Viterbi algorithm
-
Colab
The Viterbi algorithm makes use of the transition probabilities and the emission probabilities.
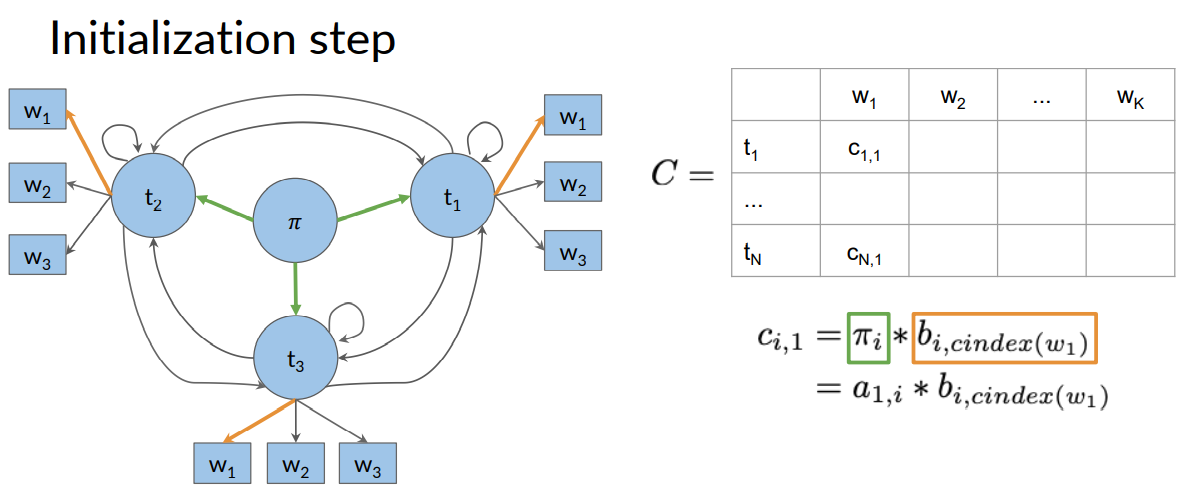
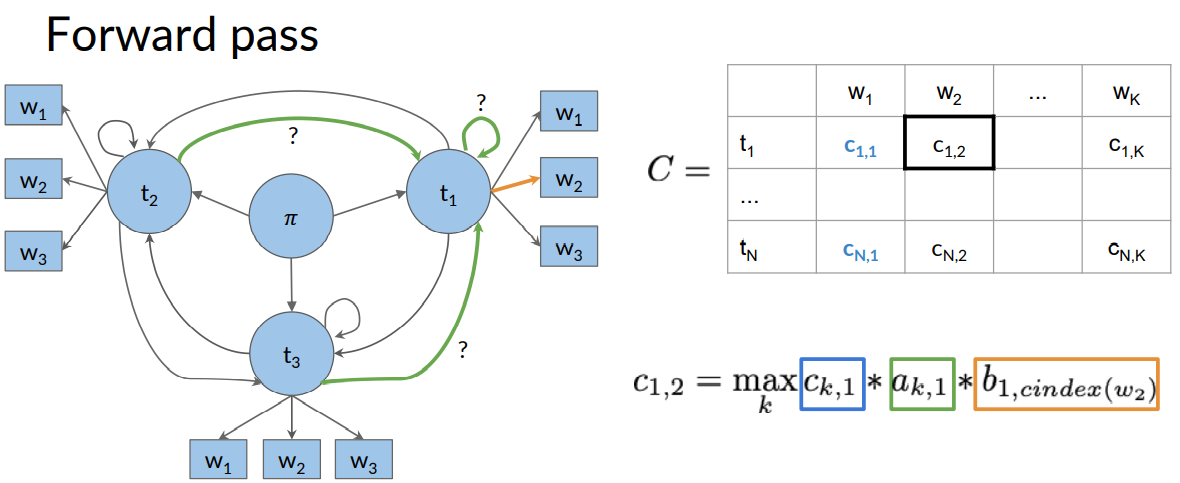
You will now populate a matrix C of dimension (num_tags, num_words). This matrix will have the probabilities that will tell you what part of speech each word belongs to.
