GATE CS 2001
Ans .
1
- Explanation :
Singular Matrix: A square matrix is singular if and only if its determinant
value is 0. S1 is True: The sum of two singular n × n matrices may be
non-singular It can be seen be taking following example.
The following two matrices are singular, but their sum is non-singular
Ans .
2
- Explanation :
So basically, we have to tell whether these relations are equivalence or not.
R1(a,b)
Reflexive : Yes, because (a+a) is even.
Symmetrix : Yes, (a+b) is even ⟹ (b+a) is even.
Transitive : Yes, because (a+b) is even and (b+c) is even ⟹ (a+c) is even.
So R1 is equivalence relation.
R2(a,b)
Reflexive : No, because (a+a) is even.
So R2 is not equivalence relation.
R3(a,b)
Reflexive : Yes, because a.a > 0.
Symmetrix : Yes, a.b > 0 ⟹ b.a > 0.
Transitive : Yes, because a.b > 0 and b.c > 0 ⟹ a.c > 0.
So R3 is equivalence relation.
R4(a,b)
Reflexive : Yes, because |a-a| ≤ 2.
Symmetrix : Yes, |a-b| ≤ 2 ⟹ |b-a| ≤ 2.
Transitive : No, because |a-b| ≤ 2 and |b-c| ≤ 2 ⇏ (a-c) is even.
So R4 is not equivalence relation.
So option (b) is correct..
Ans .
1
- Explanation :
Explanation: The concept behind this solution is: a) Satisfiable If there is an assignment of truth values which makes that expression true. b) UnSatisfiable If there is no such assignment which makes the expression true c) Valid If the expression is Tautology Here, P => Q is nothing but –P v Q F1: P => -P = -P v –P = -P F1 will be true if P is false and F1 will be false when P is true so F1 is Satisfiable F2: (P => -P) v (-P => P) which is equals to (-P v-P) v (-(-P) v P) = (-P) v (P) = Tautology So, F1 is Satisfiable and F2 is valid Option (a) is correct.
Ans .
1
- Explanation :
Explanation: We can easily build a DFA for S1. All we need to check is whether input string has even number of 0's. Therefore S1 is regular. We can't make a DFA for S2. For S2, we need a stack. Therefore S2 is not regular.
Ans .
2
- Explanation :
Refer http://en.wikipedia.org/wiki/Context-free_language#Closure_properties
Ans .
2
- Explanation :
Refer http://en.wikipedia.org/wiki/Powerset_construction
Ans .
2
- Explanation :
Temporal locality refers to the reuse of specific data and/or resources within relatively small time durations. Spatial locality refers to the use of data elements within relatively close storage locations. To exploit the spatial locality, more than one word are put into cache block.
Ans .
4
- Explanation :
Ans .
4
- Explanation :
A low memory can be connected to 8085 by using READY signal, Communication is only possible when READY signal is set .So (D) is correct option
Ans .
1
- Explanation :
Stack pointer register hold the address of top of stack, which is the location of memory at which CPU should resume its execution after servicing some interrupt or subroutine call. So if SP register is not available then no subroutine call instructions are possible. So (A) is correct option.
Ans .
