Multiprocessors
A multiprocessor system is a.n intercoMection of two or more CPUs with memory and input-output equipment. The term "processor" In multiprocessqr can mean either a central processing unit (CPU) or an input-output processor (IOP).
However, a system with a single CPU and one or more IOPs is usually not included in the definition of a multiprocessor system unless the IOP has computational facilities comparable to a CPU.
As it is most commonly defined, a multiprocessor system implies the existence of multiple CPUs, although usually there will be one or more IOPs as well.
Multiprocessors are classified as multiple instruction stream, multiple data stream (MIMO) systems.
There are some similarities between multiprocessor and multicomputer systems since both support concurrent operations.
However, there exists an important distinction between a system with multiple computers and a system with multiple processors.
Computers are interconnected with each other by means of communication lines to form a computer network.
The network consists of several autonomous computers that may or may not communicate with each other.
A multiprocessor system is controlled by one operating system that provides interaction between processors and all the components of the system cooperate in the solution of a problem.
Although some large-scale computers include two or more CPUs in their overall system, it is the emergence of the microprocessor that has been the major motivation for multiprocessor systems.
The fact that microprocessors take very little physical space and are very inexpensive brings about the feasibility of interconnecting a large number of microprocessors into one composite system.
Very-large-scale integrated circuit technology has reduced the cost of computer components to such a low level that the concept of applying multiple processors to meet system performance requirements has become an attractive design possibility.
Multiprocessing improves the reliability of the system so that a failure or error in one part has a limited effect on the rest of the system.
If a fault causes one processor to fail, a second processor can be assigned to perform the functions of the disabled processor.
The system as a whole can continue to function correctly with perhaps some loss in efficiency. The benefit derived from a multiprocessor organization is an improved system performance. The system derives its high performance from the fact that computations can proceed in parallel in one of two ways.
1. Multiple independent jobs can be made to operate in parallel. 2. A single job can be partitioned into multiple parallel tasks.
An overall function can be partitioned into a number of tasks that each processor can handle individually.
System tasks may be allocated to specialpurpose processors whose design is optimized to perform certain types of processing efficiently.
An example is a computer system where one processor performs the computations for an industrial process control while others monitor and control the various parameters, such as temperature and flow rate .
Another example is a computer where one processor performs highspeed floating-point mathematical computations and another takes care of routine data-processing tasks.
Multiprocessing can improve performance by decomposing a program into parallel executable tasks. This can be achieved in one of two ways. The user can explicitly declare that certain tasks of the program be executed in parallel.
This must be done prior to loading the program by specifying the parallel executable segments.
Most multiprocessor manufacturers provide an operating system with programming language constructs suitable for specifying parallel processing.
The other, more efficient way is to provide a compiler with multiprocessor software that can automatically detect parallelism in a user's program.
The compiler checks for data dependency in the program. If a program depends on data generated in another part, the part yielding the needed data must be executed first.
However, two parts of a program that do not use data generated by each can run concurrently.
The parallelizing compiler checks the entire program to detect any possible data dependencies. These that have no data dependency are then considered for concurrent scheduling on different processors.
Multiprocessors are classified by the way their memory is organized. A multiprocessor system with common shared memory is classified as a sharedmemory or tightly coupled multiprocessor.
This does not preclude each processor from having its own local memory. In fact, most commercial tightly coupled multiprocessors provide a cache memory with each CPU. In addition, there is a global common memory that all CPUs can access.
Information can therefore be shared among the CPUs by placing it in the common global memory. An alternative model of microprocessor is the distributed-memory or loosely coupled system.
Each processor element in a loosely coupled system has its own private local memory. The processors are tied together by a switching scheme designed to route information from one processor to another through a message-passing scheme.
The processors relay program and data to other processors in packets. A packet consists of an address, the data content, and some error detection code.
The packets are addressedto a specific processor or taken by the first available processor, depending on the communication system used.
Loosely coupled systems are most efficient when the interaction between tasks is minimal, whereas tightly coupled systems can tolerate a higher degree of interaction between tasks.
Interconnection Structures
The components that form a multiprocessor system are CPUs, IOPs connected to input-output devices, and a memory unit that may be partitioned into a number of separate modules.
The interconnection between the components can have different physical configurations, depending on the number of transfer paths that are available between the processors and memory in a shared memory system or among the processing elements in a loosely coupled system.
There are several physical forms available for establishing an interconnection network such as.