Now to populate the first column of C matrix, you have to refer to both the transition matrix given by A or a and the emission matrix given by B or b. So the first column of matrix C which is labeled by C(i,1) where i is the row and 1 is the first column. Total rows in C are equal to the number of tags such as NN, VB etc.
To get C(1,1) we need to multiply A(π, 1) with B(1,w1). Assume in our data, i=1 is the tag NN and assume in NN tag the first word is 'in' then we look in the transition matrix A and emission matrix B for A(π,NN) and B(NN,'in') and multiply them and place the resultant product in C(1,1) and continue like this to fill the remaining rows of first column of C.
At first you set the first column of D to 0, because you are not coming from any POS tag.
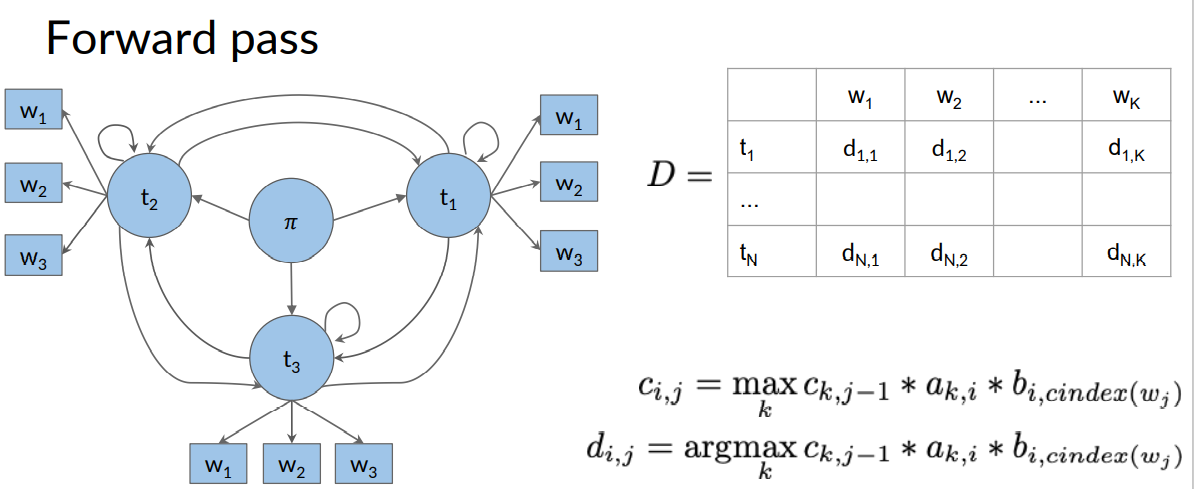
Now for the second column of the C and D. We fill on basis of the below given formulae.
For example, C(1,2) would be a product of terms given below
The C(1,2) depends on three terms from above figure \(c_{i, j}=\max _{k} c_{k, j-1} * a_{k, i} * b_{i, c i n d e x\left(w_{j}\right)}\). The last term \(b_{i, c i n d e x\left(w_{j}\right)}\) means the emission probability from tag i to word j. This is obtained from the emission probability table.
The remaining two terms \(c_{k, j-1} * a_{k, i}\) are the chosen based on k which can be any tag. We need to choose k such that product is maximised. Then once k is chosen the product is put into the cell C(1,2).
The k value that maximised the product is then put into cell D(1,2)
Thus, the algorithm proceeds column by column for C and D.

Viterbi: Backward Pass
Great, now that you know how to compute A, B, C, and D, we will put it all together and show you how to construct the path that will give you the part of speech tags for your sentence.
