GATE-CS-2016 (Set 1)
Ans .
D
- Explanation :
Not is already embedded in until. So, A and B are incorrect. Also, the minister is a single person, and with a singular subject, singular verb follows(ending in 's'). Thus, C is incorrect and D is the right answer.
Ans .
A
- Explanation :
Paraphrase - To express something in different words so that it becomes easy for the listener to understand. Paradox - A statement which sounds logical, but proves to be illogical when investigated. Paradigm - A way of looking or thinking (perception) about something. Paraffin - A flammable substance used in candles, polishes, etc. So, A is the correct choice.
Ans .
A
- Explanation :
Here, we are talking about figure of speech So, figurative is figure of speech meaning : Use of metamorphic meaning of words to explain your thoughts instead of literal use of them.
Ans .
C
- Explanation :
'taga' and 'care' are a matching pair in every combination. So, 'taga' surely represents 'care'. Also, note here that the second half of the word in encoded value refers to the first half of the word in the decoded value. So, 'fer' represents 'less', 'relf' represents 'free' and 'o' represents 'full'. Going by the same logic, the answer would be tagazen, i.e., C.
Ans .
D
- Explanation :
The surface area of the body will remain unchanged as when a cube is removed, it exposes three faces, which makes the number of exposed faces same as before removal. So, surface area of the body before removal = surface area of the body after removal = 6 * side * side = 6 * 4 * 4 = 96. Thus, D is the correct choice.
Ans .
B
- Explanation :
Revenue from Elegance = (27300+25222+28976+21012) * Rs. 48 = Rs. 4920480 Revenue from Smooth = (20009+19392+22429+18229) * Rs. 63 = Rs. 5043717 Revenue from Soft = (17602+18445+19544+16595) * Rs. 78 = Rs. 5630508 Revenue from Executive = (9999+8942+10234+10109) * Rs. 173 = Rs. 6796132 Total Revenue = Rs. 22390837 Fraction of Revenue for Elegance = 0.219 Fraction of Revenue for Smooth = 0.225 Fraction of Revenue for Soft = 0.251 Fraction of Revenue for Executive = 0.303 Thus, B (Executive) is the correct answer.
Ans .
D
- Explanation :
A is incorrect as it cannot be inferred that exactly 17 languages are there, because the statement says that there are atleast 17 languages on the currency note. B is incorrect because of the word 'only' in the option, which is too strong to be inferred. C is incorrect as it says 'space for all Indian languages', but the number of languages in India is not mentioned in the question. D is correct as it can be easily inferred from the statement.
Ans .
D
- Explanation :
All three can Beat S, but S loses to P only sometimes. So, (ii) can not be inferred from the given statements. Defeating in Poker is not transitive. P beats Q. Q beats R and R beats S. Yet S loses to P only sometimes, meaning that S mostly wins against P. So we can not logically infer that P is likely to beat R.
Ans .
B
- Explanation :
f(x) = 2x7 + 3x - 5
= 2x7 - 2x + 5x - 5
Putting x = 1, we get f(x) = 0. So, x-1 is a factor of f(x). Thus, B is the correct choice.
Ans .
B
- Explanation :
For exponential dependence we must have functions of form f(x) = a.(k power x) : a,k are constants and f(0)=a Let us assume: C = cycles for failure ; L = Load; a, k = constants according to question C is an exponential function of L Hence we can say, 1) C = a x (k^L) ---- > in case C is increasing exponentially 2) C = a / (k^L) ---- > in case C is decreasing exponentially we take 2nd equation and apply log to both side we get: log C + L x (log k) = log a ...... by logarithmic property given (C=100 for L=80) and (C=10000 for L=40) apply these to values to above equation, this gives us 2 equations and 2 variables: log a = log 100 + (80 x log k)...............(1) log a = log 10000 + (40 x log k)...........(2) we have 2 variables and 2 equations hence we find log a = 6 log k= 1/20 now find, [ L = (log a - log C) / (log k) ] for C=5000 cycles => L = (6 - log 5000)*20 = 46.0206 ~ 46.02 => [ANS]
Ans .
C
- Explanation :
(p ⇒ q) will give {8, 9, 10, 12} ¬r will give {8, 10, 11, 12} ¬s will give {8, 9, 10, 12} (¬r ∨ ¬s) will give {8, 9, 10, 11, 12} (p ⇒ q) ∧ (¬r ∨ ¬s) will give {8, 9, 10, 12} ¬((p ⇒ q) ∧ (¬r ∨ ¬s)) will give 11. Thus, C is the correct option.
