Attention Model Intuition
For most of this course, you've been using a Encoder-Decoder architecture for machine translation. Where one RNN reads in a sentence and then different one outputs a sentence.

There's a modification to this called the Attention Model, that makes all this work much better.
The attention algorithm, the attention idea has been one of the most influential ideas in deep learning. Let's take a look at how that works. Get a very long French sentence like this.
Jane s'est rendue en Afrique en septembre dernier, a apprécié la culture et a rencontré beaucoup de gens merveilleux; elle est revenue en parlant comment son voyage était merveilleux, et elle me tente d'y aller aussi.
What we are asking this green encoder in your network to do is, to read in the whole sentence and then memorize the whole sentences and store it in the activations conveyed here. Then for the purple network, the decoder network then generate the English translation.
Jane went to Africa last September and enjoyed the culture and met many wonderful people; she came back raving about how wonderful her trip was, and is tempting me to go too.
Now, the way a human translator would translate this sentence is not to first read the whole French sentence and then memorize the whole thing and then regurgitate an English sentence from scratch.
Instead, what the human translator would do is read the first part of it, maybe generate part of the translation. Look at the second part, generate a few more words, look at a few more words, generate a few more words and so on.
You kind of work part by part through the sentence, because it's just really difficult to memorize the whole long sentence like that.
What you see for the Encoder-Decoder architecture above is that, it works quite well for short sentences, so we might achieve a relatively high score, but for very long sentences, maybe longer than 30 or 40 words, the performance comes down.
In this section, you'll see the Attention Model which translates maybe a bit more like humans might, looking at part of the sentence at a time and with an Attention Model, machine translation systems performance can look like this, because by working one part of the sentence at a time, you don't see this huge dip which is really measuring the ability of a neural network to memorize a long sentence which maybe isn't what we most badly need a neural network to do.
In this section, I want to just give you some intuition about how attention works and then we'll flesh out the details in the next section. The Attention Model was due to Dimitri, Bahdanau, Camcrun Cho, Yoshe Bengio and even though it was obviously developed for machine translation, it spread to many other application areas as well. This is really a very influential, I think very seminal paper in the deep learning literature.
Let's illustrate this with a short sentence, even though these ideas were maybe developed more for long sentences, but it'll be easier to illustrate these ideas with a simpler example. We have our usual sentence, Jane visite l'Afrique en Septembre.
Let's say that we use a RNN, and in this case, I'm going to use a bidirectional RNN, in order to compute some set of features for each of the input words and you have to understand it, bidirectional RNN with outputs \( Y^{<1>} \) to \( Y^{<3>} \) and so on up to \( Y^{<5>} \) but we're not doing a word for word translation.
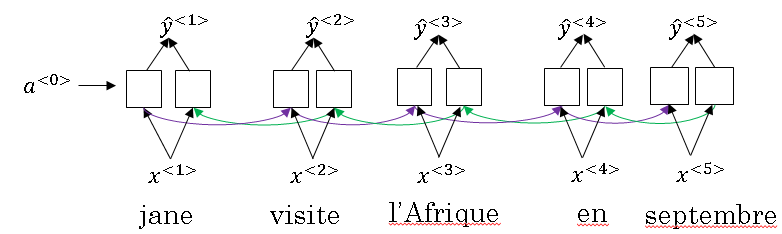
But using a bidirectional RNN, what we've done is for each of the five positions into sentence, you can compute a very rich set of features about the words in the sentence and maybe surrounding words in every position.
Now, let's go ahead and generate the English translation. We're going to use another RNN to generate the English translations. Here's my RNN note as usual and instead of using A to denote the activation, in order to avoid confusion with the activations down here, I'm just going to use a different notation.
I'm going to use S to denote the hidden state in this RNN up here, so instead of writing A1 I'm going to right S1 and so we hope in this model that the first word it generates will be Jane, to generate Jane visits Africa in September.
Now, the question is, when you're trying to generate this first word, this output, what part of the input French sentence should you be looking at? Seems like you should be looking primarily at this first word, maybe a few other words close by, but you don't need to be looking way at the end of the sentence.
What the Attention Model would be computing is a set of attention weights and we're going to use Alpha one, one to denote when you're generating the first words, how much should you be paying attention to this first piece of information.
And then we'll also come up with a second that's called Attention Weight, Alpha one, two which tells us what we're trying to compute the first work of Jane, how much attention we're paying to this second word from the inputs and so on and the Alpha one, three and so on, and together this will tell us what is exactly the context from decoder C that we should be paying attention to, and that is input to this RNN unit to then try to generate the first words.
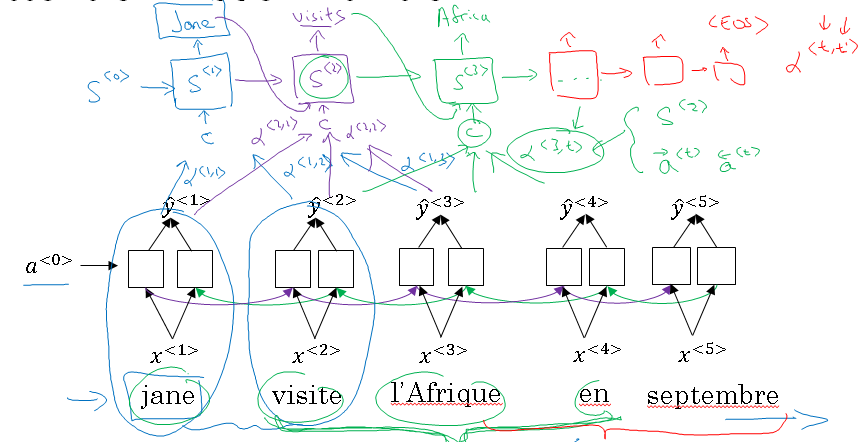
That's one step of the RNN, we will flesh out all these details in the next section. For the second step of this RNN, we're going to have a new hidden state S-two and we're going to have a new set of the attention weights. We're going to have Alpha two, one to tell us when we generate in the second word.
I guess this will be "visits" maybe that being the ground truth label. How much should we paying attention to the first word in the french input and also, Alpha two, two and so on.
How much should we paying attention the word visite, how much should we pay attention to the free and so on. And of course, the first word we generate in Jane is also an input to this, and then we have some context that we're paying attention to and the second step, there's also an input and that together will generate the second word and that leads us to the third step, S-three, where this is an input and we have some new context C that depends on the various Alpha three for the different time sets, that tells us how much should we be paying attention to the different words from the input French sentence and so on.
So, some things I haven't specified yet, but that will go further into detail in the next section of this, how exactly this context defines and the goal of the context is for the third word is really should capture that maybe we should be looking around this part of the sentence.
The amounts that this RNN step should be paying attention to the French word that time T, that depends on the activations of the bidirectional RNN at time T, I guess it depends on the fourth activations and the, backward activations at time T and it will depend on the state from the previous steps, it will depend on S two, and these things together will influence, how much you pay attention to a specific word in the input French sentence.
But we'll flesh out all these details in the next video. But the key intuition to take away is that this way the RNN marches forward generating one word at a time, until eventually it generates maybe the EOS and at every step, there are these attention weighs. Alpha T.T. Prime that tells it, when you're trying to generate the T, English word, how much should you be paying attention to the T prime French words.
And this allows it on every time step to look only maybe within a local window of the French sentence to pay attention to, when generating a specific English word. I hope this section conveys some intuition about Attention Model and that we now have a rough sense of, maybe how the algorithm works.