = 64 Another Explanation: Consider these cases, 1 2 3 4 5 6 7 1 2 3 4 5 7 6 1 7 6 5 4 3 2 1 7 6 5 4 2 3 7 6 5 4 3 2 1 7 6 5 4 3 1 2 7 1 2 3 4 5 6 7 1 2 3 4 6 5 For height 6, we have 2 choices. Either we select the root as 1 or 7. Suppose we select 7. Now, we have 6 nodes and remaining height = 5. So, now we have 2 ways to select root for this sub-tree also. Now, we keep on repeating the same procedure till remaining height = 1 For this last case also, we have 2 ways. Therefore, total number of ways = 26= 64
Ans B
B
- First you need to find twins of each node. You can do this using level order traversal (i.e., BFS) once. Time complexity of BFS is T(m +n). And you have to use linked list for representation which is extra space (but memory size is not a constraint here). Final, time complexity is T(m + n) to set twin pointer. Option (B) is correct.
Ans B
B
- Answer: False, Since there is no mention of transition between states. There may be a case, where between two states there is no transition defined. Statement II: True, Since any empty language (i.e., A = F ) is regular and its intersection with any other language is F. Thus A n B is regular.
Ans B
B
- L1 = {anbmcn |m, n = 1} is context free language because it is derived by the following CFG: S- > aSc|aBc; B- > bB|b • L2 = {anbnc2n |n = 1} is not a context free language, this can be proved using pumping lemma. Intuitively, a pushdown automaton can’t remember number of as for the third set of characters coming, i.e. c. This language is very similar to {anbmcn |n = 1} which is known to be a non-CFL. Hence, correct answer would be (B) L1 is context-free while L2 is not context-free. L2 is not context free. no. of b's will match with no. of a's leaving c's to be matched with no one..so L2 cant be context free.
Ans C
C
- L1 and L2 both are recursive. L1 = {
| M takes at least 2016 steps on some input} In L1 we can stop giving input once we find any string which is accepted in less than 2016 steps. In L2 we have to check all possible inputs whose length is less than 2016 and all possible string whose length is less than 2016 is a finite set. For both L1 and L2 machine is definetly going to halt. Both L1 and L2 are recursive. L3 is undecideble, M accepts e. So L3 is not recursive. Option (C) is CORRECT.
Ans B
B
- Answer: Grammar A has direct left recursion because of the production rule: A->Aa. Grammar C has indirect left recursion because of the production rules:S-> Aa and A->Sc Grammar D has indirect left recursion because of production rules : A-> Bd and B-> Ae Grammar B doesn't have any left recursion (neither direct nor indirect).
Ans A
A
- Answer: Context-Free Grammars A context-free grammar (CFG) is a set of recursive rewriting rules (or productions) used to generate patterns of strings. A CFG consists of the following components: 1) A set of terminal symbols, which are the characters of the alphabet that appear in the strings generated by the grammar. 2) A set of nonterminal symbols, which are placeholders for patterns of terminal symbols that can be generated by the nonterminal symbols. 3) A set of productions, which are rules for replacing (or rewriting) nonterminal symbols (on the left side of the production) in a string with other nonterminal or terminal symbols (on the right side of the production). 4) A start symbol, which is a special nonterminal symbol that appears in the initial string generated by the grammar. To generate a string of terminal symbols from a CFG, we: 1) Begin with a string consisting of the start symbol; 2) Apply one of the productions with the start symbol on the left hand size, replacing the start symbol with the right hand side of the production; 3) Repeat the process of selecting nonterminal symbols in the string, and replacing them with the right hand side of some corresponding production, until all nonterminals have been replaced by terminal symbols. Given a grammar G with start symbol S, if there is some sequence of productions that, when applied to the initial string S, result in the string s, then s is in L(G), the language of the grammar. Source : https://www.cs.rochester.edu/~nelson/courses/csc_173/grammars/cfg.html We need to check which of the two grammars correctly generate "int a[10][3];". This means we need to check if int id[num][num];
Grammar G1
D ? int L;
L ? id [E
E ? num]
E ? num] [E
Grammar G2
D ? int L;
L ? id E
E ? E[num]
E ? [num]

Ans A
A
- Answer:

PreEmptive Shortest Remaining time first scheduling, i.e. that processes will be scheduled on the CPU which will be having least remaining burst time( required time at the CPU). The processes are scheduled and executed as given in the below Gantt chart. Turn Around Time(TAT) = Completion Time(CT) - Arrival Time(AT) TAT for P1 = 20 - 0 = 20 TAT for P2 = 10 - 3 = 7 TAT for P3 = 8- 7 = 1 TAT for P4 = 13 - 8 = 5 Hence, Average TAT = Total TAT of all the processes / no of processes = ( 20 + 7 + 1 + 5 ) / 4 = 33 / 4 = 8.25 Thus, A is the correct choice.

