Anchor Boxes
One of the problems with object detection as you have seen it so far is that each of the grid cells can detect only one object. What if a grid cell wants to detect multiple objects?
Here is what you can do. You can use the idea of anchor boxes.
Let's start with an example. Let's say you have an image like this.
And for this example, I am going to continue to use a 3 by 3 grid. Notice that the midpoint of the pedestrian and the midpoint of the car are in almost the same place and both of them fall into the same grid cell.
So, for that grid cell, if Y outputs a vector where you are detecting three classes, pedestrians, cars and motorcycles, it won't be able to output two detections. So I have to pick one of the two detections to output.
With the idea of anchor boxes, what you are going to do, is pre-define two different shapes called, anchor boxes or anchor box shapes. And what you are going to do is now, be able to associate two predictions with the two anchor boxes.
And in general, you might use more anchor boxes, maybe five or even more. But for this section, I am just going to use two anchor boxes just to make the description easier.
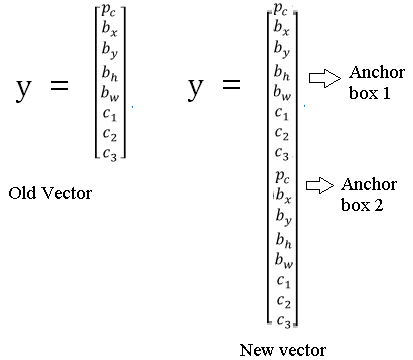
So what you do is you define the class label to be, instead of this vector on the left, you basically repeat this twice.
You will have PC, PX, PY, PH, PW, C1, C2, C3, and these are the eight outputs associated with anchor box 1. And then you repeat that PC, PX and so on down to C1, C2, C3, and other eight outputs associated with anchor box 2.
So, because the shape of the pedestrian is more similar to the shape of anchor box 1 and anchor box 2, you can use first eight numbers to encode a pedestrian.
And then because the box around the car is more similar to the shape of anchor box 2 than anchor box 1, you can then use next eight to encode that the second object is the car
So to summarize, previously, before you are using anchor boxes, you did the following, which is for each object in the training set and the training set image, it was assigned to the grid cell that corresponds to that object's midpoint.
And so the output Y was 3 by 3 by 8 because you have a 3 by 3 grid. And for each grid position, we had that output vector which is PC, then the bounding box, and C1, C2, C3.
With the anchor box, you now do that following. Now, each object is assigned to the same grid cell as before, assigned to the grid cell that contains the object's midpoint, but it is assigned to a grid cell and anchor box with the highest IoU with the object's shape.
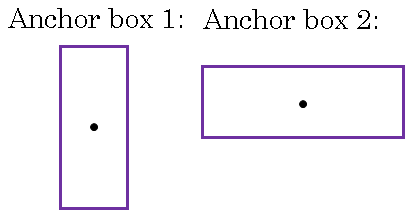
So, you have two anchor boxes, you will take an object and see. So if you have an object with this shape, what you do is take your two anchor boxes.
Maybe one anchor box is vertical shape - anchor box 1, maybe anchor box 2 is horizontal shape, and then you see which of the two anchor boxes has a higher IoU, will be drawn through bounding box.
And whichever it is, that object then gets assigned not just to a grid cell but to a pair. It gets assigned to grid cell comma anchor box pair. And that's how that object gets encoded in the target label.
And so now, the output Y is going to be 3 by 3 by 16. Because as you saw on the previous section, Y is now 16 dimensional. Or if you want, you can also view this as 3 by 3 by 2 by 8 because there are now two anchor boxes and Y is eight dimensional.
And dimension of Y being eight was because we have three objects causes if you have more objects than the dimension of Y would be even higher.
