RELATIONAL DATABASES
A data model is a collection of conceptual tools for describing data, data relationships, data semantics, and consistency constraints. One such class of data model is relational model.
The relational model uses a collection of tables to represent both data and the relationships among those data.
It describes data at the logical and view levels, abstracting away low-level details of data storage.
Structure of Relational Databases
A relational database consists of a collection of tables, each of which is assigned a unique name.
A row in a table represents a relationship among a set of values. A table is a collection of such relationships.
A relationship between 'n' values is represented mathematically by an n-tuple of values, i.e., a tuple with 'n' values, which corresponds to a row in a table.
Thus, in the relational model the term relation is used to refer to a table, while the term tuple is used to refer to a row. Similarly, the term attribute refers to a column of a table.
The term relation instance to refer to a specific instance of a relation, i.e., containing a specific set of rows.
For each attribute of a relation, there is a set of permitted values, called the domain of that attribute. Thus, the domain of the salary attribute of the instructor relation is the set of all possible salary values, while the domain of the name attribute is the set of all possible instructor names.
For all relations 'r', the domains of all attributes of 'r' be atomic. A domain is atomic if elements of the domain are considered to be indivisible units.
For example, suppose the table instructor had an attribute phone number, which can store a set of phone numbers corresponding to the instructor. Then the domain of phone number would not be atomic, since an element of the domain is a set of phone numbers, and it has sub-parts, namely the individual phone numbers in the set. If however only one number was permitted then it would be atomic.
Database Schema
Database schema - is the logical design of the database, and the database instance - is a snapshot of the data in the database at a given instant in time.
The concept of a relation corresponds to the programming-language notion of a variable, while the concept of a relation schema corresponds to the programming-language notion of type definition.
A relation schema consists of a list of attributes and their corresponding domains.
The schema for a relation: department (dept name, building, budget)
Using common attributes in relation schemas is one way of relating tuples of distinct relations.
For example, suppose we wish to find the information about all the instructors who work in the IIT building. We look first at the department relation to find the dept name of all the departments housed in IIT. Then, for each such department, we look in the instructor relation to find the information about the instructor associated with the corresponding dept name.
Keys
The values of the attribute values of a tuple must be such that they can uniquely identify the tuple.
No two tuples in a relation are allowed to have exactly the same value for all attributes.
A superkey is a set of one or more attributes that, taken collectively, allow us to identify uniquely a tuple in the relation.
For example, the ID attribute of the relation instructor is sufficient to distinguish one instructor tuple from another. Thus, ID is a superkey. The name attribute of instructor, on the other hand, is not a superkey, because several instructors might have the same name.
A superkey may contain extraneous attributes. For example, the combination of ID and name is a superkey for the relation instructor.
If K is a superkey, then so is any superset of K.
We are often interested in superkeys for which no proper subset is a superkey. Such minimal superkeys are called candidate keys.
It is possible that several distinct sets of attributes could serve as a candidate key. Suppose that a combination of 'name' and 'deptname' is sufficient to distinguish among members of the instructor relation.
Then, both { ID} and {name, dept name} are candidate keys.
The attributes ID and name together can distinguish instructor tuples, their combination, { ID, name}, does not form a candidate key, since the attribute ID alone is a candidate key.
Primary key - denotes a candidate key that is chosen by the database designer as the principal means of identifying tuples within a relation.
