Classic Networks - LeNet-5
In this section, you'll learn about some of the classic neural network architecture starting with LeNet-5, and then AlexNet, and then VGGNet.
Here is the LeNet-5 architecture.
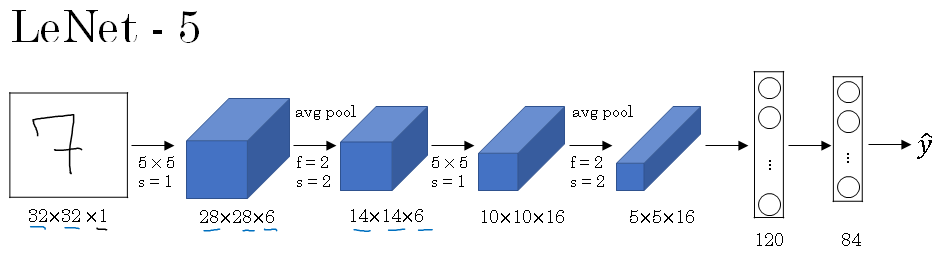
You start off with an image which say, 32 by 32 by 1. And the goal of LeNet-5 was to recognize handwritten digits, so maybe an image of a digits like that. And LeNet-5 was trained on grayscale images, which is why it's 32 by 32 by 1.
In the first step, you use a set of six, 5 by 5 filters with a stride of one because you use six filters you end up with a 20 by 20 by 6 over there.
And with a stride of one and no padding, the image dimensions reduces from 32 by 32 down to 28 by 28. Then the LeNet neural network applies pooling. And back then when this paper was written, people use average pooling much more. If you're building a modern variant, you probably use max pooling instead.
But in this example, you average pool and with a filter width two and a stride of two, you wind up reducing the dimensions, the height and width by a factor of two, so we now end up with a 14 by 14 by 6 volume.
Next, you apply another convolutional layer. This time you use a set of 16 filters, the 5 by 5, so you end up with 16 channels to the next volume. And back when this paper was written in 1998, people didn't really use padding or you always using valid convolutions, which is why every time you apply convolutional layer, they heightened with strengths.
So that's why, here, you go from 14 to 14 down to 10 by 10. Then another pooling layer, so that reduces the height and width by a factor of two, then you end up with 5 by 5 over here. And if you multiply all these numbers 5 by 5 by 16, this multiplies up to 400.
That's 25 times 16 is 400. And the next layer is then a fully connected layer that fully connects each of these 400 nodes with every one of 120 neurons, so there's a fully connected layer. And sometimes, that would draw out exclusively a layer with 400 nodes.
There's a fully connected layer and then another a fully connected layer. And then the final step is it uses these essentially 84 features and uses it with one final output. I guess you could draw one more node here to make a prediction for sigmoid.
And sigmoid took on 10 possible values corresponding to recognising each of the digits from 0 to 9. A modern version of this neural network, we'll use a softmax layer with a 10 way classification output. Although back then, LeNet-5 actually use a different classifier at the output layer, one that's useless today.
So this neural network was small by modern standards, had about 60,000 parameters. And today, you often see neural networks with anywhere from 10 million to 100 million parameters, and it's not unusual to see networks that are literally about a thousand times bigger than this network. But one thing you do see is that as you go deeper in a network, so as you go from left to right, the height and width tend to go down.
So you went from 32 by 32, to 28 to 14, to 10 to 5, whereas the number of channels does increase.
It goes from 1 to 6 to 16 as you go deeper into the layers of the network. One other pattern you see in this neural network that's still often repeated today is that you might have some one or more convolution layers followed by pooling layer, and then one or sometimes more than one convolution layer followed by a pooling layer, and then some fully connected layers and then the outputs.
So this type of arrangement of layers is quite common.
Now finally, this is maybe only for those of you that want to try reading the paper. There are a couple other things that were different.
The rest of this section, I'm going to make a few more advanced comments, only for those of you that want to try to read this classic paper.
This you can safely skip and that is okay if you don't follow fully.
So it turns out that if you read the original paper, back then, people used sigmoid and tanh nonlinearities, and people weren't using ReLU nonlinearities back then. So if you look at the paper, you see sigmoid and tanh referred.
And there are also some funny ways about how this network was wired that is funny by modern standards.
So for example, you've seen how if you have a \( n_h x n_w x n_c \) network with nc channels then you use \( f x f x n_c \) dimensional filter, where everything looks at every one of these channels. But back then, computers were much slower.
And so to save on computation as well as some parameters, the original LeNet-5 had some crazy complicated way where different filters would look at different channels of the input block. And so the paper talks about those details, but the more modern implementation wouldn't have that type of complexity these days.
And then one last thing that was done back then I guess but isn't really done right now is that the original LeNet-5 had a non-linearity after pooling, and I think it actually uses sigmoid non-linearity after the pooling layer.