1
- Explanation :
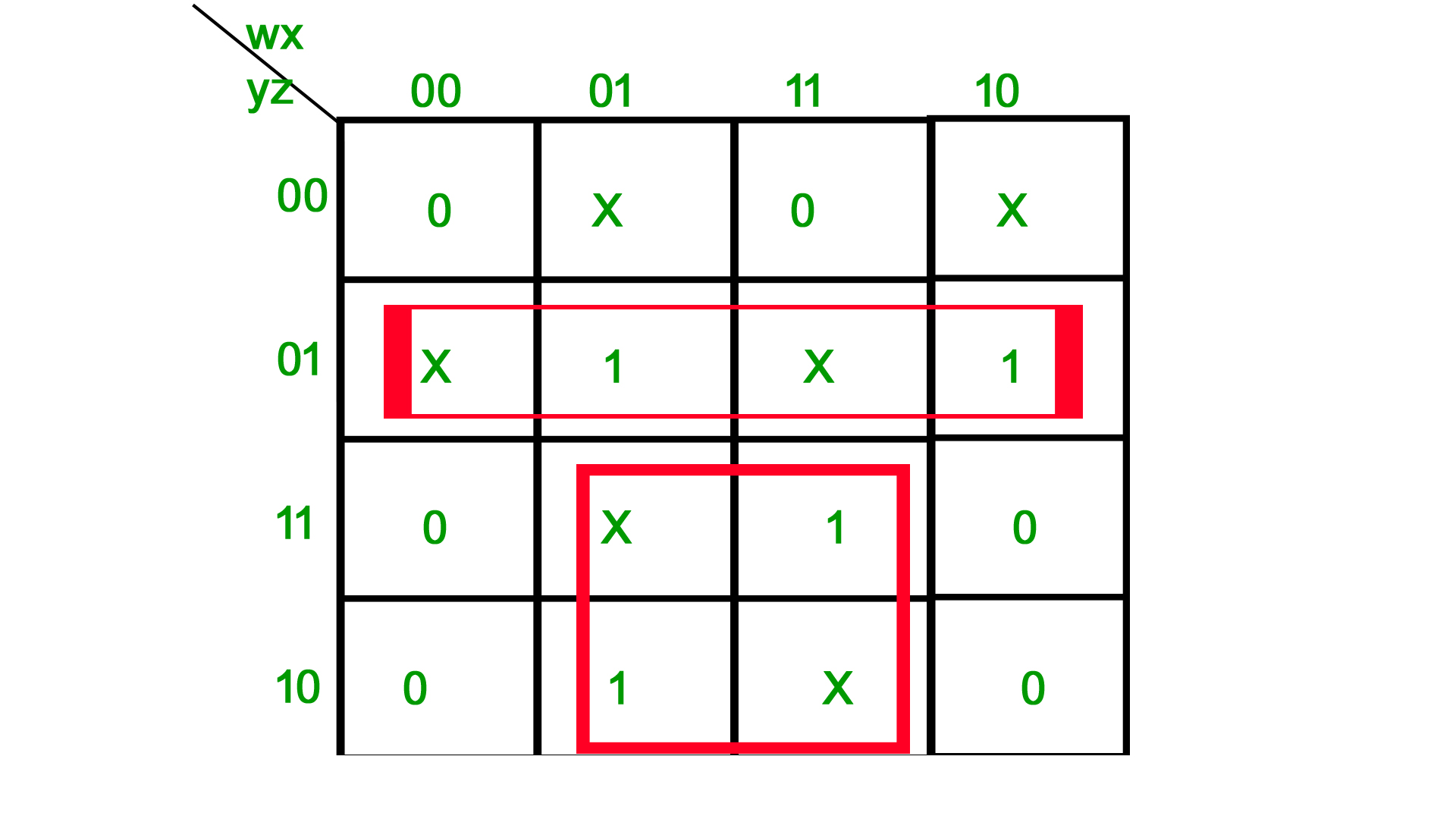
On solving we get xy+y’z so ans is (A) part
Ans .
3
- Explanation :
Software interrupts are required by CPU to obtain System services which need execution of privileged instructions. A software interrupt is caused either by an exceptional condition in the processor itself, or a special instruction in the instruction set which causes an interrupt when it is executed. The former is often called a trap or exception and is used for errors or events occurring during program execution that are exceptional enough that they cannot be handled within the program itself.. An interrupt alerts the processor to a high-priority condition requiring the interruption of the current code the processor is executing. The processor responds by suspending its current activities, saving its state, and executing a function called an interrupt handler (or an interrupt service routine, ISR) to deal with the event. This interruption is temporary, and, after the interrupt handler finishes, the processor resumes normal activities. So (C) is correct option
Ans .
2
- Explanation :
Software interrupt occurs when a program terminates or a program invokes some system calls to request for some services like I/O request etc. This type of interrupt is caused by the program in user mode. Thus, a software interrupt is required to switch from kernel (privilege) mode to user (non-privilege) mode.
