GATE-CS-2004
Ans .
C
- Explanation :
The main goal of structured programming is to get an understanding about the flow of control in the given program text. In structure programming various control structures such as switch-case, if-then-else, while, etc. allows a programmer to decode the flow of the program easily.
Ans .
D
- Explanation :
Why a, b and c are incorrect? a) call swap (x, y) will not cause any effect on x and y as parameters are passed by value. b) call swap (&x, &y) will no work as function swap() expects values not addresses (or pointers). c) swap (x, y) cannot be used but reason given is not correct.
Ans .
D
- Explanation :
If we are to use space efficiently then size of the any stack can be more than MAXSIZE/2. Both stacks will grow from both ends and if any of the stack top reaches near to the other top then stacks are full. So the condition will be top1 = top2 -1 (given that top1 < top2)
Ans .
B
- Explanation :
10 / \ 1 15 \ / \ 3 12 16 \ 5
Ans .
B
- Explanation :
There are three types of parentheses [ ] { } (). Below is an arbit c code segment which has parentheses of all three types. void func(int c, int a[]) { return ((c +2) + arr[(c-2)]) ; }
Ans .
D
- Explanation :
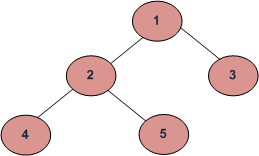 Level order traversal of the above tree is 1 2 3 4 5
.
Level order traversal of the above tree is 1 2 3 4 5
.
Ans .
C
- Explanation :
The hash value for 9679, 1989, 4199 is 9 and hash value for 1471, 6171 is 1.
Ans .
B
- Explanation :
An operator precedence parser is a bottom-up parser that interprets an operator-precedence grammar. For example, most calculators use operator precedence parsers to convert from the human-readable infix notation with order of operations format into an internally optimized computer-readable format like Reverse Polish notation (RPN). An operator precedence grammar is a kind of context-free grammar that can be parsed with an operator-precedence parser. It has the property that no production has either an empty (ε) right-hand side or two adjacent nonterminals in its right-hand side. These properties allow the terminals of the grammar to be described by a precedence relation, and the a parser that exploits that relation is considerably simpler than more general-purpose parsers such as LALR parsers.
Ans .
C
- Explanation :
Static linking is done at link-time, dynamic linking or shared libraries are brought in only at runtime. (A) Edit-time : Function references can never be given/determined at edit-time or code-writing time. Function references are different from function names. Function names are used at edit-time and function references are determined at linker-time for static libraries or at runtime for dynamic libraries. (B) Compile-time : Compile time binding is done for functions present in the same file or module. (C) Link-time : Link time binding is done in the linker stage, where functions present in separate files or modules are referenced in the executable. (D) Load-time : Function referencing is not done at load-time
Ans .
B
- Explanation :
E -> E1 - E2 Given that E1 and E2 don't share any sub expression, most optimized usage of single user register for evaluation of this production rule would come only when E2 is evaluated before E1. This is because when we will have E1 evaluated in the register, E2 would have been already computed and stored at some memory location. Hence we could just use subtraction operation to take the user register as first operand, i.e. E1 and E2 value from its memory location referenced using some index register or some other form according to the instruction. Hence correct answer should be (B) E2 should be evaluated first.
Ans .
A
- Explanation :
User thread are implemented by users. kernel threads are implemented by OS. OS doesn’t recognized user level threads. Kernel threads are recognized by OS. Implementation of User threads is easy. Implementation of Kernel thread is complicated. Context switch time is less. Context switch time is more. Context switch requires no hardware support. Hardware support is needed. If one user level thread perform blocking operation then entire process will be blocked. If one kernel thread perform blocking operation then another thread can continue execution. Example : Java thread, POSIX threads. Example : Window Solaris.
Ans .
D
- Explanation :
Since Operating System can execute a single sequential user process at a time, the disk is accessed in FCFS manner always. The OS never has a choice to pick an IO from multiple IOs as there is always one IO at a time So, the solution is (D).
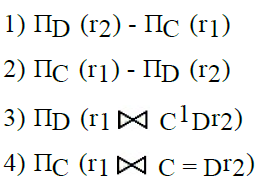
Ans .
B
- Explanation :
Since C is a foreign key in R1 and there is no violation of the above referential integrity constraint, the set of values in C must be a subset of values in R2.
Ans .