Ans .
B
- Explanation :
The least value of 'n' for the recursion would be 3. For n = 1, number of strings = 2 (0, 1) For n = 2, number of strings = 3 (00, 01, 10) For n = 3, number of strings = 5 (000, 001, 010, 100, 101) For n = 4, number of strings = 8 (0000, 0001, 0010, 0100, 1000, 0101, 1010, 1001) ... This seems to follow Fibonacci series and the recurrence relation for it is an = an−1 + an−2. Thus, B is the correct choice.
Ans .
B
- Explanation :
Put y = x - 4. So, the problem becomes limy->0 (sin y) / y = 1. (Property of Limits on sin) Thus, B is the correct choice.
Ans .
D
- Explanation :

Ans .
C
- Explanation :
The determinant of a real matrix can never be imaginary. So, if one eigen value is complex, the other eigen value has to be its conjugate. So, the eigen values of the matrix will be 2+i, 2-i and 3. Also, determinant is the product of all eigen values. So, the required answer is (2+i)*(2-i)*(3) = (4-i2)*(3) = (5)*(3) = 15. Thus, C is the required answer.
Ans .
A
- Explanation :
The function # basically represents XOR. Following are true with XOR. 1) XOR of x with 0 is x itself. 2) XOR of x with 1 is complement of x. 3) XOR of x with x is 0. 4) XOR of x with x' is 1. XOR is represented as x'y + y'x.
Ans .
D
- Explanation :
Number is given in 2's complement representation. Since, MSB is 1, so value of this number is negative and we have to take 2's complement of given number then find its decimal value. Therefore, 2's complement of (1111 1111 1111 0101) = (1's complement of (1111 1111 1111 0101) + 1) = ((0000 0000 0000 1010) + 1) = 1011 in binary = 11 It is negative, so answer is (- 11). Option (C) is correct.
Ans .
C
- Explanation :
Total 4. 2 J-K flip- flops for synchronous counter + 2 J-K flip-flop to make 2 bit counter. Actually, when we are repeating again then after 3 we don't know that our Synchronous counter will go to which zero. To make it work right, we need to move it to 1st zero after 3 2nd zero after 1 3rd zero after 2 i.e. 0 -> 1 -> 0 -> 2 -> 0 -> 3 (from here it again go to 1st zero). In order to decide which zero to move on we use counter from 1 to 3, I have attached truth table of normal 2 bit synchronous counter using JK flip flop.
Ans .
B
- Explanation :
Maximum Memory = 4GB = 232 bytes Size of a word = 2 bytes Therefore, Number of words = 232 / 2 = 231 So, we require 31 bits for the address bus of the processor. Thus, B is the correct choice.
Ans .
A
- Explanation :
We can use circular array to implement both in O(1) time.
Ans .
D
- Explanation :
Following are different 6 Topological Sortings
a-b-c-d-e-f, a-d-e-b-c-f, a-b-d-c-e-f, a-d-b-c-e-f, a-b-d-e-c-f, a-d-b-e-c-f
Ans .
D
- Explanation :
i is integer and *p is value of a pointer to short. 1) Option 1 is wrong because we are passing "*S" as second argument check that S is not a pointer variable .So error 2) Second option is we are trying to store the value of f(i,s) into i but look at the function definition outside main it has no return type. It is simply void so that assignment is wrong. So error 3) Option 3 is wrong because of the same reason why option 1 is wrong 4) So option d is correct.
Ans .
D
- Explanation :
Insertion Sort takes Θ(n2) in worst case as we need to run two loops. The outer loop is needed to one by one pick an element to be inserted at right position. Inner loop is used for two things, to find position of the element to be inserted and moving all sorted greater elements one position ahead. Therefore the worst case recursive formula is T(n) = T(n-1) + Θ(n).
Merge Sort takes Θ(n Log n) time in all cases. We always divide array in two halves, sort the two halves and merge them. The recursive formula is T(n) = 2T(n/2) + Θ(n).
QuickSort takes Θ(n2) in worst case. In QuickSort, we take an element as pivot and partition the array around it. In worst case, the picked element is always a corner element and recursive formula becomes T(n) = T(n-1) + Θ(n). An example scenario when worst case happens is, arrays is sorted and our code always picks a corner element as pivot.
