CNN Example
You now know pretty much all the building blocks of building a full convolutional neural network. Let's look at an example. Let's say you're inputting an image which is 32 x 32 x 3, so it's an RGB image and maybe you're trying to do handwritten digit recognition.
So you have a number like 7 in a 32 x 32 RGB initiate trying to recognize which one of the 10 digits from zero to nine is this.
Let's throw the neural network to do this. And what I'm going to use in this slide is inspired, it's actually quite similar to one of the classic neural networks called LeNet-5, which is created by Yann LeCun many years ago.
What I'll show here isn't exactly LeNet-5 but it's inspired by it, but many parameter choices were inspired by it.
So with a 32 x 32 x 3 input let's say that the first layer uses a 5 x 5 filter and a stride of 1, and no padding.
So the output of this layer, if you use 6 filters would be 28 x 28 x 6, and we're going to call this layer conv 1. So you apply 6 filters, add a bias, apply the non-linearity, maybe a ReLU non-linearity, and that's the conv 1 output.
Next, let's apply a pooling layer, so I am going to apply max pooling here and let's use a f=2, s=2. When I don't write a padding use a no padding with a 0.
Next let's apply a pooling layer, max pooling with a 2 x 2 filter and the stride equals 2. So this is should reduce the height and width of the representation by a factor of 2.
So 28 x 28 now becomes 14 x 14, and the number of channels remains the same so 14 x 14 x 6, and we're going to call this the Pool 1 output. So, it turns out that in the literature of a ConvNet there are two conventions which are inside the inconsistent about what you call a layer.
One convention is that CONV and POOL together as one layer. So this will be layer one of the neural network, and now the convention will be to call CONV layer as a layer and the pool layer as a layer.
When people report the number of layers in a neural network usually people just record the number of layers that have weight, that have parameters.
And because the pooling layer has no weights, has no parameters, only a few hyper parameters, I'm going to use a convention that Conv 1 and Pool 1 shared together.
I'm going to treat that as Layer 1, although sometimes you see people maybe read articles online and read research papers, you hear about the conv layer and the pooling layer as if they are two separate layers.
But this is maybe two slightly inconsistent notation terminologies, but when I count layers, I'm just going to count layers that have weights.
So both of this together as Layer 1.
And the name Conv1 and Pool1 use here the 1 at the end also refers the fact that I view both of this is part of Layer 1 of the neural network. And Pool 1 is grouped into Layer 1 because it doesn't have its own weights.
Next, given a 14 x 14 by 6 volume, let's apply another convolutional layer to it, let's use a filter size that's 5 x 5, and let's use a stride of 1, and let's use 10 filters this time.
So now you end up with, A 10 x 10 x 10 volume, so I'll call this Comv 2, and then in this network let's do max pooling with f=2, s=2 again. So you could probably guess the output of this, f=2, s=2, this should reduce the height and width by a factor of 2, so you're left with 5 x 5 x 10.
And so I'm going to call this Pool 2, and in our convention this is Layer 2 of the neural network.
Now 5 x 5 x 16 is equal to 400. So let's now flatten our Pool 2 into a 400 x 1 dimensional vector. So think of this as flattening this up into these set of neurons.
And what we're going to do is then take these 400 units and let's build the next layer, As having 120 units. So this is actually our first fully connected layer. I'm going to call this FC3 because we have 400 units densely connected to 120 units.
So this fully connected unit, this fully connected layer is just like the single neural network layer that you saw previously. This is just a standard neural network where you have a weight matrix that's called \( W^{[3]} \) of dimension 120 x 400.
And this is fully connected because each of the 400 units here is connected to each of the 120 units here, and you also have the bias parameter, yes that's going to be just a 120 dimensional, this is 120 outputs.
And then lastly let's take 120 units and add another layer, this time smaller but let's say we had 84 units here, I'm going to call this fully connected Layer 4. And finally we can havea softmax unit for multi-class classification or a sigmoid for binary classification.
So this is a vis-a-vis typical example of what a convolutional neural network might look like.