A
- Explanation :
The result of the natural join is the set of all combinations of tuples in R and S that are equal on their common attribute names. What is the maximum possible number of tuples? The result of natural join becomes equal to the Cartesian product when there are no common attributes. The given tables have a common attribute, so the result of natural join cannot have more than the number of tuples in larger table.
Ans .
A
- Explanation :
Data link layer is the second layer of the OSI Model. This layer is responsible for data transfer between nodes on the network and providing a point to point local delivery framework. So, P matches with 1. Network layer is the third layer of the OSI Model. This layer is responsible for forwarding of data packets and routing through intermediate routers. So, Q matches with 4. Transport layer is the fourth layer of the OSI Model. This layer is responsible for delivering data from process to process. So, R matches with 3. Thus, A is the correct option. Please comment below if you find anything wrong in the above post.
Ans .
B
- Explanation :
***
Ans .
D
- Explanation :
x’y’+xy+xy’ =(x’y’+y(x+x’)) =x'y’+y =x'+y Ans (d)
Ans .
D
- Explanation :
If both R reset and S set inputs are inactivated. It means made ‘0’, both Q and Q’ tend to be ‘1’. [NAND gate characteristic is that only when both inputs are 1,the output is 0.] The logic of the circuit (Q’ is complement of Q) not satisfied, and the final state at an instant after inputs R and S changed to ‘0’, is only a matter of chance. Logic state is said to be indeterminate state or racing state. Each state, Q =‘1’and Q =‘0’, and Q =‘0’, Q=‘1’ trying to race through so “RACE CONDITION” occurs and output become unstable. So ans is (D) part.
Ans .
D
- Explanation :
We can solve it by converting both to decimals. 3 + 7*8 = 4 + 11*5
Ans .
C
- Explanation :
Program relocation at run time transfer complete block to some memory locations. This requires as base address and block should be relatively addressed through this base address .This require both base address and relative address. So( C) is correct option. Absolute addressing mode and indirect addressing modes is used for one instruction at one time, not for whole block So both are not suitable for program relocation at run time.
Ans .
A
- Explanation :
There are two important tasks in virtual memory management: a page-replacement strategy and a frame-allocation strategy. Frame allocation strategy says gives the idea of minimum number of frames which should be allocated. The absolute minimum number of frames that a process must be allocated is dependent on system architecture, and corresponds to the number of pages that could be touched by a single (machine) instruction. So, it is instruction set architecture i.e. option (A) is correct answer.
Ans .
B
- Explanation :
Background required - Physical Layer in OSI Stack In serial Communications, information is transferred in or out one bit at a time. The baud rate specifies how fast data is sent over a serial line. It’s usually expressed in units of bits-per-second (bps). Each block (usually a byte) of data transmitted is actually sent in a packet or frame of bits. Frames are created by appending synchronization and parity bits to our data.

Note : taller(x,y) is true if x is taller than y.
Ans .
D
- Explanation :
Now many people get confused when to use ∧ and when to use →. This question tests exactly that. We use ∧ when we want to say that the both predicates in this statement are always true, no matter what the value of x is. We use → when we want to say that although there is no need for left predicate to be true always, but whenever it becomes true, right predicate must also be true. D means there exist some boys x which taller than all girls y.
Ans .
B
- Explanation :
Reflexive closure of a relation R on set S is the smallest reflexive relation which contains R. If S = {(0, 1), (1, 2)} , we make it reflexive by taking its union with set {(0, 0), (1, 1), (2, 2)}. Thus, reflexive closure of S = {(0, 0), (0, 1), (1, 1), (1, 2), (2, 2)}. Now transitive closure is defined as smallest transitive relation which contains S. We check where does it violate property of transitivity then add appropriate pair. We have (0, 1) and (1, 2) but not (0, 2). So, S = {(0, 0), (0, 1), (0, 2), (1, 1), (1, 2), (2, 2)} now. Thus, option (B) matches the final set S.
Ans .
A
- Explanation :
There are total 16 possibilities, out of which following have 2 heads and 2 tails HHTT, HTHT, TTHH, THTH, HTTH, THHT So the probability of 2 heads is 6/16 which is 3/8
Ans .
C
- Explanation :
We are considering a symmetric matrix (given in question). So, we need to look at half of elements ie. either upper or lower traingle i.e. A[i][j] = A[j][i] Hence, No. of elements = ( n^2 + n ) / 2 Since, we have only two elements : 0 & 1 No. of choices = 2 Therefore, No. of possibilities = 2 ^ (No. of elements) = 2 ^ ( ( n^2 + n ) / 2 ) = power ( 2 , ( n^2 + n ) / 2 )
Ans .