1. Time-shared common bus 2. Multiport memory 3. Crossbar switch 4. Multistage switching network 5. Hypercube system
Time-Shared Common Bus
A common-bus multiprocessor system consists of a number of processors connected through a common path to a memory unit. A time-shared common bus for five processors is shown in Fig. 1 . Only one processor can communicate with the memory or another processor at any given time.
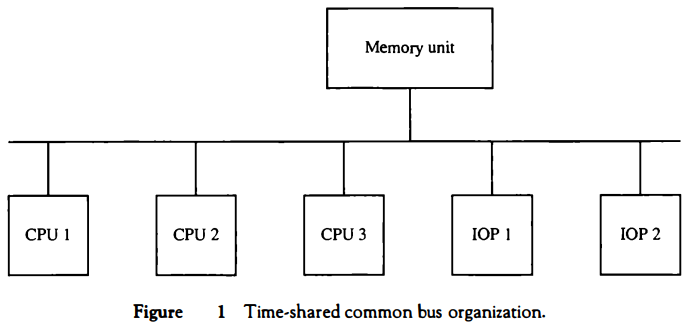
Transfer operations are conducted by the processor that is in control of the bus at the time.
Any other processor wishing to initiate a transfer must first determine the availability status of the bus, and only after the bus becomes available can the processor address the destination unit to initiate the transfer.
A command is issued to inform the destination unit what operation is to be performed.
The receiving unit recognizes its address in the bus and responds to the control signals from the sender, after which the transfer is initiated.
The system may exhibit transfer conflicts since one common bus is shared by all processors. These conflicts must be resolved by incorporating a bus controller that establishes priorities among the requesting units.
A single common-bus system is restricted to one transfer at a time.
This means that when one processor is communicating with the memory, all other processors are either busy with internal operations or must be idle waiting for the bus.
As a consequence, the total overall transfer rate within the system is limited by the speed of the single path.
The processors in the system can be kept busy more often through the implementation of two or more independent buses to permit multiple simultaneous bus transfers. However, this increases the system cost and complexity.
A more economical implementation of a dual bus structure is depicted in Fig. 2.
-
Here we have a number of local buses each connected to its own local memory and to one or more processors. Each local bus may be connected to a CPU, an IOP, or any combination of processors.
A system bus controller links each local bus to a common system bus. The I/O devices connected to the local IOP, as well as the local memory, are available to the local processor.
The memory connected to the common system bus is shared by all processors. If an IOP is connected directly to the system bus, the I/O devices attached to it may be made available to all processors.
Only one processor can communicate with the shared memory and other common resources through the system bus at any given time.
The other processors are kept busy communicating with their local memory and I/O devices. Part of the local memory may be designed as a cache memory attached to the CPU.
In this way, the average access time of the local memory can be made to approach the cycle time of the CPU to which it is attached.
Multiport Memory
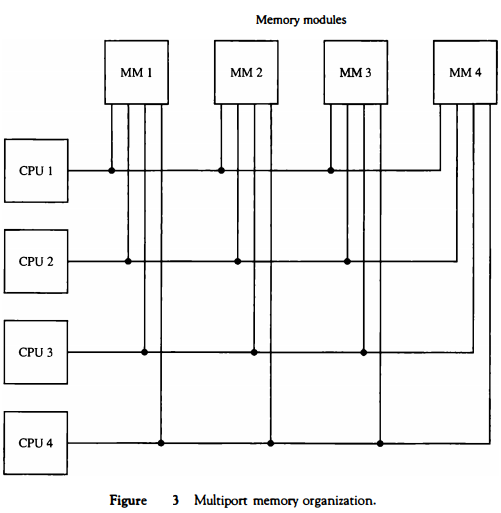
A multiport memory system employs separate buses between each memory module and each CPU.
This is shown in Fig . 3 for four CPUs and four memory modules (MMs).
Each processor busis Connected to each memory module.
A processor bus consists of the address, data, and control lines required to communicate with memory.
The memory module is said to have four ports and each port accommodates one of the buses. The module must have internal control logic to determine which port will have access to memory at any given time. Memory access conflicts are resolved by assigning fixed priorities to each memory port.
The priority for memory acoess associated with each processor may be established by the physical port position that its bus occupies in each module.
Thus CPU 1 will have priority over CPU 2, CPU 2 will have priority over CPU 3, and CPU 4 will have the lowest priority.
The advantage of the multi port memory organization is the high transfer rate that can be achieved because of the multiple paths between processors and memory.
The disadvantage is that it requires expensive memory control logic and a large number of cables and connectors. As a consequence, this interconnection structure is usually appropriate for systems with a small number of processors.