Ans .
3
- Explanation :
Randomized quicksort has expected time complexity as O(nLogn), but worst case time complexity remains same. In worst case the randomized function can pick the index of corner element every time.
Ans .
2
- Explanation :
Binary heaps can be represented using arrays: storing elements in an array and using their relative positions within the array to represent child-parent relationships. For the binary heap element stored at index i of the array, Parent Node will be at index: floor(i/2) Left Child will be at index: 2i Right child will be at index: 2*i + 1
Ans .
2
- Explanation :
Any constant power of Logn is asymptotically smaller than n. Proof: Given f(n) =n2Logn and g(n) = n (logn)10 In these type of questions, we suggest you to first cancel out the common factor in both the function. After removing these, we are left with f(n) = n and g(n) = (logn)9. Removing a factor of nlogn from both functions. Now n is very very large asymptotically as compared to any constant integral power of (logn) which we can verify by substituting very large value say 2100. f(2100) = 2100 = 1030 and g(2100) = 1009 = 1018. Always remember to substitute very large values of n in order to compare both these functions. Otherwise you will arrive at wrong conclusions because if f(n) is asymptotically larger than g(n) that means after a particular value of n, f(n) will always be greater that g(n)
Ans .
3
- Explanation :
Relocation of code is the process done by the linker-loader when a program is copied from external storage into main memory. A linker relocates the code by searching files and libraries to replace symbolic references of libraries with actual usable addresses in memory before running a program. Thus, option (C) is the answer.
Ans .
1
- Explanation :
A grammar is ambiguous if there exists a string s such that the grammar has more than one leftmost derivations for s. We could also come up with more than one rightmost derivations for a string to prove the above proposition, but not both of right and leftmost. An unambiguous grammar can have different rightmost and leftmost derivations. 2. LL parser is top-down by nature. Leftmost derivation is, intuitively, expanding or top-down in fashion, hence such convention. Rightmost derivation, on the other hand, seems like a compressing or bottom-up thing. 3. LALR is more powerful than SLR, even when both have the same LR(0) states, due to the fact that SLR checks for lookaheads by looking at FIRST and FOLLOW from the grammar after constructing its parse table and on the other hand, LALR computes lookaheads from the LR(0) states while constructing the parse table, which is a better method. 4. An ambiguous grammar can never be LR(k) for any k, because LR(k) algorithm aren’t designed to handle ambiguous grammars. It would get stuck into undecidability problem, if employed upon an ambiguous grammar, no matter how large the constant k is
Ans .
2
- Explanation :
Throughput means total number of tasks executed per unit time i.e. sum of waiting time and burst time. Shortest job first scheduling is a scheduling policy that selects the waiting process with the smallest execution time to execute next. Thus, in shortest job first scheduling, shortest jobs are executed first. This means CPU utilization is maximum. So, maximum number of tasks are completed. Thus, option (B) is correct.
Ans .
2
- Explanation :
Swap space is an area on disk that temporarily holds a process memory image. When memory is full and process needs memory, inactive parts of process are put in swap space of disk.
Ans .
3
- Explanation :
%
Ans .
3
- Explanation :
A disk driver is software which enables communication between internal hard disk (or drive) and computer. It allows a specific disk drive to interact with the remainder of the computer.
Ans .
3
- Explanation :
Dependency Preserving Decomposition: Decomposition of R into R1 and R2 is a dependency preserving decomposition if closure of functional dependencies after decomposition is same as closure of of FDs before decomposition. A simple way is to just check whether we can derive all the original FDs from the FDs present after decomposition. In the above question R(A, B, C, D) is decomposed into R1 (A, B) and R2(C, D) and there are only two FDs A -> B and C -> D. So, the decomposition is dependency preserving
Ans .