B
- Explanation :

Ans .
A
- Explanation :
(113. + -111.) + 7.51 = 2 + 7.51 = 9.51 113. + (-111. + 7.51) = 113. + (-111. + 7.51) = 113. - 103. = 10 [103.49 is rounded to 103.0] option A is correct.
Ans .
C
- Explanation :
The number of comparisons that a comparison sort algorithm requires increases in proportion to Nlog(N), where N is the number of elements to sort. This bound is asymptotically tight: Given a list of distinct numbers (we can assume this because this is a worst-case analysis), there are N factorial permutations exactly one of which is the list in sorted order. The sort algorithm must gain enough information from the comparisons to identify the correct permutations. If the algorithm always completes after at most f(N) steps, it cannot distinguish more than 2^f(N) cases because the keys are distinct and each comparison has only two possible outcomes. Therefore, 2^f(N) >= N! or equivalently f(N) >= log(N!). Since log(N!) is Omega(NlogN), the answer is NlogN.
Ans .
C
- Explanation :
The Boolean satisfiability problem (SAT) is a decision problem, whose instance is a Boolean expression written using only AND, OR, NOT, variables, and parentheses. The problem is: given the expression, is there some assignment of TRUE and FALSE values to the variables that will make the entire expression true? A formula of propositional logic is said to be satisfiable if logical values can be assigned to its variables in a way that makes the formula true. 3-SAT and 2-SAT are special cases of k-satisfiability (k-SAT) or simply satisfiability (SAT), when each clause contains exactly k = 3 and k = 2 literals respectively. 2-SAT is P while 3-SAT is NP Complete.
Ans .
C
- Explanation :
Since i is static, first line of f() is executed only once.
Ans .
A
- Explanation :
The loop one by adds digits to rev starting from the last digit of n. It also removes digits from n starting from left.
Ans .
D
- Explanation :
Let us consider below line inside the for loop p[i] = s[length — i]; For i = 0, p[i] will be s[6 — 0] and s[6] is ‘\0’ So p[0] becomes ‘\0’. It doesn’t matter what comes in p[1], p[2]….. as P[0] will not change for i >0. Nothing is printed if we print a string with first character ‘\0’
Ans .
A
- Explanation :
Getid() and GetName() can be there in the base class as these functions have the same implementation for all subclasses. As the question says that every employee must have salary and salary is determined by their category, getSalary() must be there as an abstract function in base class. And all subclasses should implement salary according to their category. Only option (A) is correct.
Ans .
B
- Explanation :
Here, we consider each and every option to check whether it is true or false. 1) Preorder and postorder
Ans .
A
- Explanation :
Answer is not “(b) front node”, as we can not get rear from front in O(1), but if p is rear we can implement both enQueue and deQueue in O(1) because from rear we can get front in O(1). Below are sample functions. Note that these functions are just sample are not working. Code to handle base cases is missing. Therefore, option A is correct.
Ans .
A
- Explanation :
A max heap is a complete binary tree in which the value of each non-leaf node is greater than or equal to the values of its children. For the given case, first insert all the values in a complete binary tree. Then, we apply shifting. What we do is we start with the bottom most non-leaf node. If it is smaller than any (or both) of the child nodes, we swap it with the largest child. Doing the same way, we continue to move upwards the tree until all the non-leaf nodes satisfy the properties of the max heap. So, the first time we make a complete binary tree, we have Therefore, option A is correct.
Ans .
A
- Explanation :
^ is right assosciative.
Ans .
D
- Explanation :
This is a trick question. Note that the questions asks about time complexity, not time taken by the program. for time complexity, it doesn't matter how we store array elements, we always need to access same number of elements of M1 and M2 to multiply the matrices. It is always constant or O(1) time to do element access in arrays, the constants may differ for different schemes, but not the time complexity.
Ans .
D
- Explanation :
Cardinality and membership are definitely not the slowest one. For cardinality, just count the number of nodes in a list. For membership, just traverse the list and look for a match For getting intersection of L1 and L2, search for each element of L1 in L2 and print the elements we find in L2. There can be many ways for getting union of L1 and L2. One of them is as follows a) Print all the nodes of L1 and print only those which are not present in L2. b) Print nodes of L2.
Ans .