Interprocessor Communication and Synchronization
The various processors in a multiprocessor system must be provided with a facility for communicating with each other. A communication path can be established through common input-output channels.
In a shared memory multiprocessor system, the most common procedure is to set aside a portion of memory that is accessible to all processors.
The primary use of the common memory is to act as a message center similar to a mailbox, where each processor can leave messages for other processors and pick up messages intended for it.
The sending processor structures a request, a message, or a procedure, and places it in the memory mailbox. Status bits residing in common memory are generally used to indicate the condition of the mailbox, whether it has meaningful information, and for which processor it is intended.
The receiving processor can check the mailbox periodically to determine if there are valid messages for it. The response time of this procedure can be time consuming since a processor will recognize a request only when polling messages.
A more efficient procedure is for the sending processor to alert the receiving processor directly by means of an interrupt signal.
This can be accomplished through a software-initiated interprocessor interrupt by means of an instruction in the program of one processor which when executed produces an external interrupt condition in a second processor.
This alerts the interrupted processor of the fact that a new message was inserted by the interrupting processor.
In addition to shared memory, a multiprocessor system may have other shared resources. For example, a magnetic disk storage unit connected to an lOP may be available to all CPUs.
This provides a facility for sharing of system programs stored in the disk. A communication path between two CPUs can be established through a link between two I/O Ps associated with two different CPUs. This type of link allows each CPU to treat the other as an I/O device so that messages can be transferred through the I/O path.
To prevent conflicting use of shared resources by several processors there must be a provision for assigning resources to processors.
This task is given to the operating system. There are three organizations that have been used in the design of operating system for multiprocessors: master-slave configuration, separate operating system, and distributed operating system.
In a master-slave mode, one processor, designated the master, always executes the operating system functions. The remaining processors, denoted as slaves, do not perform operating system functions.
If a slave processor needs an operating system service, it must request it by interrupting the master and waiting until the current program can be interrupted.
In the separate operating system organization, each processor can execute the operating system routines it needs.
This organization is more suitable for loosely coupled systems where every processor may have its own copy of the entire operating system.
In the distributed operating system organization, the operating system routines are distributed among the available processors.
However, each particular operating system function is assigned to only one processor at a time.
This type of organization is also referred to as a floating operating system since the routines float from one processor to another and the execution of the routines may be assigned to different processors at different times. In a loosely coupled multiprocessor system the memory is distributed among the processors and there is no shared memory for passing information. The communication between processors is by means of message passing through I/O channels.
The communication is initiated by one processor calling a procedure that resides in the memory of the processor with which it wishes to communicate. When the sending processor and receiving processor name each other as a source and destination, a channel of communication is established.
A message is then sent with a header and various data objects used to communicate between nodes. There may be a number of possible paths available to send the message between any two nodes.
The operating system in each node contains routing information indicating the alternative paths that can be used to send a message to other nodes.
The communication efficiency of the interprocessor network depends on the communication routing protocol, processor speed, data link speed, and the topology of the network.
lnterprocessor Synchronization
The instruction set of a multiprocessor contains basic instructions that are used to implement communication and synchronization between cooperating processes.
Communication refers to the exchange of data between different processes.
For example, parameters passed to a procedure in a different processor constitute interprocessor communication. Synchronization refers to the special case where the data used to communicate between processors is control information.
Synchronization is needed to enforce the correct sequence of processes and to ensure mutually exclusive access to shared writable data. Multiprocessor systems usually include various mechanisms to deal with the synchronization of resources.
Low-level primitives are implemented directly by the hardware. These primitives are the basic mechanisms that enforce mutual exclusion for more complex mechanisms implemented in software.
A number of hardware mechanisms for mutual exclusion have been developed. One of the most popular methods is through the use of a binary semaphore
Mutual Exclusion with a Semaphore
A properly functioning multiprocessor system must provide a mechanism that will guarantee orderly access to shared memory and other shared resources.
This is necessary to protect data from being changed simultaneously by two or more processors. This mechanism has been termed mutual exclusion. Mutual exclusion must be provided in a multiprocessor system to enable one processor to exclude or lock out access to a shared resource by other processors when it is in a critical section.
A critical section is a program sequence that, once begun, must complete execution before another processor accesses the same shared resource.
A binary variable called a semaphore is often used to indicate whether or not a processor is executing a critical section. A semaphore is a softwarecontrolled flag that is stored in a memory location that all processors can access.
When the semaphore is equal to 1, it means that a processor is executing a critical program, so that the shared memory is not available to other processors.
