Practical advice for using ConvNets - Using Open-Source Implementation
You've now learned about several highly effective neural network and ConvNet architectures.
What I want to do in the next few sections is share with you some practical advice on how to use them, first starting with using open source implementations.
It turns out that a lot of these neural networks are difficult or finicky to replicate because a lot of details about tuning of the hyperparameters such as learning decay and other things that make some difference to the performance.
And so I've found that it's sometimes difficult even for, say, a PhD students, even at the top universities to replicate someone else's published work just from reading their paper.
Fortunately, a lot of deep learning researchers routinely open source their work on the Internet, such as on GitHub.
And as you do work yourself, I certainly encourage you to consider contributing back your code to the open source community. But if you see a research paper whose results you would like to build on top of, one thing you should consider doing, one thing I do quite often it's just look online for an open source implementation.
Because if you can get the author's implementation, you can usually get going much faster than if you would try to reimplement it from scratch. Although sometimes reimplementing from scratch could be a good exercise to do as well.
Practical advice for using ConvNets - Transfer Learning
If you're building a computer vision application rather than training the network weights from scratch, from random initialization, you often make much faster progress if you download weights that someone else has already trained on the network architecture and use that as pre-training and transfer that to a new task that you might be interested in.
The computer vision research community has been pretty good at posting lots of data sets on the Internet so if you hear of things like Image Net, or COCO, or Pascal types of data sets, these are the names of different data sets that people have post online and a lot of computer researchers have trained their algorithms on.
Sometimes these training takes several weeks and might take many GPUs and the fact that someone else has done this and gone through the painful high-performance search process, means that you can often download open source ways that took someone else many weeks or months to figure out and use that as a very good initialization for your own neural network.
Then use transfer learning to sort of transfer knowledge from some of these very large public data sets to your own problem.
Let's take a deeper look at how to do this.
Let's start with the example, let's say you're building a cat detector to recognize your own pet cat. According to the internet, Tiger is a common cat name and Misty is another common cat name. Let's say your cats are called Tiger and Misty and there's also neither. You have a classification problem with three classes.
Is this picture Tiger, or is it Misty, or is it neither.
And in all the case of both of you cats appearing in the picture. Now, you probably don't have a lot of pictures of Tiger or Misty so your training set will be small. What can you do? I recommend you go online and download some open source implementation of a neural network and download not just the code but also the weights.
There are a lot of networks you can download that have been trained on for example, the Image Net data sets which has a thousand different classes so the network might have a softmax unit that outputs one of a thousand possible classes. What you can do is then get rid of the softmax layer and create your own softmax unit that outputs Tiger or Misty or neither.
In terms of the network, I'd encourage you to think of all of these layers as frozen so you freeze the parameters in all of these layers of the network and you would then just train the parameters associated with your softmax layer.
Which is the softmax layer with three possible outputs, Tiger, Misty or neither.
By using someone else's trained weights, you might probably get pretty good performance on this even with a small data set.
Fortunately, a lot of learning frameworks support this mode of operation and in fact, depending on the framework it might have things like trainable parameter equals zero, you might set that for some of these early layers.
In others they just say, don't train those ways or sometimes you have a parameter like freeze equals one and these are different ways and different deep learning program frameworks that let you specify whether or not to train the ways associated with particular layer.
In this case, you will train only the softmax layers ways but freeze all of the earlier layers ways.
One rule of thumb is if you have a larger label data set so maybe you just have a ton of pictures of Tiger, Misty as well as I guess pictures neither of them, one thing you could do is then freeze fewer layers. Maybe you freeze just these layers and then train these later layers. Although if the output layer has different classes then you need to have your own output unit any way Tiger, Misty or neither.
There are a couple of ways to do this. You could take the last few layers ways and just use that as initialization and do gradient descent from there or you can also blow away these last few layers and just use your own new hidden units and in your own final softmax outputs.
Either of these matters could be worth trying. But maybe one pattern is if you have more data, the number of layers you've freeze could be smaller and then the number of layers you train on top could be greater.
And the idea is that if you pick a data set and maybe have enough data not just to train a single softmax unit but to train some other size neural network that comprises the last few layers of this final network that you end up using. Finally, if you have a lot of data, one thing you might do is take this open source network and ways and use the whole thing just as initialization and train the whole network.
Although again if this was a thousand of softmax and you have just three outputs, you need your own softmax output. The output of labels you care about.
But the more label data you have for your task or the more pictures you have of Tiger, Misty and neither, the more layers you could train and in the extreme case, you could use the weights you download just as initialization so they would replace random initialization and then could do gradient descent, training updating all the weights and all the layers of the network.
That's transfer learning for the training of ConvNets.
In practice, because the open data sets on the internet are so big and the weights you can download that someone else has spent weeks training has learned from so much data, you find that for a lot of computer vision applications, you just do much better if you download someone else's open source ways and use that as initialization for your problem.
