Memory Management approach
The CPU can be shared by a set of processes. As a result of CPU scheduling, we can improve both the utilization of the CPU and the speed of the computer's response to its users. To realize this increase in performance, however, we must keep several processes in memory; that is, we must share memory.
Memory consists of a large array of words or bytes, each with its own address. The CPU fetches instructions from memory according to the value of the program counter. These instructions may cause additional loading from and storing to specific memory addresses.
A typical instruction-execution cycle, for example, first fetches an instruction (ADD, MOVE etc) from memory. The instruction is then decoded and may cause operands to be fetched from memory.
After the instruction has been executed on the operands, results may be stored back in memory.
The memory unit sees only a stream of memory addresses; it does not know how they are generated (by the instruction counter, indexing, indirection, literal addresses, and so on) or what they are for (instructions or data).
How CPU and Memory works ?
Main memory and the registers built into the processor itself are the only storage that the CPU can access directly.
There are machine instructions that take memory addresses as arguments, but none that take disk addresses. Therefore, any instructions in execution, and any data being used by the instructions, must be in one of these direct-access storage devices.
If the data are not in memory, they must be moved there before the CPU can operate on them.
Registers that are built into the CPU are generally accessible within one cycle of the CPU clock.
Most CPUs can decode instructions and perform simple operations on register contents at the rate of one or more operations per clock tick
The same cannot be said of main memory, which is accessed via a transaction on the memory bus. Completing a memory access may take many cycles of the CPU clock.
In such cases, the processor normally needs to stall, since it does not have the data required to complete the instruction that it is executing. This situation is intolerable because of the frequency of memory accesses.
The remedy is to add fast memory between the CPU and main memory. A memory buffer used to accommodate a speed differential called a Cache.
Function of the Base and limit register
Not only are we concerned with the relative speed of accessing physical memory, but we also must ensure correct operation to protect the operating system from access by user processes and, in addition, to protect user processes from one another.
This protection must be provided by the hardware.
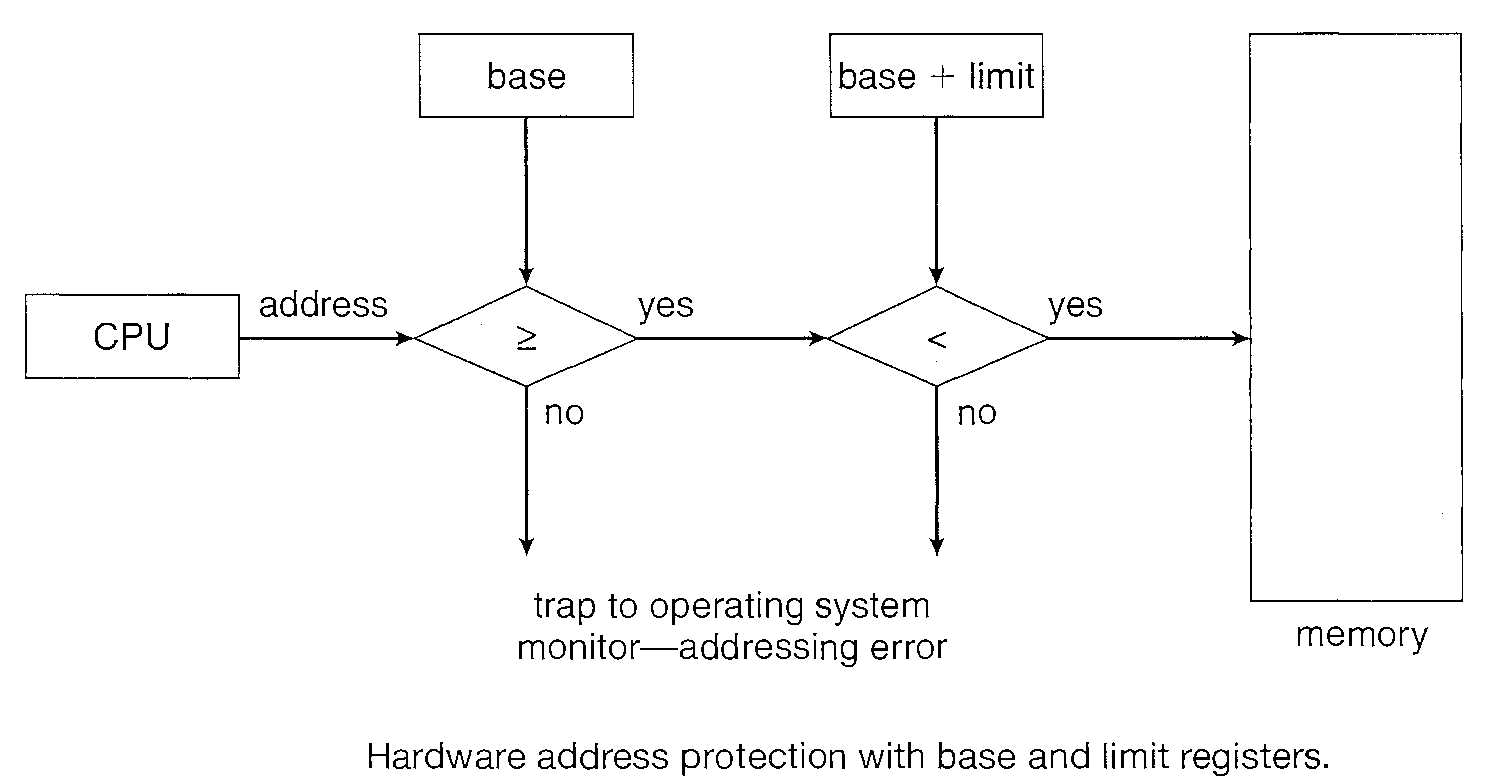
We first need to make sure that each process has a separate memory space. To do this, we need the ability to determine the range of legal addresses that the process may access and to ensure that the process can access only these legal addresses.
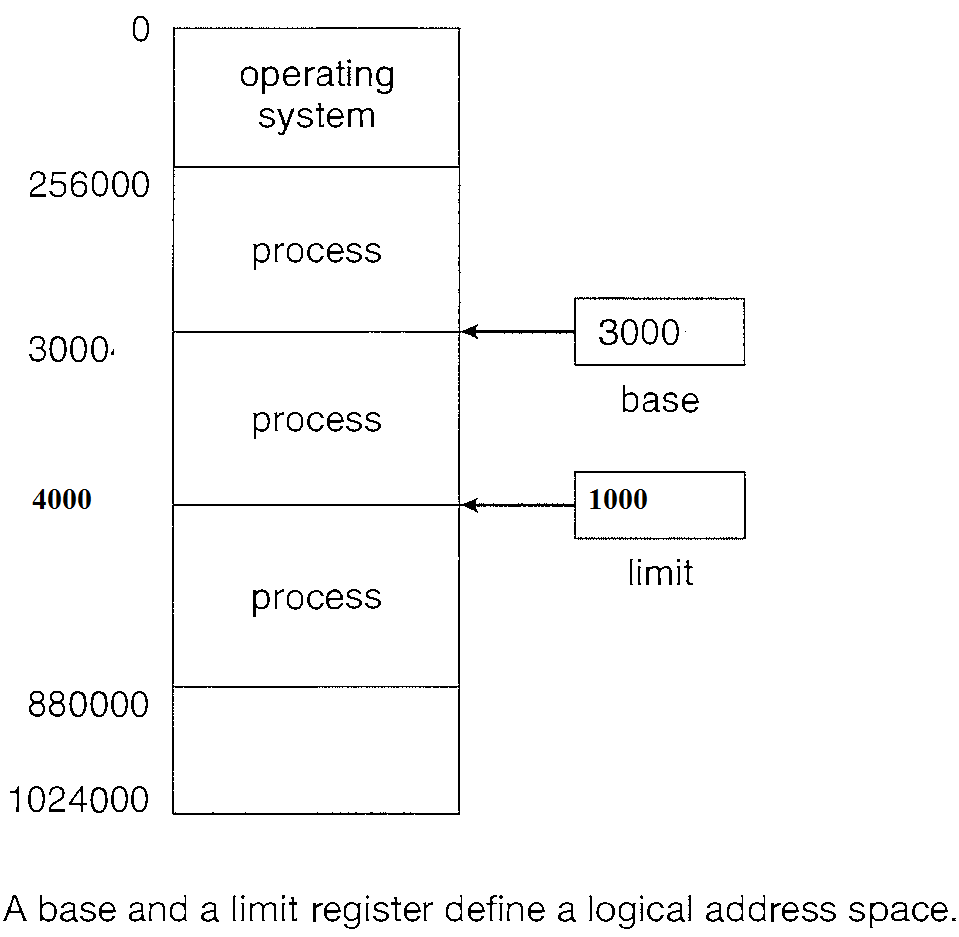
We can provide this protection by using two registers, usually a base and a limit.
The base holds the smallest legal physical memory address; the limit specifies the size of the range. For example, if the base register holds 3000 and the limit register is 1000, then the program can legally access all addresses from 3000 through 4000 (inclusive) i.e. 3000 + 1000.
Any attempt by a program executing in user mode to access operating-system memory or other users' memory results in a trap to the operating system, which treats the attempt as a fatal error
The base and limit registers can be loaded only by the operating system, which uses a special privileged instruction. Since privileged instructions can be executed only in kernel mode, and since only the operating system executes in kernel mode, only the operating system can load the base and limit registers.
This scheme allows the operating system to change the value of the registers but prevents user programs from changing the registers' contents.
The operating system, executing in kernel mode, is given unrestricted access to both operating system memory and users' memory. This provision allows the operating system to load users' programs into users' memory, to dump out those programs in case of errors, to access and modify parameters of system calls, and so on.
Logical versus Physical Address Space
An address generated by the CPU is commonly referred to as a Logical Address whereas an address seen by the memory unit-that is, the one loaded into the memory address register of the memory-is commonly referred to as a Physical Address.
The compile-time and load-time address-binding methods generate identical logical and physical addresses. However, the execution-time address binding scheme results in differing logical and addresses.
The set of all logical addresses generated by a program is Logical Address Space. The set of all physical addresses corresponding to these logical addresses is a Physical Address Space.
Thus, in_ the execution-time address-binding scheme, the logical and physical address spaces differ.
The run-time mapping from virtual to physical addresses is done by a hardware device called the Memory Management Unit.