Ans .
A
- Explanation :
The shortest path may change. The reason is, there may be different number of edges in different paths from s to t. For example, let shortest path be of weight 15 and has 5 edges. Let there be another path with 2 edges and total weight 25. The weight of the shortest path is increased by 5*10 and becomes 15 + 50. Weight of the other path is increased by 2*10 and becomes 25 + 20. So the shortest path changes to the other path with weight as 45. The Minimum Spanning Tree doesn't change. Remember the Kruskal's algorithm where we sort the edges first. IF we increase all weights, then order of edges won't change.
Ans .
A
- Explanation :
Note that a and d are not swapped as the function mystery() doesn't change values, but pointers which are local to the function.
Ans .
D
- Explanation :
We can draw DFA using given grammar S → aS|bS| ε and generates ε, a, ab, abb, b, aaa, .....
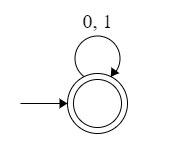
Therefore, language is {a, b}*. Option (D) is true.
Ans .
C
- Explanation :
A problem is undecidable if there is no algorithm to find the solution for it. Problem give in III and IV have no solutions, so these are undecidable.
Ans .
B
- Explanation :
Option A represents those strings which either have 0011 or 1100 as substring. Option C represents those strings which either have 00 or 11 as substring. Option D represents those strings which start with 11 and end with 00 or start with 00 and end with 11.
Ans .
D
- Explanation :
Static Single Assignment is used for intermediate code in compiler design. In Static Single Assignment form(SSA) each assignment to a variable should be specified with distinct names. We use subscripts to distinguish each definition of variables. In the given code segment, there are two assignments of the variable x x = u - t; x = y + w; and three assignments of the variable y. y = x * v; y = t - z; y = x * y So we use two variables x1, x2 for specifying distinct assignments of x and y1, y2 and y3 each assignment of y. So, total number of variables is 10 (x1, x2, y1, y2, y3, t, u, v, w, z). Static Single Assignment form(SSA) of the given code segment is: x1 = u - t; y1 = x1 * v; x2 = y1 + w; y2 = t - z; y3 = x2 * y2;
Ans .
A
- Explanation :
Turnaround time is the total time taken by the process between starting and the completion and waiting time is the time for which process is ready to run but not executed by CPU scheduler. As we know, in all CPU Scheduling algorithms, shortest job first is optimal i.ie. it gives minimum turn round time, minimum average waiting time and high throughput and the most important thing is that shortest remaining time first is the pre-emptive version of shortest job first. shortest remaining time first scheduling algorithm may lead to starvation because If the short processes are added to the cpu scheduler continuously then the currently running process will never be able to execute as they will get pre-empted but here all the processes are arrived at same time so there will be no issue such as starvation. So, the answer is Shortest remaining time first, which is answer (A).
Ans .
B
- Explanation :
Super key = Candidate Key + other attributes. But option B does not include Y which is a part of PK or candidate key.
Ans .
D
- Explanation :
D refers to Durability.
Ans .
B
- Explanation :
Old relation has functional dependency : Volume, Number -> Year as partial dependency. So it does not follow 2NF. But, there is no partial dependency in the New relation and so it satisfies 2NF as well as 3NF. Therefore, 2NF is the weakest normal form that the new database satisfies, but the old one does not. Option (B) is true.
Ans .
C
- Explanation :
DNS converts domains to IP. ARP converts IP to MAC. RARP converts MAC to IP. So, all these three protocols are used to resolve one form of address to another one. DHCP is used to assign IP dynamically which means- it doesn’t resolve addresses. Therefore, (C) DHCP is Answer.
Ans .
C
- Explanation :
In computing, a stateless protocol is a communications protocol that treats each request as an independent transaction that is unrelated to any previous request so that the communication consists of independent pairs of request and response. Examples of stateless protocols (IP) and (HTTP) Source: https://en.wikipedia.org/wiki/Stateless_protocol TCP is stateful as it maintains connection information across multiple transfers, but TCP is not an application layer protocol. Of the given protocols, only FTP and POP3 are stateful application layer protocols.
Ans .