4
- Explanation :
(A) This is simple query as we need to find (X, Y) for a given X. (B) This is also simple as need to find (X, X) (C) :-> Cycle < 3 . Means cycle of length 1 & 2. Cycle of length 1 is easy., Same as self loop. Cycle of length 2 is is also not too hard to compute. Though it'll be little complex, will need to do like (X,Y) & (Y, X ) both present & X != Y,. We can do this with constant RA query. (D) :-> This is most hard part. Here we need to find closure of vertices. This will need kind of loop. If the graph is like skewed tree, our query must loop for O(N) Times. We can't do with constant length query here. Answer is :-> D
Ans .
3
- Explanation :
The above expression evaluates A = a for tables r and s Option A : is only displaying attributes of table r on the select condition Option B : is only displaying attributes of table r Option C: evaluates A = a by joining tables r and s efficiently , thus correct Therefore, Answer C
Ans .
2
- Explanation :
This is a basic permutation combination question. Considering two cases : numbers ending with 0 and not ending with 0: Numbers ending with 0 1{first place: 0} ∗9{fourth place: 9 possibilities, 1-9} ∗8{third place: 8 possibilities left} ∗7{second place: 7 possibilities left} = 504 Numbers ending with non-0 4{first place: 2,4,6,8} ∗8{fourth place: 8 possibilities left, 1-9}∗8{third place: 8 possibilities left b/w 0-9} ∗7{second place: 7 possibilities left b/w 0-9} = 2592 Total = 2296 See https://in.answers.yahoo.com/question/index?qid=20090417083307AA61h9I
Ans .
3
- Explanation :
S1: A ∩ (B ∪ C) Here S1 is finite where A, B, C are infinite We’ll prove this by taking an example. Let A = {Set of all even numbers} = {2, 4, 6, 8, 10...} Let B = {Set of all odd numbers} = {1, 3, 5, 7...........} Let C = {Set of all prime numbers} = {2, 3, 5, 7, 11, 13......} B U C = {1, 2, 3, 5, 7, 9, 11, 13......} A ∩ (B ∪ C) Will be equals to: {2} which is finite. I.e. using A, B, C as infinite sets the statement S1 is finite. So, statement S1 is correct. S2: There exists two irrational numbers x, y such that (x+y) is rational To prove this statement as correct, we take an example. Let X = 2-Sqrt (3), Y = 2+Sqrt (3) => X, Y are irrational X+Y = 2+Sqrt (3) + 2-Sqrt (3) = 2+2 = 4 So, statement S2 is also correct. Answer is Option C Both Statements S1, S2 are correct.
Ans .
1
- Explanation :
S1 : correct, because both L.H.S. and R.H.S. will contain exactly the images of all elements in E and F. S2 : false, let f is a constant function s.t. range is only {1}. Now let E and F be two partitions of set A, then clearly A ∩ B is φ, and so f (φ) is not defined, but f (E) ∩ f (F) is {1}. So S1 is true, but S2 is false. So option (A) is correct.
Ans .
2
- Explanation :
Prob(all accidents on Monday) = 1/7 7. Similarly for other 6 days. So total probability = 7 * 1/7 7 = 1/7 6. So option (B) is correct
Ans .
4
- Explanation :
We construct a DFA for strings divisible by 6. It requires minimum 6 states as length of string mod 6 = 0, 1, 2, 3, 4, 5 We construct a DFA for strings divisible by 8. It requires minimum 8 states as length of string mod 8 = 0, 1, 2, 3, 4, 5, 6, 7 If first DFA is minimum and second DFA is also minimum then after merging both DFAs resultant DFA will also be minimum. Such DFA is called as compound automata. So, minimum states in the resultant DFA = 6 * 8 = 48 Thus, option (D) is the answer.
Ans .
2
- Explanation :
This problem is a State Entry Problem. State entry problem can be reduced to halting problem. We construct a turing machine M with final state ‘q’. We run a turing machine R (for state entry problem) with inputs : M, q, w . We give ‘w’ as input to M. If M halts in the final state ‘q’ then R accepts the input. So, the given problem is partially decidable. If M goes in an infinite loop then M can not output anything. So, R rejects the input. So, the given problem becomes undecidable. Thus, option (B) is the answer.
Ans .