C
- Explanation :
The given program is iterative implementation of Euclid's Algorithm for GCD
Ans .
C
- Explanation :
The given code is implementation of Babylonian method for square root
Ans .
D
- Explanation :
DoSomething() returns max(height of left child + 1, height of right child + 1). So given that pointer to root of tree is passed to DoSomething(), it will return height of the tree. Note that this implementation follows the convention where height of a single node is 0. Lets take a sample tree and try to run the code. .
Ans .
B
- Explanation :
Ans .
C
- Explanation :
We can calculate the value by constructing the parse tree for the expression 2 # 3 & 5 # 6 &4. Alternatively, we can calculate by considering following precedence and associativity rules. Precedence in a grammar is enforced by making sure that a production rule with higher precedence operator will never produce an expression with operator with lower precedence. In the given grammar ‘&’ has higher precedence than ‘#’. Left associativity for operator * in a grammar is enforced by making sure that for a production rule like S -> S1 * S2 in grammar, S2 should never produce an expression with *. On the other hand, to ensure right associativity, S1 should never produce an expression with *. In the given grammar, both ‘#’ and & are left-associative. So expression 2 # 3 & 5 # 6 &4 will become ((2 # (3 & 5)) # (6 & 4)) Let us apply translation rules, we get ((2 * (3 + 5)) * (6 + 4)) = 160.
Ans .
A
- Explanation :
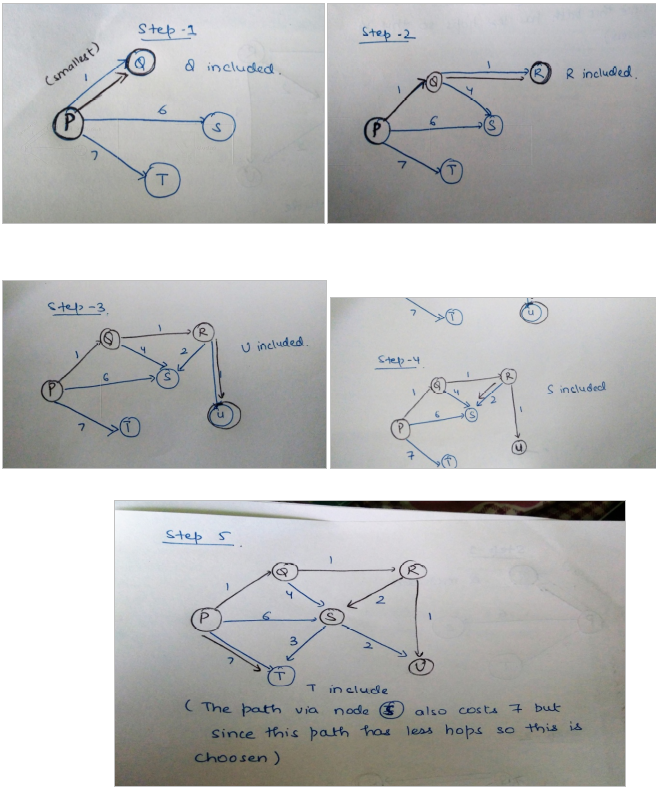
The following is Gantt Chart of execution P1 P2 P4 P3 P1 1 4 5 8 12 Turn Around Time = Completion Time - Arrival Time Avg Turn Around Time = (12 + 3 + 6+ 1)/4 = 5.50
Ans .
D
- Explanation :
Please note that page fault rate is given one page fault per 10,000 instructions. Since there are two memory accesses per instruction, so we need double address translation time for average instruction execution time. Also, there are 2 page table accessed if TLB miss occurred. TLB access assumed as 0. Therefore, Average Instruction execution time = Average CPU execution time + Average time for getting data(instruction operands from memory for each instruction) = Average CPU execution time + Average address translation time for each instruction + Average memory fetch time for each instruction + Average page fault time for each instruction = 100 + 2×(0.9×(0)+0.1×(2×150)) + 2×150 + 1 /10000 × 8 × 106 = 100 + 60 + 300 + 800 = 1260 ns So, none option is correct.
Ans .