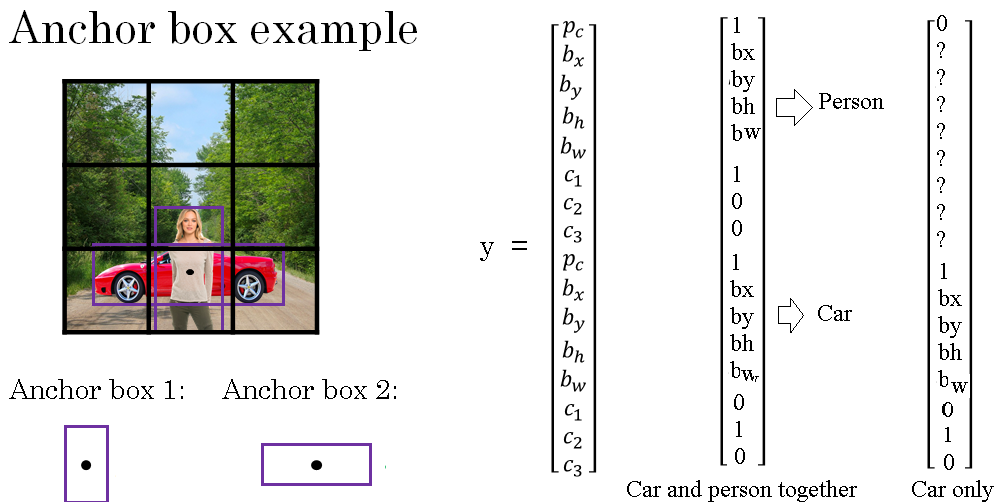
So let's go through a complete example. For the grid cell shown in the image above, let's specify what is Y. The pedestrian is more similar to the shape of anchor box 1.
So for the pedestrian, we're going to assign it to the top half of the vector. There will be some bounding box associated at the pedestrian. And if a pedestrian is class one, then we see one as [1 0 0 ].
And then the shape of the car is more similar to anchor box 2. And so the rest of this vector will be one and then the bounding box associated with the car, and then the car is C2, so there's zero, one, zero. And so that's the label Y for that lower middle grid cell
Now, what if this grid cell only had a car and had no pedestrian? If it only had a car, then assuming that the shape of the bounding box around the car is still more similar to anchor box 2, then the target label Y, if there was just a car there and the pedestrian had gone away, it will still be the same for the anchor box 2 component. Remember that this is a part of the vector corresponding to anchor box 2. And for the part of the vector corresponding to anchor box 1, what you do is you just say there is no object there. So PC is zero, and then the rest of these will be don't cares.
Now, just some additional details. What if you have two anchor boxes but three objects in the same grid cell? That's one case that this algorithm doesn't handle well. Hopefully, it won't happen. But if it does, this algorithm doesn't have a great way of handling it.
I will just influence some default tiebreaker for that case. Or what if you have two objects associated with the same grid cell, but both of them have the same anchor box shape? Again, that's another case that this algorithm doesn't handle well.
If you influence some default way of tiebreaking if that happens, hopefully this won't happen with your data set, it won't happen much at all. And so, it shouldn't affect performance as much.
So, that's it for anchor boxes. And even though I'd motivated anchor boxes as a way to deal with what happens if two objects appear in the same grid cell, in practice, that happens quite rarely, especially if you use a 19 by 19 rather than a 3 by 3 grid. The chance of two objects having the same midpoint rather these 361 cells, it does happen, but it doesn't happen that often.
Maybe even better motivation or even better results that anchor boxes gives you is it allows your learning algorithm to specialize better. In particular, if your data set has some tall, skinny objects like pedestrians, and some white objects like cars, then this allows your learning algorithm to specialize so that some of the outputs can specialize in detecting white, fat objects like cars, and some of the output units can specialize in detecting tall, skinny objects like pedestrians.
So finally, how do you choose the anchor boxes? And people used to just choose them by hand or choose maybe five or 10 anchor box shapes that spans a variety of shapes that seems to cover the types of objects you seem to detect.
As a much more advanced version, just in the advance common for those of who have other knowledge in machine learning, and even better way to do this in one of the later YOLO research papers, is to use a K-means algorithm, to group together two types of objects shapes you tend to get.