D
- Explanation :
The expression can be re-written as: (x3 (1+ x + x2 + x3 + ...))3=x9(1+(x+x2+x3))3 Expanding (1+(x+x2+x3))3 using binomial expansion (1+(x+x2+x3))3 = 1+3(x+x2+x3)+3*2/2((x+x2+x3)2+3*2*1/6(x+x2+x3)3….. The coefficient of x3 will be 10, it is multiplied by x9 outside, so coefficient of x12 is 10.
Ans .
C
- Explanation :
a1 = 8 an = 6n2 + 2n + an-1 an = 6[n2 + (n-1)2] + 2[n + (n-1)] + an-2 Continuing the same way till n=2, we get an = 6[n2 + (n-1)2 + (n-2)2 + ... + (2)2] + 2[n + (n-1) + (n-2) + ... + (2)] + a1 an = 6[n2 + (n-1)2 + (n-2)2 + ... + (2)2] + 2[n + (n-1) + (n-2) + ... + (2)] + 8 an = 6[n2 + (n-1)2 + (n-2)2 + ... + (2)2] + 2[n + (n-1) + (n-2) + ... + (2)] + 6 + 2 an = 6[n2 + (n-1)2 + (n-2)2 + ... + (2)2 + 1] + 2[n + (n-1) + (n-2) + ... + (2) + 1] an = (n)*(n+1)*(2n+1) + (n)(n+1) = (n)*(n+1)*(2n+2) an = 2*(n)*(n+1)*(n+1) = 2*(n)*(n+1)2 Now, put n=99. a99 = 2*(99)*(100)2 = 1980000 = K * 104 Therefore, K = 198. Thus, C is the correct choice.
Ans .
B
- Explanation :
Let us assume: f(1) = x. Then, f(2) = f(2/2) = f(1) = x
f(3) = f(3+5) = f(8) = f(8/2) = f(4/2) = f(2/1) = f(1) = x
Similarly, f(4) = x
f(5) = f(5+5) = f(10/2) = f(5) = y.
So it will have two values. All multiples of 5 will have value y and others will have value x. It will have 2 different values.
Ans .
A
- Explanation :
A fair coin is flipped twice => {(HH),(HT),(TH),(TT)} four outcomes. Given, if (TH) comes, output ‘Y’. If (HH),or (HT) comes, output ‘N’. If (TT) comes, again flip coin twice. Let, P = probability of getting (TH) or output ‘Y’=1/4. Let, Q= probability of getting (TT) or again flipping coin twice =1/4. Then, probability of getting output ‘Y’= probability of event ‘P’ occurring 1st time (OR) probability of event ‘P’ occurring 2nd time (OR) probability of event ‘P’ occurring 3rd time+……… =P+QP+QQP+QQQP+QQQQP……. =(1/4)+(1/4*1/4)+ (1/4*1/4*1/4)+( 1/4*1/4*1/4*1/4)+…….. It is and infinite GP where, ‘a’=1/4 and ‘r’= 1/4. So, answer= sum= (1/4)/(1-(1/4))=1/3=0.33
Ans .
D
- Explanation :
Assume P=0 and Q=0 The output should be R' Only option D satisfies this case. Hence, D is the correct choice.
Ans .
C
- Explanation :
Size of data count register of the DMA controller = 16 bits Data that can be transferred in one go = 216 bytes = 64 kilobytes File size to be transferred = 29154 kilobytes So, number of times the DMA controller needs to get the control of the system bus from the processor to transfer the file from the disk to main memory = ceil(29154/64) = 456 Thus, C is the correct answer.
Ans .
A
- Explanation :
Throughput of 1st case T1: 1/max delay =1/800 Throughput of 2nd case T2: 1/max delay= 1/600 %age increase in throughput: (T2-T1)/T2 = ( (1/600) - (1/800) ) / (1/800) = 33.33%
Ans .
B
- Explanation :
if fan-in != number of inputs then we will have delay in each level, as given below. If we have 8 inputs, and OR gate with 2 inputs, to build an OR gate with 8 inputs, we will need 4 gates in level-1, 2 in level-2 and 1 in level-3. Hence 3 gate delays, for each level. Similarly an n-input gate constructed with 2-input gates, total delay will be O(log n).
Ans .
D
- Explanation :
#include
int max(int *p, int n) { int a=0, b=n-1; while (a!=b) { if (p[a] <= p[b]) { a = a+1; } else { b = b-1; } } return p[a]; } int main() { int arr[] = {10, 5, 1, 40, 30}; int n = sizeof(arr)/sizeof(arr[0]); std::cout << max(arr, 5); }
Ans .