D
- Explanation :
Option A: In line L1 ( p(Sy) ) i.e. process p1 wants lock on Sy that is held by process p2 and line L3 (p(Sx)) p2 wants lock on Sx which held by p1. So here circular and wait condition exist means deadlock. Option B : In line L1 ( p(Sx) ) i.e. process p1 wants lock on Sx that is held by process p2 and line L3 (p(Sy)) p2 wants lock on Sx which held by p1. So here circular and wait condition exist means deadlock. Option C: In line L1 ( p(Sx) ) i.e. process p1 wants lock on Sx and line L3 (p(Sy)) p2 wants lock on Sx . But Sx and Sy can’t be released by its processes p1 and p2.
Ans .
C
- Explanation :
Size of Disk Block = 1Kbyte Disk Blocks address = 32bits, but 48 bit integers are used for address Therefore address size = 6 bytes No of addresses per block = 1024/6 = 170.66 Therefore 170 ≈ 2^8 addresses per block can be stored Maximum File Size = 10 Direct + 1 Single Indirect + 1 Double Indirect + 1 Triple Indirect = 10 + 28 + 28*28 + 28*28*28 ≈ 224 Blocks Since each block is of size 210 Maximum files size = 224 * 210 = 234
Ans .
B
- Explanation :
For easy understanding let's say attributes (name, courseNo, rollNo, grade) be (A,B,C,D) Then given FDs are as follows: AB->D, CB->D, A->C, C->A Here there are two Candidate keys, AB and CB. Now AB->D and CB->D satisfy BCNF as LHS is superkey in both. But, A->C and C->A, doesn't satisfy BCNF. Hence we check for 3NF for these 2 FDs. As C and A on RHS of both the FDs are prime attributes, they satisfy 3NF. Hence for the whole relation the highest normal form is 3NF.
Ans .
D
- Explanation :
he above relational algebra expression has two sub expressions. The first one takes as input the Student relation (Student) and filters out all the tuples where sex=female(r sex=female (Student)) and then projects their names (P name r sex=female (Student)). So we get a new relation with names of all the female students. The second one takes as input the Student relation and performs a rename operation on one with attributes name, sex and marks renamed as n, x, m respectively (r n, x, m(Student)) and then followed by a self-Cartesian product on the Student relation. The condition (sex = female ^ m = male ^ marks ≤ m) filters tuples with all female students from the first relation, male students from the second relation and performs a Cartesian product where marks of the female student is either less than or equal to a male student and then projects their names. So we get a new relation with names of all female students whose marks are lesser than at least one of the male student.
Ans .
C
- Explanation :
Key size = 14 bytes (given) Child pointer = 6 bytes (given) We assume the order of B+ tree to be ‘n’. Block size = (n - 1) * key size + n * child pointer 512 >= (n - 1) * 14 + n * 6 512 >= 14 * n – 14 + 6 * n n = (512 + 14) / 20 n = 526 / 20 n = 26.3 n = 26 Thus, option (C) is correct.
Ans .
D
- Explanation :
In this SQL query, we have select deptName --------------- Select the department name from Employee ---------------- From the database of employees where sex = 'M' --------------- Where sex is male (M) group by deptName ------------- Group by the name of the department having avg (salary) > (select avg (salary) from Employee) ----- Having the average salary greater than the average salary of all employees in the organization.
Ans .
B
- Explanation :
This is basically the question related to unfairness of exponential back-off algorithm called 'capture effect'. You can find more info about it here: http://intronetworks.cs.luc.edu/current/html/ethernet.html#capture-effect The solution to the above problem goes like this: At every attempt to transit a frame, both A and B chooses value of 'k' randomly. Based on the value of 'k', back-off time is calculated as a multiple of 'k'. The station or node having the smaller back-off time gets to send the frames eariler. 1st attempt: Value of 'k' would be k=0 or k=1 (0 <= k <= 2^n-1; where n=nth attempt). Since A won the first race, A must have chosen k=0 and B must have chosen k=1 (A wins here with probability 0.25). As A won, A will again choose k=0 or k=1 for its 2nd frame, but B will choose k=0,1,2 or 3 as B failed to send its first frame in the first attempt. 2nd attempt: Let kA= value of k chosen by A and kB = value of k chosen by B. We will use notation (kA,kB) to show the possible values. Now the sample space for the 2nd attempt is (kA,kB) = (0,0),(0,1),(0,2),(0,3),(1,0),(1,1),(1,2) or (1,3) i.e. 8 possible outcomes. For A to win, kA should be less than kB (kA < kB). Thus, our event space is (kA, kB) = (0,1),(0,2),(0,3),(1,2),(1,3) i.e. 5 possible outcomes. Thus the probability that A wins the 2nd back-off race = 5/8 = 0.625