And then to use that to select a set of anchor boxes that this most stereotypically representative of the maybe multiple, of the maybe dozens of object causes you're trying to detect. But that's a more advanced way to automatically choose the anchor boxes.
And if you just choose by hand a variety of shapes that reasonably expands the set of object shapes, you expect to detect some tall, skinny ones, some fat, white ones. That should work with these as well. So that's it for anchor boxes. In the next section, let's take everything we've seen and tie it back together into the YOLO algorithm.

YOLO Algorithm
You've already seen most of the components of object detection. In this video, let's put all the components together to form the YOLO object detection algorithm.
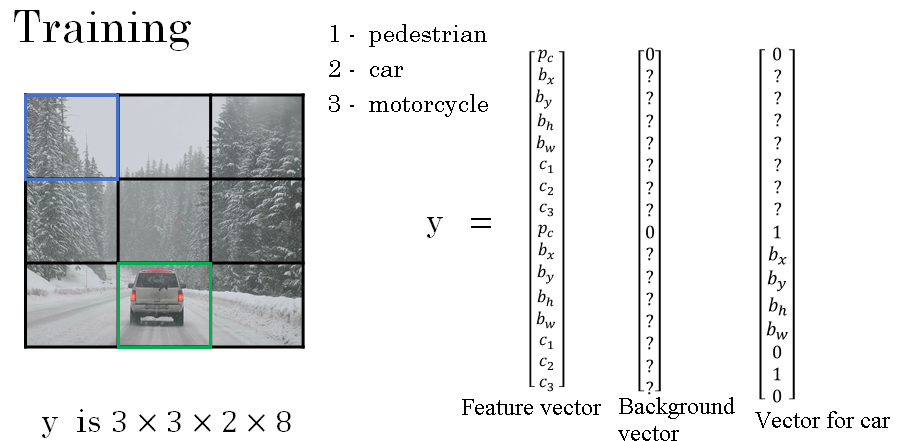
First, let's see how you construct your training set. Suppose you're trying to train an algorithm to detect three objects: pedestrians, cars, and motorcycles.
As shown above the feature vector will have 3 x 3 x 2 x 8 size. As 3 x 3 is the number of grid cells. 2 x 8 represents that each grid cell has 2 anchor boxes (vertical and horizontal). And each anchor box has 8 units (Pc, Bx, By, Bh, Bw, C1, C2, C3). All this is shown above.
And you can either view this as three by three by two by eight, or by three by three by sixteen.
So to construct the training set, you go through each of these nine grid cells and form the appropriate target vector y. So take this first grid cell, there's nothing worth detecting in that grid cell.
None of the three classes pedestrian, car and motocycle, appear in the upper left grid cell and so, the target y corresponding to that grid cell would be equal to this. Where Pc for the first anchor box is zero because there's nothing associated for the first anchor box, and is also zero for the second anchor box and so on all of these other values are don't cares.
Now, most of the grid cells have nothing in them, but for that box over there, you would have this target vector y. So assuming that your training set has a bounding box like this for the car, it's just a little bit wider than it is tall
So you go through this and for each of your nine grid positions each of your three by three grid positions, you would come up with a vector - 16 dimensional vector. And so that's why the final output volume is going to be 3 by 3 by 16.
Oh and as usual for simplicity on the slide I've used a 3 by 3 the grid. In practice it might be more like a 19 by 19 by 16. Or in fact if you use more anchor boxes, maybe 19 by 19 by 5 x 8 because five times eight is 40. So it will be 19 by 19 by 40. That's if you use five anchor boxes.