In all the different disciplines, in all the different applications of deep learning, I think that computer vision is one where transfer learning is something that you should almost always do unless, you have an exceptionally large data set to train everything else from scratch yourself.


Practical advice for using ConvNets - Data Augmentation
Most computer vision task could use more data. And so data augmentation is one of the techniques that is often used to improve the performance of computer vision systems. I think that computer vision is a pretty complicated task.
You have to input this image, all these pixels and then figure out what is in this picture. And it seems like you need to learn the decently complicated function to do that. And in practice, there almost all computer visions task having more data will help. This is unlike some other domains where sometimes you can get enough data, they don't feel as much pressure to get even more data.
But I think today for the majority of computer vision problems, we feel like we just can't get enough data. And this is not true for all applications of machine learning, but it does feel like it's true for computer vision.
So, what that means is that when you're training in computer vision model, often data augmentation will help. And this is true whether you're using transfer learning or using someone else's pre-trained ways to start, or whether you're trying to train something yourself from scratch.
Let's take a look at the common data augmentation that is in computer vision.
Perhaps the simplest data augmentation method is mirroring on the vertical axis, where if you have this example in your training set, you flip it horizontally to get that image on the right. And for most computer vision task, if the left picture is a cat then mirroring it is though a cat. And if the mirroring operation preserves whatever you're trying to recognize in the picture, this would be a good data augmentation technique to use.
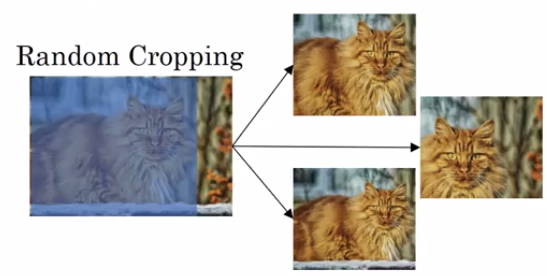
Another commonly used technique is random cropping. So given a dataset, let's pick a few random crops. So you might pick that, and take that crop or you might take that, to that crop, take this, take that crop and so this gives you different examples to feed in your training sample, sort of different random crops of your datasets. So random cropping isn't a perfect data augmentation. What if you randomly end up taking that crop which will look much like a cat but in practice and worthwhile so long as your random crops are reasonably large subsets of the actual image.
So, mirroring and random cropping are frequently used and in theory, you could also use things like rotation, shearing of the image, introduce various forms of local warping and so on. And there's really no harm with trying all of these things as well, although in practice they seem to be used a bit less, or perhaps because of their complexity.
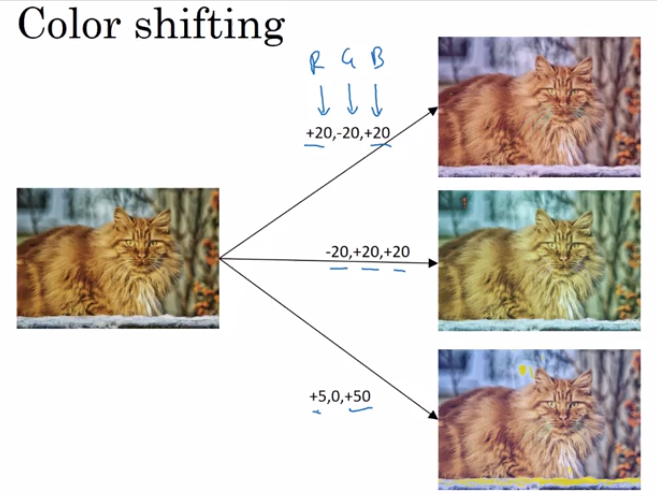
The second type of data augmentation that is commonly used is color shifting. So, given a picture like this, let's say you add to the R, G and B channels different distortions. In this example, we are adding to the red and blue channels and subtracting from the green channel. So, red and blue make purple. So, this makes the whole image a bit more purpley and that creates a distorted image for training set.
For illustration purposes, I'm making somewhat dramatic changes to the colors and practice, you draw R, G and B from some distribution that could be quite small as well. But what you do is take different values of R, G, and B and use them to distort the color channels. So, in the second example, we are making a less red, and more green and more blue, so that turns our image a bit more yellowish. And here, we are making it much more blue, just a tiny little bit longer. But in practice, the values R, G and B, are drawn from some probability distribution.
And the motivation for this is that if maybe the sunlight was a bit yellow or maybe the in-goal illumination was a bit more yellow, that could easily change the color of an image, but the identity of the cat or the identity of the content, the label y, just still stay the same.
And so introducing these color distortions or by doing color shifting, this makes your learning algorithm more robust to changes in the colors of your images.
So with that, I hope that you're going to use data augmentation, to get your computer vision applications to work better.