3
- Explanation :
Q0 = 0 (given) Therefore, Q0' = 1 During the first clock cycle nothing will change since input doesn't come before rising edge of the clock cycle Q0' becomes ’0’ on rising edge of next clock cycle. Therefore, for only one clock cycle D1 will be ‘1’.
Ans .
1
- Explanation :
Indexed addressing is used for array implementation where each element has indexes. Base register is used to relocatable code which starts from base address and then all local addresses are added to base address. Indirect addressing is done when array is passed as parameter where only name is passed. So (A) is correct option.
Ans .
3
- Explanation :
-53910 = 1 010 0001 10112 ( Leftmost 1 denotes negative ) One's complement = 1 101 1110 0100 Two's complement = 1 101 1110 0101 Converting this two's complement to hexadecimal form, we get DE5. Thus, C is the correct choice.
Ans .
3
- Explanation :
g = (a and x1') or (b and x1) g = (1 and x1’) or (0 and x1) g = x1’ f = ac’ + bc f = (a and x2') or (b and x2) f = (g and x2') or (x1 and x2) f = x1’x2’ + x1x2 Thus, option (C) is the answer.
Ans .
2
- Explanation :
Ans .
3
- Explanation :
Push ‘r’ consist of following operations : M[SP ]!R SP!SP-1 ‘r’ is stored at memory at address stack pointer currently is, this take 2 clock cycles SP is then decremented to point to next top of stack So total cycles=3 So (B) is correct option
Ans .
3
- Explanation :
%
Ans .
4
- Explanation :
There are total n*(n-1)/2 possible edges. For every edge, there are to possible options, either we pick it or don't pick. So total number of possible graphs is 2n(n-1)/2.
Ans .
2
- Explanation :
A queue can be implemented using two stacks. Let queue to be implemented be q and stacks used to implement q be stack1 and stack2. q can be implemented in two ways: Method 1 (By making enQueue operation costly) This method makes sure that newly entered element is always at the top of stack 1, so that deQueue operation just pops from stack1. To put the element at top of stack1, stack2 is used. enQueue(q, x)
1) While stack1 is not empty, push everything from satck1 to stack2.
2) Push x to stack1 (assuming size of stacks is unlimited).
3) Push everything back to stack1.
dnQueue(q)
1) If stack1 is empty then error
2) Pop an item from stack1 and return it Method 2 (By making deQueue operation costly) In this method, in en-queue operation, the new element is entered at the top of stack1. In de-queue operation, if stack2 is empty then all the elements are moved to stack2 and finally top of stack2 is returned. enQueue(q, x) 1) Push x to stack1 (assuming size of stacks is unlimited). deQueue(q) 1) If both stacks are empty then error. 2) If stack2 is empty While stack1 is not empty, push everything from satck1 to stack2. 3) Pop the element from stack2 and return it.
Ans .
2
- Explanation :
Here, we are passing the variables by call by reference. This means that the changes that we will make in the parameter would be reflected in the passed argument. Here, the first variable passed in the function func1 (i.e., y) points to the address of the variable x. Similarly, the second variable passed in the function func1 (i.e., x) points to the address of the variable y and the third variable passed in the function func1 (i.e., x) points to the address of the variable z. So, we have y = y + 4 ⇒ y = 10 + 4 = 14 and z = x + y + z ⇒ z = 14 + 14 + 3 = 31 z will be returned to x. So, x = 31 and y will remain 3. Thus, the correct choice is B.
Ans .
3
- Explanation :
%
Ans .
4
- Explanation :
In static scoping or compile-time scoping the free variables (variables used in a function that are neither local variables nor parameters of that function) are referred as global variables because at compile only global variables are available. In dynamic scoping or run-time scoping the free variables are referred as the variables in the most recent frame of function call stack. In the given code in the function call of procedure W the local variable x is printed i.e 4. Under dynamic scoping if x would have not been there in procedure W then we would refer to x of the function in function call stack i.e procedure D and the main function but since x is a local variable not a free variable we referred to the local variable hence 4 will be printed
Ans .