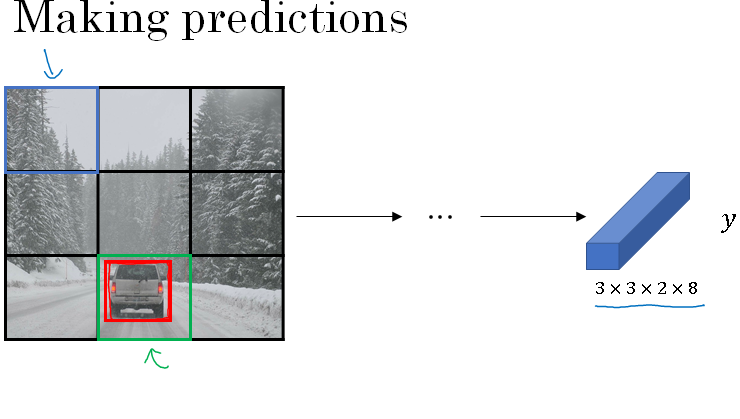
So that's training and you train ConvNet that inputs an image, maybe 100 by 100 by 3, and your ConvNet would then finally output this output volume in our example, 3 by 3 by 16 or 3 by 3 by 2 by 8.
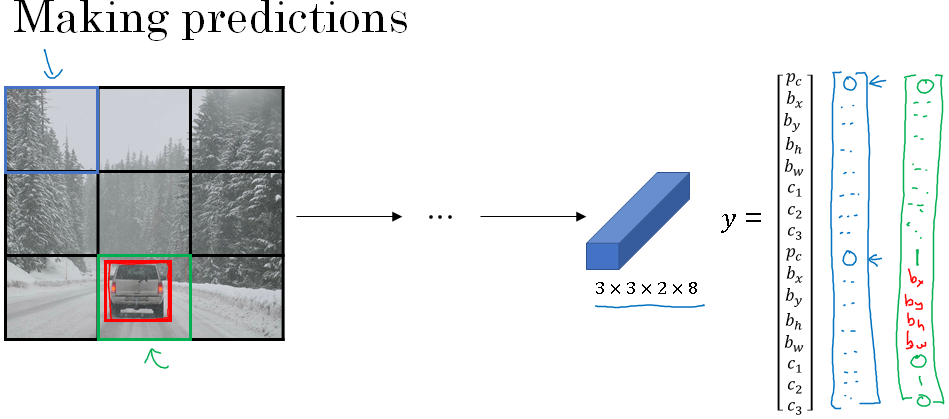
Next, let's look at how your algorithm can make predictions. Given an image, your neural network will output this by 3 by 3 by 2 by 8 volume, where for each of the nine grid cells you get a vector like that.
So for the grid cell on the upper left, if there's no object there, hopefully, your neural network will output zero and dont cares. Your neural network can't output a question mark, can't output a don't care. So I'll put some numbers for the rest. But these numbers will basically be ignored because the neural network is telling you that there's no object there.
So it doesn't really matter whether the output is a bounding box or there's is a car. So basically just be some set of numbers, more or less noise.
In contrast, for this box in green hopefully, the value of y to the output for that box at the bottom left, hopefully would be something like zero for bounding box one. And then just open a bunch of numbers, just noise. Hopefully, you'll also output a set of numbers that corresponds to specifying a pretty accurate bounding box for the car.
So that's how the neural network will make predictions.
Finally, you run this through non-max suppression. So just to make it interesting. Let's look at the new test set image.
Here's how you would run non-max suppression. If you're using two anchor boxes, then for each of the non-grid cells, you get two predicted bounding boxes.
Some of them will have very low probability, very low Pc, but you still get two predicted bounding boxes for each of the nine grid cells. So let's say, those are the bounding boxes you get. And notice that some of the bounding boxes can go outside the height and width of the grid cell that they came from. Next, you then get rid of the low probability predictions.
And then finally if you have three classes you're trying to detect, you're trying to detect pedestrians, cars and motorcycles. What you do is, for each of the three classes, independently run non-max suppression for the objects that were predicted to come from that class.
But use non-max suppression for the predictions of the pedestrians class, run non-max suppression for the car class, and non-max suppression for the motorcycle class.
But run that basically three times to generate the final predictions. And so the output of this is hopefully that you will have detected all the cars and all the pedestrians in this image.
So that's it for the YOLO object detection algorithm. Which is really one of the most effective object detection algorithms, that also encompasses many of the best ideas across the entire computer vision literature that relate to object detection. And you get a chance to practice implementing many components of this yourself, in the programming exercise.