A
- Explanation :
count(3) will print value of n and d. So 3 1 will be printed and d will become 2. Then count(2) will be called. It will print value of n and d. So 2 2 will be printed and d will become 3. Then count(1) will be called. It will print value of n and d. So 1 3 will be printed and d will become 4. Now count(1) will print value of d which is 4. count(1) will finish its execution. Then count(2) will print value of d which is 4. Similarly, count(3) will print value of d which is 4. So series will be A.
Ans .
D
- Explanation :
a = 3; void main() { // Calls m with 'a' being passed by reference // Since there is no local 'a', global 'a' is passed. m(a); } // y refers to global 'a' as main calls "m(a)" void m(y) { // A local 'a' is created with value 1. a = 1; // a = 3 - 1 = 2 a = y - a; // Local 'a' with value 2 is passed by // reference to n() n(a); // Modified local 'a' is printed print(a); } // Local 'a' of m is passed here void n(x) { // x = 2 * 2 [Note : again local 'a' is referred // because of dynamic scoping] x = x * a; // 4 is printed and local 'a' of m() is also // changed to 4. print(x); }
Ans .
B
- Explanation :
For this question, we have to slightly tweak the delete_min() operation of the heap data structure to implement the delete(i) operation. The idea is to empty the spot in the array at the index i (the position at which element is to be deleted) and replace it with the last leaf in the heap (remember heap is implemented as complete binary tree so you know the location of the last leaf), decrement the heap size and now starting from the current position i (position that held the item we deleted), shift it up in case newly replaced item is greater than the parent of old item (considering max-heap). If it’s not greater than the parent, then percolate it down by comparing with the child’s value. The newly added item can percolate up/down a maximum of d times which is the depth of the heap data structure. Thus we can say that complexity of delete(i) would be O(d) but not O(1).
Ans .
B
- Explanation :
Let vertices be 0, 1, 2 and 3. x directly connects 2 to 3. The shortest path (excluding x) from 2 to 3 is of weight 12 (2-1-0-3).
Ans .
B
- Explanation :
One graph that has maximum possible weight of spanning tree
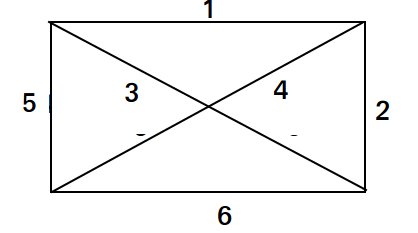
Ans .
B
- Explanation :
I is NOT true. Let G=(V, E) be a rectangular graph where V = {a, b, c, d} and E = {ab, bc, cd, da, ac}. Let the edges have weights: ab = 1, bc = 2, cd = 4, da = 5, ac = 3. Then, clearly, ac is the lightest edge of the cycle cdac, however, the MST abcd with cost 7 (= ab + bc + cd) does not include it. Let the edges have weights: ab = 6, bc - 7, cd = 4, da = 5, ac = 3. Then, again, ac is the lightest edge of the cycle cdac, and, the MST bacd with cost 13 (= ba + ac + cd) includes it. So, the MSTs of G may or may not include the lightest edge. II is true Let the heavies edge be e. Suppose the minimum spanning tree which contains e. If we add one more edge to the spanning tree we will create a cycle. Suppose we add edge e' to the spanning tree which generated cycle C. We can reduce the cost of the minimum spanning tree if we choose an edge other than e from C for removal which implies that e must not be in minimum spanning tree and we get a contradiction.
Ans .
C
- Explanation :
The worst case happens when the queue is sorted in decreasing order. In worst case, loop runs n*n times.
Queue: 4 3 2 1
Stack: Empty
3 2 1
4
3 2 1 4
Empty
2 1 4
3
2 1 4 3
Empty
1 4 3
2
1 4 3 2
Empty
4 3 2
1
3 2
1 4
3 2 4
1
2 4
1 3
2 4 3
1
4 3
1 2
3
1 2 4
3 4
1 2
4
1 2 3
Empty
1 2 3 4
Ans .
D
- Explanation :
In G1, there will be atleast 1 b becase S->B and B->b. But no of A’s can be 0 as well and no of A and B are independent. In G2, either we can take S->aA or S->bB. So it must have atleast 1 a or 1 b. So option D is correct.
Ans .
D
- Explanation :
In the given PDA we can number the states as q1, q2 and q3 from left to right.