3
- Explanation :
Scheduler process doesn’t interrupt any process, it’s Job is to select the processes for following three purposes. Long-term scheduler(or job scheduler) –selects which processes should be brought into the ready queue Short-term scheduler(or CPU scheduler) –selects which process should be executed next and allocates CPU. Mid-term Scheduler (Swapper)- present in all systems with virtual memory, temporarily removes processes from main memory and places them on secondary memory (such as a disk drive) or vice versa. The mid-term scheduler may decide to swap out a process which has not been active for some time, or a process which has a low priority, or a process which is page faulting frequently, or a process which is taking up a large amount of memory in order to free up main memory for other processes, swapping the process back in later when more memory is available, or when the process has been unblocked and is no longer waiting for a resource.
Ans .
3
- Explanation :
Ans .
2
- Explanation :
%
Ans .
3
- Explanation :
Background : Lossless-Join Decomposition: Decomposition of R into R1 and R2 is a lossless-join decomposition if at least one of the following functional dependencies are in F+ (Closure of functional dependencies)
R1 ∩ R2 → R1
OR
R1 ∩ R2 → R2
dependency preserving :
Decomposition of R into R1 and R2 is a dependency preserving decomposition if closure of functional dependencies after decomposition is same as closure of of FDs before decomposition. A simple way is to just check whether we can derive all the original FDs from the FDs present after decomposition. Question : We know that for lossless decomposition common attribute should be candidate key in one of the relation. A) A->B, B->CD R1(AB) and R2(BCD) B is the key of second and hence decomposition is lossless. B) A->B, B->C, C->D R1(AB) , R2(BC), R3(CD) B is the key of second and C is the key of third, hence lossless. C) AB->C, C->AD R1(ABC), R2(CD) C is key of second, but C->A violates BCNF condition in ABC as C is not a key. We cannot decompose ABC further as AB->C dependency would be lost. D) A ->BCD Already in BCNF. Therefore, Option C AB->C, C->AD is the answer.
Ans .
3
- Explanation :
A tuple relational calculus expression may at times generate an infinite relation. It may also contain values that do not even appear in the database. Such expressions are said to be unsafe. A safe tuple relational calculus expression is the one which surely generates finite results. To pose a restriction over the unsafety of expressions in tuple relational calculus there is a concept of domain of a tuple relational formula denoted by dom (P) is the set of values referenced by P i.e. values there in P or values in tuple of a relation mentioned in P. Eg: The expression {t | ¬ (t € R)} is not safe because there are infinitely many tuples that do not occur in R relation . In the above question Options (A), (B) and option (D) produce finite set of tuples as each gives out tuples restricted from a particular relation and hence are safe. Option (C) produces infinite number of tuples as it generates all the tuples not in R1 i.e. it can have tuples from any other relation other than R1.Hence it is not safe.
Ans .
3
- Explanation :
In the above question, the relation schema is ( lb , ub ), where lb is the primary key, and ub is the foreign key which is referencing the primary key of its own relation. Hence the table geq is both the master ( which has the referenced key ) as well as the child table (which has the referencing key). The table has two constraint, one is that if there is a tuple ( x, y ), then y is greater than or equal to x, And the other is referential integrity constraint, which is on-cascade-delete on the foreign key. On-cascade-delete says, that "When the referenced row is deleted from the other table (master table), then delete also from the child table". Suppose the instance in the given relation is the following:
x y
-----
5 6
4 5
3 4
6 6
Now if we delete tuple (5,6) then tuple ( 4,5 ) should also be deleted ( as 5 in the tuple (4, 5) was referencing to 5 in the tuple(5,6) which no longer exist, hence the referencing tuple should also be deleted), and as (4,5) got deleted hence tuple (3,4) should also be deleted for the same reason. Therefore in total 3 rows have to be deleted if tuple ( 5,6 ) is deleted. Now from the above instance we can say that if (x,y), i.e. ( 5,6 ) gets deleted then a tuple ( z, w) i.e, ( 3, 4) is also deleted. And we can see here that w < x. Hence option C