When the semaphore is equal to 0, the shared memory is available to any requesting processor. Processors that share the same memory segment agree by convention not to use the memory segment unless the semaphore is equal to 0, indicating that memory is available. They also agree to set the semaphore to 1 when they are executing a critical section and to clear it to 0 when they are finished.
Testing and setting the semaphore is itself a critical operation and must be performed as a single indivisible operation.
If it is not, two or more processors may test the semaphore simultaneously and then each set it, allowing them to enter a critical section at the same time.
This action would allow simultaneous execution of critical section, which can result in erroneous initialization of control parameters and a loss of essential information.
A semaphore can be initialized by means of a test and set instruction in conjunction with a hardware lock mechanism. A hardware lock is a processorgenerated signal that serves to prevent other processors from using the system bus as long as the signal is active.
The test-and-set instruction tests and sets a semaphore and activates the lock mechanism during the time that the instruction is being executed. This prevents other processors from changing the semaphore between the time that the processor is testing it and the time that it is setting it.
Assume that the semaphore is a bit in the least significant position of a memory word whose address is symbolized by SEM. Let the mnemonic TSL designate the "test and set while locked" operation.
The instruction TSL SEM will be executed in two memory cycles (the first to read and the second to write without interference as follows:
R ← M[SEM] Test semaphore M[SEM] ← 1 Set semaphore
The semaphore is tested by transferring its value to a processor register R and then it is set to 1. The value in R determines what to do next.
If the processor finds that R = 1, it knows that the semaphore was originally set. (The fact that it is set again does not change the semaphore value.)
That means that another processor is executing a critical section, so the processor that checked the semaphore does not access the shared memory. If R = 0, it means that the common memory (or the shared resource that the semaphore represents) is available.
The semaphore is set to 1 to prevent other processors from accessing memory. The processor can now execute the critical section. The last instruction in the program must clear location SEM to zero to release the shared resource to other processors.
Note that the lock signalmust be active during the execution of the test-and-set instruction. It does not have to be active once the semaphore is set.
Thus the lock mechanism prevents other processors from accessing memory while the semaphore is being set. The semaphore itself, when set, prevents other processors from accessing shared memory while one processor is executing a critical section.
Cache Coherence
The primary advantage of cache is its ability to reduce the average access time in uniprocessors.
When the processor finds a word in cache during a read operation, the main memory is not involved in the transfer. If the operation is to write, there are two commonly used procedures to update memory.
In the write-through policy, both cache and main memory are updated with every write operation. In the write-back policy, only the cache is updated and the location is marked so that it can be copied later into main memory.
In a shared memory multiprocessor system, all the processors share a common memory. In addition, each processor may have a local memory, part or all of which may be a cache. The compelling reason for having separate caches for each processor is to reduce the average access time in each processor.
The same information may reside in a number of copies in some caches and main memory.
To ensure the ability of the system to execute memory operations correctly, the multiple copies must be kept identical. This requirement imposes a cache coherence problem.
A memory scheme is coherent if the value returned on a load instruction is always the value given by the latest store instruction with the same address.
Without a proper solution to the cache coherence problem, caching cannot be used in bus-oriented multiprocessors with two or more processors.
Conditions for Incoherence
Cache coherence problems exist in multiprocessors with private caches because of the need to share writable data. Read-only data can safely be replicated without cache coherence enforcement mechanisms.
To illustrate the problem, consider the three-processor configuration with private caches shown in Fig. 12. Sometime during the operation an element X from main memory is loaded into the three processors, P1, P2, and P3.
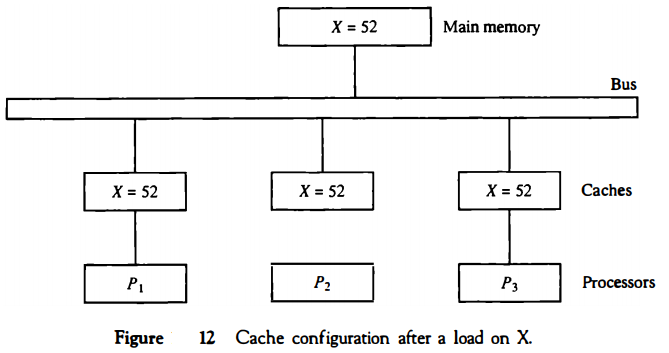
As a consequence, it is also copied into the private caches of the three processors. For simplicity, we assume that X contains the value of 52. The load on X to the three processors results in consistent copies in the caches and main memory.