So if you do read this paper, and this is one of the harder ones to read than the ones we'll go over in the next few section, the next one might be an easy one to start with.
Most of the ideas on this section we just tried in sections two and three of the paper, and later sections of the paper talked about some other ideas.
It talked about something called the graph transformer network, which isn't widely used today. So if you do try to read this paper, we recommend focusing really on section two which talks about this architecture, and maybe take a quick look at section three which has a bunch of experiments and results, which is pretty interesting.
Classic Networks - AlexNet
The second example of a neural network I want to show you is AlexNet, named after Alex Krizhevsky, who was the first author of the paper describing this work. The other author's were Ilya Sutskever and Geoffrey Hinton.
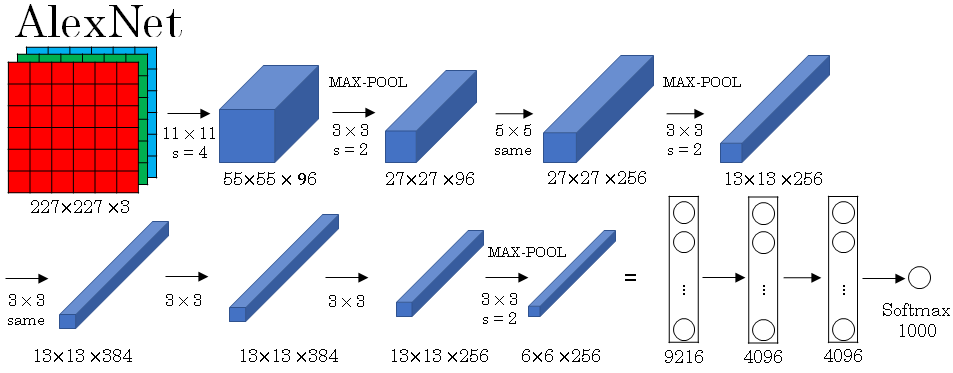
So, AlexNet input starts with 227 by 227 by 3 images. And if you read the paper, the paper refers to 224 by 224 by 3 images. But if you look at the numbers, I think that the numbers make sense only of actually 227 by 227.
And then the first layer applies a set of 96 (11 x 11) filters with a stride of four. And because it uses a large stride of four, the dimensions shrinks to 55 x 55.
So roughly, going down by a factor of 4 because of a large stride. And then it applies max pooling with a 3 x 3 filter. So f = 3 and a stride of two. So this reduces the volume to 27 x 27 x 96, and then it performs a 5 x 5 same convolution, same padding, so you end up with 27 x 27 x 276.
Max pooling again, this reduces the height and width to 13.
And then another same convolution, so same padding. So it's 13 x 13 x 384 filters. And then 3 x 3, same convolution again, gives you that. Then 3 by 3, same convolution, gives you that.
Then max pool, brings it down to 6 by 6 by 256. If you multiply all these numbers, 6 times 6 times 256, that's 9216. So we're going to unroll this into 9216 nodes. And then it has a few fully connected layers. And then finally, it uses a softmax to output which one of 1000 classes the object could be.
So this neural network actually had a lot of similarities to LeNet, but it was much bigger. So whereas the LeNet-5 from previous slide had about 60,000 parameters, this AlexNet had about 60 million parameters. And the fact that they could take pretty similar basic building blocks that have a lot more hidden units and training on a lot more data, they trained on the dataset that allowed it to have a just remarkable performance.
Another aspect of this architecture that made it much better than LeNet was using the ReLU activation function. And then again, just if you read the paper some more advanced details that you don't really need to worry about is that, when this paper was written, GPU was still a little bit slower, so it had a complicated way of training on two GPUs.
And the basic idea was that, a lot of these layers was actually split across two different GPUs and there was a thoughtful way for when the two GPUs would communicate with each other.
And the paper also, the original AlexNet architecture also had another set of a layer called a Local Response Normalization. And this type of layer isn't really used much, which is why I didn't talk about it.
But subsequently, many researchers have found that this doesn't help
So if you are interested in the history of deep learning, I think even before AlexNet, deep learning was starting to gain traction in speech recognition and a few other areas, but it was really just paper that convinced a lot of the computer vision community to take a serious look at deep learning to convince them that deep learning really works in computer vision.
And then it grew on to have a huge impact not just in computer vision but beyond computer vision as well. And if you want to try reading some of these papers yourself and you really don't have to for this course, but if you want to try reading some of these papers, this one is one of the easier ones to read so this might be a good one to take a look at.
So whereas AlexNet had a relatively complicated architecture, there's just a lot of hyperparameters, right? Where you have all these numbers that Alex Krizhevsky and his co-authors had to come up with. Let me show you a third and final example on this section called the VGG or VGG-16 network .