The transitions of the PDA are as follows:
(q1, a, Z) ->(q1, XZ )
(q1, a, X) ->(q1, XX )
(q1, b, X) ->(q2, € )
(q2, b, X) ->(q2, € )
(q2, €, Z) ->(q3, Z)
As initial state is the final state hence null string is always accepted by the PDA. The first two transitions show that state remains q1 (final state) on ‘a’ input alphabet and with every ‘a’ we push X onto the stack. Hence an is always accepted for n≥0. Transitions 3 and 4 shows that for input alphabet ‘b’ and stack symbol X (i.e. ‘a’ occurred in the string) we can pop X from the stack. Transition 5 shows that we can move to the final state (q3) only when the string is empty and stack symbol is Z. This is possible when we have popped all X from the stack i.e. ‘b’ occurred exactly the same times as ‘a’. Hence anbn is always accepted for n≥0. The language accepted by the PDA is { an | n≥0 } U { anbn | n≥0 } and is a Deterministic CFL. (anbn | n≥0 is not regular but is accepted by a PDA). Hence option (D).
Ans .
C
- Explanation :
Since X is recursive and recursive language is closed under complement. So X’ is also recursive. Since Z ≤ X’ is recursive. (Rule : if Z is reducible to X’ , and X’ is recursive, then Z is recursive.) Option (B) and (D) is eliminated. And Y is recursive enumerable but not recursive, so Y’ cannot be recursively enumerable. Since Y’ reduces to W. And we know complement of recursive enumerable is not recursive enumerable and therefore, W is not recursively enumerable. So Correct option is (C). Here Y’ is complement of Y and X’ is complement of X.
Ans .
D
- Explanation :
= 2 - 5 + 1 - 7 * 3 = 2 - 6 - 7 * 3 = 2 - (-1) * 3 = 3 * 3 = 9
Ans .
C
- Explanation :
Bottom up parser builds the parse tree from bottom to up, i.e from the given string to the starting symbol. The given string is aab and starting symbol is S. so the process is to start from aab and reach S. =>aab ( given string) =>aSb (after reduction by S->a, and hence print 2) =>aA (after reduction by A->Sb, and hence print 3) =>S (after reduction by S->aA, and hence print 1) As we reach the starting symbol from the string, the string belongs to the language of the grammar. Another way to do the same thing is :- bottom up parser does the parsing by RMD in reverse. RMD is as follows: =>S => aA (hence, print 1) => aSb (hence, print 3) => aab (hence, print 2) If we take in Reverse it will print : 231
Ans .
A
- Explanation :
Size of memory = 240 Page size = 16KB = 214 No of pages= size of Memory/ page size = 240 / 214 = 226 Size of page table = 226 * 48/8 bytes = 26*6 MB =384 MB Thus, A is the correct choice.
Ans .
B
- Explanation :
The head movement would be : 63 => 87 24 movements, 87 => 92 5 movements, 92 => 121 29 movements, 121 => 191 70 movements, 191 --> 10 0 movement, 10 => 11 1 movement, 11 => 38 27 movements, 38 => 47 9 movements, Total head movements = 165
Ans .
B
- Explanation :
LIFO stands for last in, first out a1 to a10 will result in page faults, So 10 page faults from a1 to a10. Then a11 will replace a10(last in is a10), a12 will replace a11 and so on till a20, so 10 page faults from a11 to a20 and a20 will be top of stack and a9…a1 are remained as such. Then a1 to a9 are already there. So 0 page faults from a1 to a9. a10 will replace a20, a11 will replace a10 and so on. So 11 page faults from a10 to a20. So total faults will be 10+10+11 = 31. Optimal a1 to a10 will result in page faults, So 10 page faults from a1 to a10. Then a11 will replace a10 because among a1 to a10, a10 will be used later, a12 will replace a11 and so on. So 10 page faults from a11 to a20 and a20 will be top of stack and a9…a1 are remained as such. Then a1 to a9 are already there. So 0 page faults from a1 to a9. a10 will replace a1 because it will not be used afterwards and so on, a10 to a19 will have 10 page faults. a20 is already there, so no page fault for a20. Total faults 10+10+10 = 30. Difference = 1
Ans .