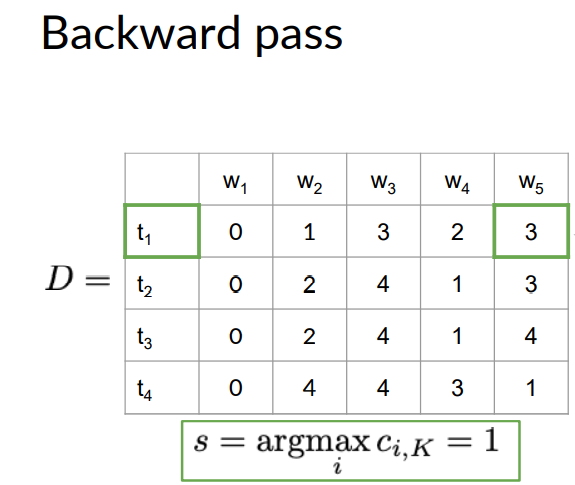
The corresponding D matrix will look like given below
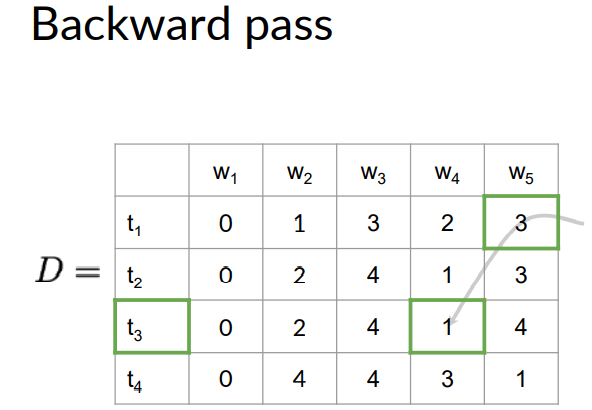
The way of finding the part of speech tag is to go the last word of the C matrix. Which is given in above figure as W5. Then in the column W5 of the C matrix we find the row number which has the highest probability.
We go to the correspoding cell of the D matrix which is cell D(t1,W5). In this cell we see the number 3 written in it.
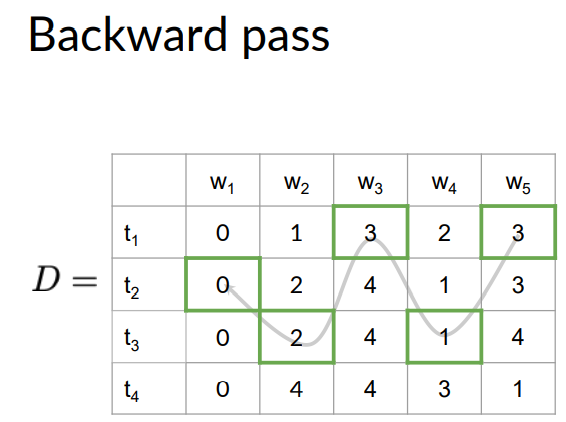
Then in D matrix we go to the row number 3 in previous column W4 as shown below. And the word W4 gets assigned to tag T3.
The number written in the cell is then used to navigate to the cell position in the previous column and the process continues till we reach the first word.
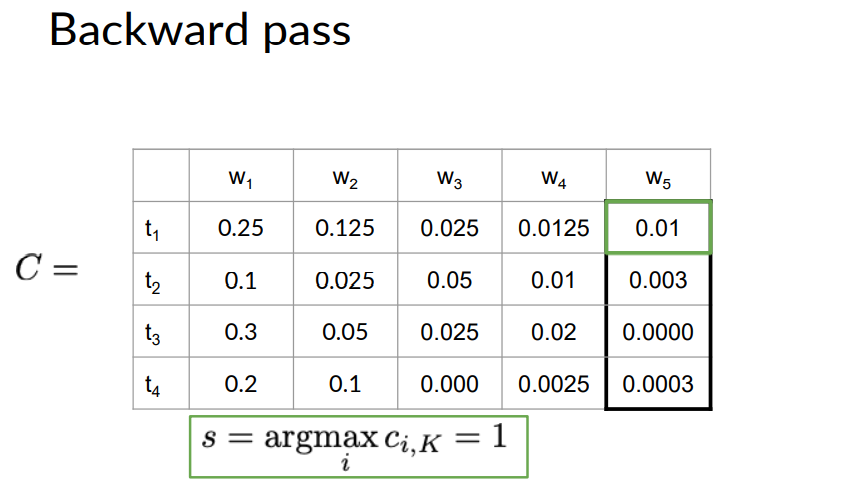
As seen in the figure the highest probability belongs to 0.01 which is the first row of the C matrix. This means that word W5 has the tag t1. Now for the other words we do below steps.