And a remarkable thing about the VGG-16 net is that they said, instead of having so many hyperparameters, let's use a much simpler network where you focus on just having conv-layers that are just three-by-three filters with a stride of one and always use same padding. And make all your max pooling layers two-by-two with a stride of two. And so, one very nice thing about the VGG network was it really simplified this neural network architectures. So, let's go through the architecture.
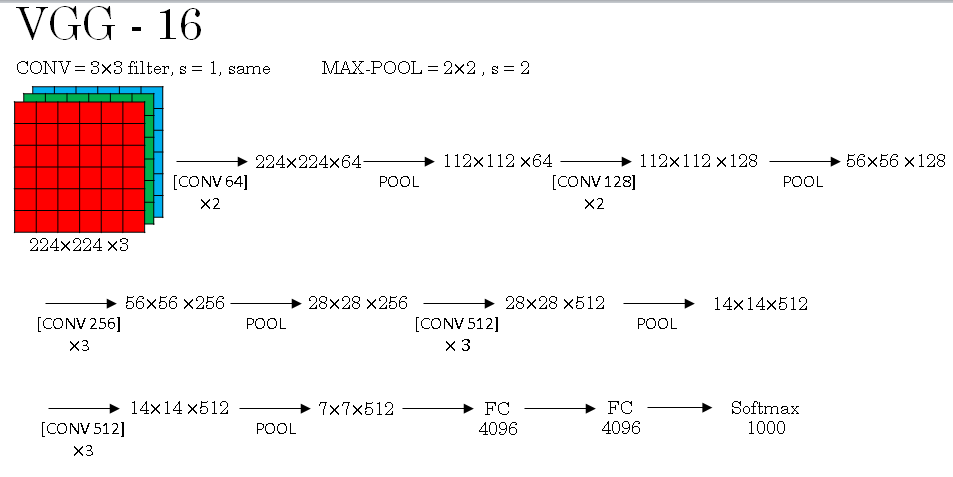
Classic Networks - VGGNet-16
So, you solve up with an image for them and then the first two layers are convolutions, which are therefore these three-by-three filters. And in the first two layers use 64 filters.
You end up with a 224 by 224 because using same convolutions and then with 64 channels.
So because VGG-16 is a relatively deep network, am going to not draw all the volumes here.
First we take the original image which has dimensions as 224 x 224 x 3 and passes through filters that are of dimensions 3 x 3 (stride is 1 and padding is same). So the conv64 x two symbol given above represents that you're doing two conv-layers with 64 filters. As 64 filters are used we get the final image dimensions as 224 x 224 x 64. As same padding is used we do not see change in dimension of input.
And as I mentioned earlier, the filters are always three-by-three with a stride of one and they are always same convolutions. So rather than drawing all these volumes, am just going to use text to represent this network.
Next, we use pooling layer, so the pooling layer will reduce the image dimensions. I think it goes from 224 by 224 down to 112 by 112 by 64.
And then it has a couple more conv-layers. So this means it has 128 filters and because these are the same convolutions, let's see what is the new dimension. It will be 112 by 112 by 128 and then pooling layer so you can figure out what's the new dimension of that. And now, three conv-layers with 256 filters to the pooling layer and then a few more conv-layers, pooling layer, more conv-layers, pooling layer.
And then it takes this final 7 by 7 by 512 in to fully connected layer, fully connected with four thousand ninety six units and then a softmax output one of a thousand classes. By the way, the 16 in the VGG-16 refers to the fact that this has 16 layers that have weights. And this is a pretty large network, this network has a total of about 138 million parameters.
And that's pretty large even by modern standards. But the simplicity of the VGG-16 architecture made it quite appealing. You can tell his architecture is really quite uniform. There is a few conv-layers followed by a pooling layer, which reduces the height and width, right? So the pooling layers reduce the height and width. You have a few of them here. But then also, if you look at the number of filters in the conv-layers, here you have 64 filters and then you double to 128 double to 256 doubles to 512.
And so I think the relative uniformity of this architecture made it quite attractive to researchers. The main downside was that it was a pretty large network in terms of the number of parameters you had to train.
And if you read the literature, you sometimes see people talk about the VGG-19, that is an even bigger version of this network. And you could see the details in the paper cited at the bottom by Karen Simonyan and Andrew Zisserman. But because VGG-16 does almost as well as VGG-19. A lot of people will use VGG-16.
But the thing I liked most about this was that, this made this pattern of how, as you go deeper and height and width goes down, it just goes down by a factor of two each time for the pooling layers whereas the number of channels increases.
And here roughly goes up by a factor of two every time you have a new set of conv-layers. So by making the rate at which it goes down and that go up very systematic, I thought this paper was very attractive from that perspective.
So that's it for the three classic architecture's. If you want, you should really now read some of these papers. I recommend starting with the AlexNet paper followed by the VGG net paper and then the LeNet paper.
But next, let's go beyond these classic networks and look at some even more advanced, even more powerful neural network architectures. Let's go onto the next section.