Ans C
C
- Answer: It satisfies the mutual excluision : Process P0 and P1 could not have successfully executed their while statements at the same time as value of ‘turn’ can either be 0 or 1 but can’t be both at the same time. Lets say, when process P0 executing its while statements with the condition “turn == 1”, So this condition will persist as long as process P1 is executing its critical section. And when P1 comes out from its critical section it changes the value of ‘turn’ to 0 in exit section and because of that time P0 comes out from the its while loop and enters into its critical section. Therefore only one process is able to execute its critical section at a time. Its also satisfies bounded waiting : It is limit on number of times that other process is allowed to enter its critical section after a process has made a request to enter its critical section and before that request is granted. Lets say, P0 wishes to enter into its critical section, it will definitely get a chance to enter into its critical section after at most one entry made by p1 as after executing its critical section it will set ‘turn’ to 0 (zero). And vice-versa (strict alteration). Progess is not satisfied : Because of strict alternation no process can stop other process from entering into its critical section.
Ans A
A
- Answer:20-7 -> 13 will be in blocked state, when we perform 12 V(S) operation makes 12 more process to get chance for execution from blocked state. So one process will be left in the queue (blocked state) here i have considered that if a process is in under CS then it not get blocked by other process.
Ans C
C
- Answer: When CPU needs to search for data, and finds it in cache, it's called a HIT, else wise MISS. If data is not found in the ache, then CPU searches it in main memory. Consider x to be MISS ratio, then (1-x) would be HIT ratio. Whenever there is hit, latency is 1ms and 10ms upon miss. Time to read from main memory(disk) for all misses = x * 10 ms Time to read for all hits from cache = (1-x)*1 ms Average time: 10x + 1 -x = 9x + 1 As asked in the question, average read latency should be less than 6 ms. 9x +1 < 6 9x < 5 x < 0.5556 For 20 MB, miss rate is 60% and for 30 MB, it is 40%. Thus, the smallest cache size required to ensure an average read latency of less than 6 ms is 30 MB.
Ans C
C
- Answer:
 T2 overwrites a value that T1 writes
T1 aborts: its “remembered” values are restored.
Cascading Abort could have arised if - > Abort of T1 required abort of T2 but as T2 is already aborted , its not a cascade abort. Therefore, Option C
Option A - is not true because the given schedule is recoverable Option B - is not true as it is recoverable and avoid cascading aborts; Option D - is not true because T2 is also doing abort operation after T1 does, so NOT strict.
T2 overwrites a value that T1 writes
T1 aborts: its “remembered” values are restored.
Cascading Abort could have arised if - > Abort of T1 required abort of T2 but as T2 is already aborted , its not a cascade abort. Therefore, Option C
Option A - is not true because the given schedule is recoverable Option B - is not true as it is recoverable and avoid cascading aborts; Option D - is not true because T2 is also doing abort operation after T1 does, so NOT strict.
Ans B
B
- Answer: First group by district name is performed and total capacities obtained as following Ajmer 20 Bikaner 40 Charu 30 Dungargarh 10 Then average capacity is computed, Average Capacity = (20 + 40 + 30 + 10)/4 = 100/4 = 25. Finally districts with more than average are selected. Bikaner is 40 which is greater than average (25) Charu is 30 which is also greater than average (25). Therefore answer is 2 tuples.
Ans A
A
- Answer: For frame size to be minimum, its transmission time should be equal to twice of one way propagation delay. i.e, Tx = 2Tp suppose minimum frame size is L bits. Tx = L / B where B is the bandwidth = 20 * 10^6 bits/sec and given Tp = 40 micro seconds as Tx = 2 Tp L / B = 80 micro seconds L = B * 80 micro seconds = 20 * 10^6 bits/sec * 80 micro seconds = 1600 bits Now as the answer has to be given in Bytes, hence, 1600 / 8 bytes = 200 bytes. Thus, A is the correct answer.
Ans A
A
- Answer: For frame size to be minimum, its transmission time should be equal to twice of one way propagation delay. i.e, Tx = 2Tp suppose minimum frame size is L bits. Tx = L / B where B is the bandwidth = 20 * 10^6 bits/sec and given Tp = 40 micro seconds as Tx = 2 Tp L / B = 80 micro seconds L = B * 80 micro seconds = 20 * 10^6 bits/sec * 80 micro seconds = 1600 bits Now as the answer has to be given in Bytes, hence, 1600 / 8 bytes = 200 bytes. Thus, A is the correct answer.
Ans A
A
- Answer: 802.11 uses 5 GHz Radio Band(High Frequency) which has 23 overlapping channels rather than the 2.4 GHz frequency band which has only three non-overlapping channels. RTS(Request To Send) and CTS(Clear To Send) are control frames, which facilitate the exchange between stations and help in collision reduction and not DETECTION. As Station 1 would send data frame to Station 2, only when it receives a CTS frame. First Station 1 sends a RTS to Station 2, in response Station 2 sends back CTS. After data is received by Station 2, it send Acknowledgement frame(ACKed). As Station 2 sends a Acknowledgement to a single recipient on a network, Unicast Frames are acknowledged
Ans A
A
- Answer: To achieve 100% efficiency, the number of frames that we should send = 1 + 2 * Tp / Tt where, Tp is propagation delay, and Tt is transmission delay. So, Number of frames sent = 1 + 4.687 = 5.687 (approx 6) As the protocol used is Selective repeat, Receiver window size should be equal to Sender window size. Then, Number of distinct sequence numbers required = 6 + 6 = 12 Number of bits required to represent 12 distinct numbers = 4 So, Answer is (B)