And I know this seems like there a lot of hyper parameters. We'll give you some more specific suggestions later for how to choose these types of hyper parameters.
Maybe one common guideline is to actually not try to invent your own settings of hyper parameters, but to look in the literature to see what hyper parameters you work for others.
And to just choose an architecture that has worked well for someone else, and there's a chance that will work for your application as well.
But for now I'll just point out that as you go deeper in the neural network, usually height and width will decrease. Pointed this out earlier, but it goes from 32 x 32, to 20 x 20, to 14 x 14, to 10 x 10, to 5 x 5. So as you go deeper usually the height and width will decrease, whereas the number of channels will increase.
It's gone from 3 to 6 to 16, and then your fully connected layer is at the end.
And another pretty common pattern you see in neural networks is to have conv layers, maybe one or more conv layers followed by a pooling layer, and then again one or more conv layers followed by pooling layer.
And then at the end you have a few fully connected layers and then followed by maybe a softmax.
And this is another pretty common pattern you see in neural networks.
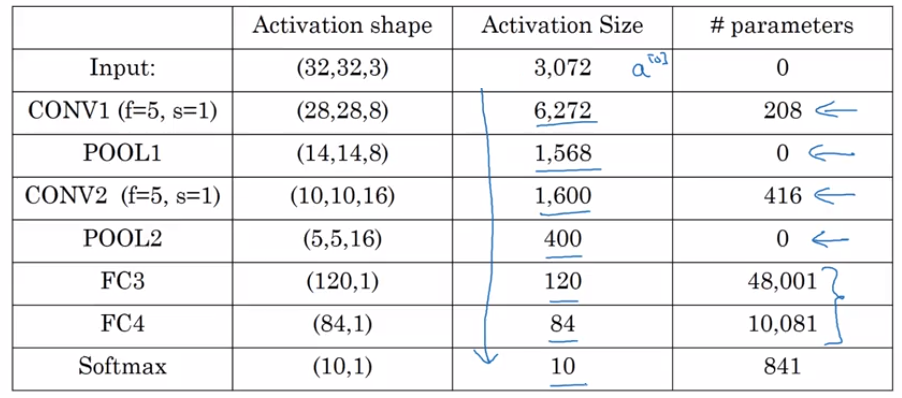
So let's just go through for this neural network some more details of what are the activation shape, the activation size, and the number of parameters in this network.
So the input was 32 x 32 x 3, and if you multiply out those numbers you should get 3,072. So the activation, \( a^{[0]} \) has dimension 3072.
And there are no parameters I guess at the input layer. And as you look at the different layers, feel free to work out the details yourself. These are the activation shape and the activation sizes of these different layers.
First, notice that the max pooling layers don't have any parameters. Second, notice that the conv layers tend to have relatively few parameters, as we discussed in early sections.
And in fact, a lot of the parameters tend to be in the fully collected layers of the neural network. And then you notice also that the activation size tends to maybe go down gradually as you go deeper in the neural network.
If it drops too quickly, that's usually not great for performance as well.
So it starts first there with 6,000 and 1,600, and then slowly falls into 84 until finally you have your Softmax output.
You find that a lot of CNN will have patterns similar to these.
So you've now seen the basic building blocks of neural networks, your convolutional neural networks, the conv layer, the pooling layer, and the fully connected layer.
A lot of computer division research has gone into figuring out how to put together these basic building blocks to build effective neural networks.
And putting these things together actually requires quite a bit of insight. I think that one of the best ways for you to gain intuition is about how to put these things together is a see a number of concrete examples of how others have done it.
So what I want to do next week is show you a few concrete examples even beyond this first one that you just saw on how people have successfully put these things together to build very effective neural networks.
And through those examples or case studies next sections l hope you hold your own intuitions about how these things are built.
And as we are given concrete examples that architectures that maybe you can just use here exactly as developed by someone else or your own application.
So we'll do that further in the course, in next section lets see about why you might want to use convolutions.
Some benefits and advantages of using convolutions as well as how to put them all together.
How to take a neural network like the one you just saw and actually train it on a training set to perform image recognition for some of the tasks. So with that let's go on to the next section.