Foreign Key
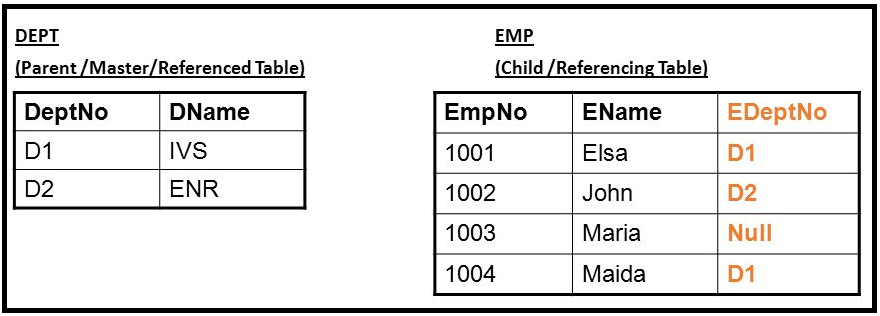
A relation, say 'r1', may include among its attributes the primary key of another relation, say 'r2'. This attribute is called a foreign key from r1 referencing r2.
The relation r1 is also called the referencing relation of the foreign key dependency, and r2 is called the referenced relation of the foreign key
For example, the attribute deptname in instructor is a foreign key from instructor, referencing department, since deptname is the primary key of department.
A referential integrity constraint requires that the values appearing in specified attributes of any tuple in the referencing relation also appear in specified attributes of at least one tuple in the referenced relation.
In above table, DeptNo is the primary key of Dept and it is foreign key of EMP table.
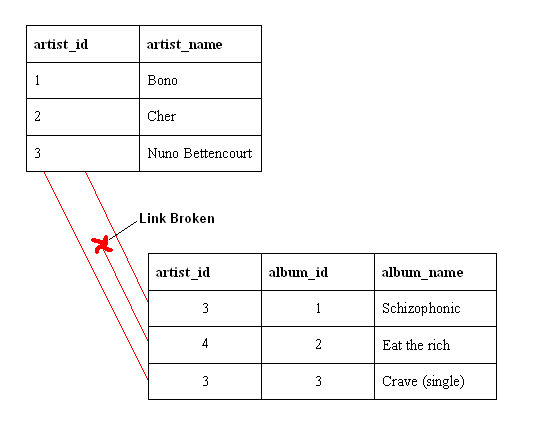
An example of a database that has not enforced referential integrity
There is a foreign key (artist_id) value in the album table that references a non-existent artist
In other words there is a foreign key value with no corresponding primary key value in the referenced table.
What happened here was that there was an artist called "Aerosmith", with an artist_id of 4, which was deleted from the artist table.
However, the album "Eat the Rich" referred to this artist. With referential integrity enforced, this would not have been possible.
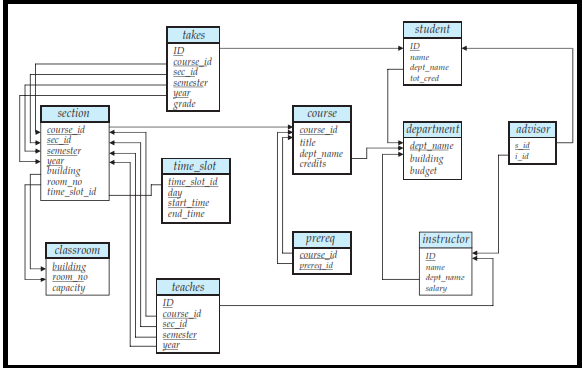
Schema Diagrams
Each relation appears as a box, with the relation name at the top in blue, and the attributes listed inside the box. Primary key attributes are shown underlined.
Foreign key dependencies appear as arrows from the foreign key attributes of the referencing relation to the primary key of the referenced relation.
Entityrelationship diagrams let us represent several kinds of constraints, including general referential integrity constraints.
Relational Query Languages
A query language is a language in which a user requests information from the database. These languages are usually on a level higher than that of a standard programming language.
In a procedural language, the user instructs the system to perform a sequence of operations on the database to compute the desired result.
In a nonprocedural language, the user describes the desired information without giving a specific procedure for obtaining that information.
The relational query languages define a set of operations that operate on tables, and output tables as their results. These operations can be combined to get expressions that express desired queries.
The relational algebra provides a set of operations that take one or more relations as input and return a relation as an output. Practical query languages such as SQL are based on the relational algebra, but add a number of useful syntactic features.