If one of the processors performs a store to X, the copies of X in the caches become inconsistent. A load by the other processors will not return the latest value. Depending on the memory update policy used in the cache, the main memory may also be inconsistent with respect to the cache.
This is shown in Fig. 13. A store to X (of the value of 120) into the cache of processor P1 updates memory to the new value in a write-through policy.
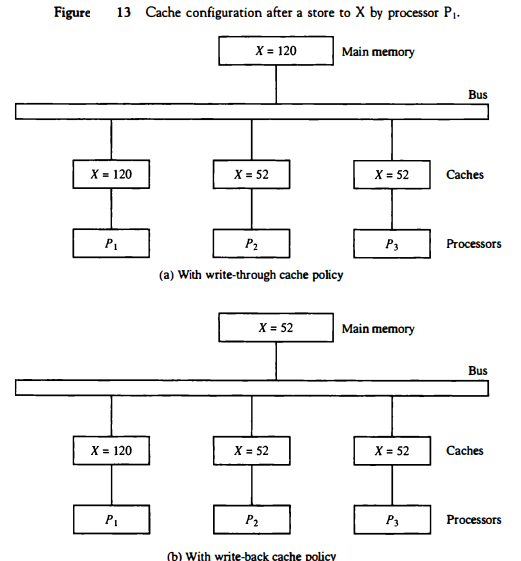
A write-through policy maintains consistency between memory and the originating cache, but the other two caches are inconsistent since they still hold the old value. In a write-back policy, main memory is not updated at the time of the store.
The copies in the other two caches and main memory are inconsistent. Memory is updated eventually when the modified data in the cache are copied back into memory.
Another configuration that may cause consistency problems is a direct memory access (DMA) activity in conjunction with an IOP connected to the system bus. In the case of input, the DMA may modify locations in main memory that also reside in cache without updating the cache.
During a DMA output, memory locations may be read before they are updated from the cache when using a write-back policy. I/O-based memory incoherence can be overcome by making the IOP a participant in the cache coherent solution that is adopted in the system.
Solutions to the Cache Coherence Problem
A simple scheme is to disallow private caches for each processor and have a shared cache memory associated with main memory. Every data access is made to the shared cache.
This method violates the principle of closeness of CPU to cache and increases the average memory access time. In effect, this scheme solves the problem by avoiding it.
For performance considerations it is desirable to attach a private cache to each processor. One scheme that has been used allows only nonshared and read-only data to be stored in caches.
Such items are called cachable. Shared writable data are noncachable. The compiler must tag data as either cachable or noncachable, and the system hardware makes sure that only cachable data are stored in caches.
The noncachable data remain in main memory. This method restricts overhead the type of data stored in caches and introduces an extra software that may degradate performance.
A scheme that allows writable data to exist in at least one cache is a method that employs a centralized global table in its compiler. The status of memory blocks is stored in the central global table.
Each block is identified as read-only (RO) or read and write (RW). All caches can bave copies of blocks identified as RO.
Only one cache can bave a copy of an RW block. Thus if the data affected are updated in the cache with an RW block, the other caches are not because they do not have a copy of this block.
The cache coherence problem can be solved by means of a combination of software and hardware or by means of hardware-only schemes. The two methods mentioned previously use software based procedures that require the ability to tag information in order to disable caching of shared writable data.
Hardware-only solutions are handled by the hardware automatically and have the advantage of higher speed and program transparency.
In the hardware solution, the cache controller is specially designed to allow it to monitor all bus requests from CPUs and IOPs.
All caches attached to the bus constantly monitor the network for possible write operations.
Depending on the method used, they must then either update or invalidate their own cache copies when a match is detected. The bus controller that monitors this action is referred to as a snoopy cache controller. This Is basically a hardware unit designed to maintain a bus-watching mechanism over all the caches attached to the bus.
Various schemes bave been proposed to solve the cache coherence problem by means of snoopy cache protocol
The simplest method is to adopt a write through policy and use the following procedure. All the snoopy controllers watch the bus for memory store operations.
When a word in a cache Is updated by writing into it, the corresponding location in main memory is also updated.
The local snoopy controllers in all other caches check their memory to determine if they have a copy of the word that has been overwritten.
If a copy exists In a remote cache, that location is marked invalid.
Because all caches snoop on all bus writes, whenever a word is written, the net effect is to update it In the original cache and main memory and remove It from all other caches.
If at some future time a processor accesses the invalid Item from its cache, the response is equivalent to a cache miss, and the updated Item is transferred from main memory. In this way, inconsistent versions are prevented.