A
- Explanation :
Mutual exclusion is satisfied:
All other processes j started before i must have value (i.e. t[j]) less than the value of process i (i.e. t[i]) as function pMax() return a integer not smaller than any of its arguments. So if anyone out of the processes j have positive value will be executing in its critical section as long as the condition t[j] > 0 && t[j] <= t[i] within while will persist. And when this j process comes out of its critical section, it sets t[j] = 0; and next process will be selected in for loop. So when i process reaches to its critical section none of the processes j which started earlier before process i is in its critical section. This ensure that only one process is executing its critical section at a time.
Deadlock and progress are not satisfied:
while (t[j] != 0 && t[j] <=t[i]); because of this condition deadlock is possible when value of j process becomes equals to the value of process i (i.e t[j] == t[i]). because of the deadlock progess is also not possible (i.e. Progess == no deadlock) as no one process is able to make progress by stoping other process.
Bounded waiting is also not satisfied:
In this case both deadlock and bounded waiting to be arising from the same reason as if t[j] == t[i] is possible then starvation is possible means infinite waiting.
Ans .
A
- Explanation :
The above scenario is Conservative 2PL( or Static 2PL). In Conservative 2PL protocol, a transaction has to lock all the items it access before the transaction begins execution. It is used to avoid deadlocks. Also, 2PL is conflict serializable, therefore it guarantees serializability. Therefore option A Advantages of Conservative 2PL : No possibility of deadlock. Ensure serializability. Drawbacks of Conservative 2PL : Less throughput and resource utilisation because it holds the resources before the transaction begins execution. Starvation is possible since no restriction on unlock operation. 2pl is a deadlock free protocol but it is difficult to use in practice.
Ans .
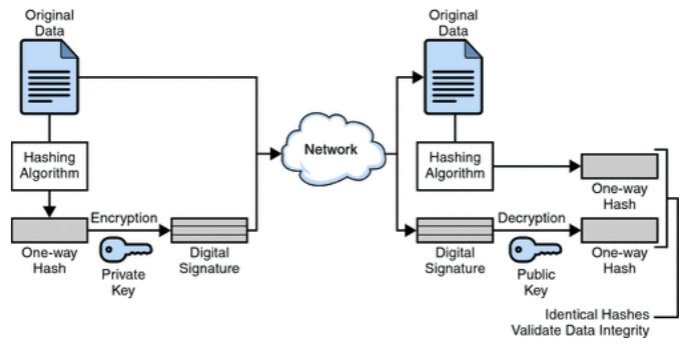
B
- Explanation :
Digital signature are electronic signatures which ensures the integrity ,non repudiation and authenticity of message.Message digest is a hash value generated by applying a function on it. Message digest is encrypted using private key of sender ,so it can only be decrypted by public key of sender.This ensures that the message was sent by the known sender. Message digest is sent with the original message to the receiving end,where hash function is used on the original message and the value generated by that is matched with the message digest.This ensures the integrity and thus,that the message was not altered. Digital signature uses private key of the sender to sign digest. So option B is correct as it is encrypting digest of message H(m) using its private key K-B.
Ans .
D
- Explanation :
MTU = 100 bytes Size of IP header = 20 bytes So, size of data that can be transmitted in one fragment = 100 - 20 = 80 bytes Size of data to be transmitted = Size of datagram - size of header = 1000 - 20 = 980 bytes Now, we have a datagram of size 1000 bytes. So, we need ceil(980/80) = 13 fragments. Thus, there will be 13 fragments of the datagram. So, D is the correct choice.
Ans .
A
- Explanation :
Token bucket is a congestion control algorithm for data transfer. It takes tokens to synchronize between the rate of incoming and outgoing data. Since, the bucket is initially full, it already has 1 MB to transmit so it will be transmitted instantly. So, we are left with only (12 - 1), i.e. 11 MB of data to be transmitted. Time required to send the 11 MB will be 11 * 0.1 = 1.1 sec The above image is adopted from here.
Ans .
A
- Explanation :
Total time = Transmission-Time + 2* Propagation-Delay + Ack-Time.
Trans. time = (1000*8)/80*1000 = 0.1 sec
2*Prop-Delay = 2*100ms = 0.2 sec
Ack time = 100*8/8*1000 = 0.1 sec.
Total Time = 0.1 + 0.2 + 0.1 = 0.4 sec.
Throughput = ((L/B)/Total time) * B,
L = data packet to be sent and
B = BW of sender.
Throughput = L/Total Time
= 1000/0.4
= 2500 bytes/sec.