Mapping of Logical Addresses to Physical Addresses
A simple MMU scheme that is a generalization of the base-register scheme described below :
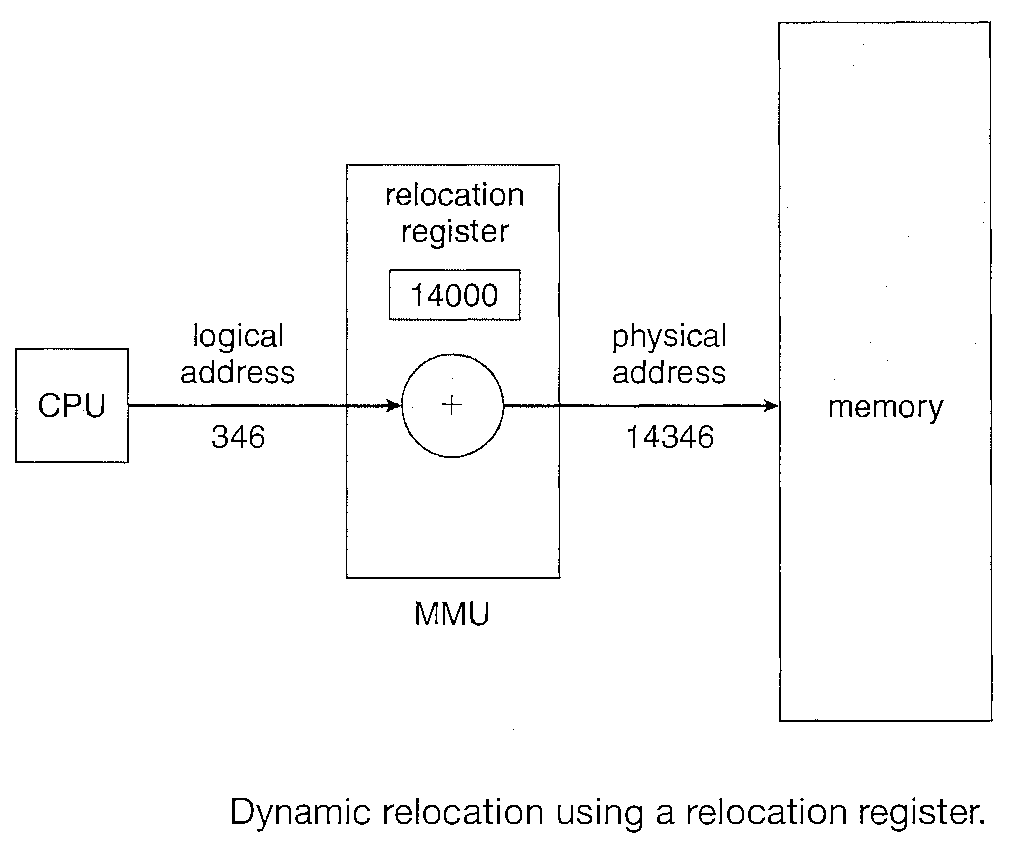
The base register is now called a Relocation Register. The value in the relocation register is added to every address generated by a user process at the time the address is sent to memory.
For example, if the base is at 14000, then an attempt by the user to address location 0 is dynamically relocated to location 14000; an access to location 346 is mapped to location 14346.
The user program never sees the real physical addresses. The program can create a pointer to location 346, store it in memory, manipulate it, and compare it with other addresses-all as the number 346.
Only when it is used as a memory address is it relocated relative to the base register.
The user program deals with logical addresses. The memory-mapping hardware converts logical addresses into physical addresses.
We now have two different types of addresses: logical addresses (in the range 0 to max) and physical addresses (in the range R + 0 to R + max for a base valueR).
The user generates only logical addresses and thinks that the process runs in locations 0 to max.
The user program generates only logical addresses and thinks that the process runs in locations 0 to max. However, these logical addresses must be mapped to physical addresses before they are used.
Dynamic Loading
It is necessary for the entire program and all data of a process to be in physical memory for the process to execute.
The size of a process has thus been limited to the size of physical memory. To obtain better memory-space utilization, we can use dynamic loading.
With dynamic loading, a routine is not loaded until it is called. All routines are kept on disk in a relocatable load format.
The main program is loaded into memory and is executed. When a routine needs to call another routine, the calling routine first checks to see whether the other routine has been loaded.
If it has not, the relocatable linking loader is called to load the desired routine into memory and to update the program's address tables to reflect this change. Then control is passed to the newly loaded routine.
The advantage of dynamic loading is that an unused routine is never loaded. This method is particularly useful when large amounts of code are needed to handle infrequently occurring cases, such as error routines.
In this case, although the total program size may be large, the portion that is used (and hence loaded) may be much smaller.
Dynamic loading does not require special support from the operating system.
It is the responsibility of the users to design their programs to take advantage of such a method. Operating systems may help the programmer, however, by providing library routines to implement dynamic loading.
Swapping
A process must be in memory to be executed.
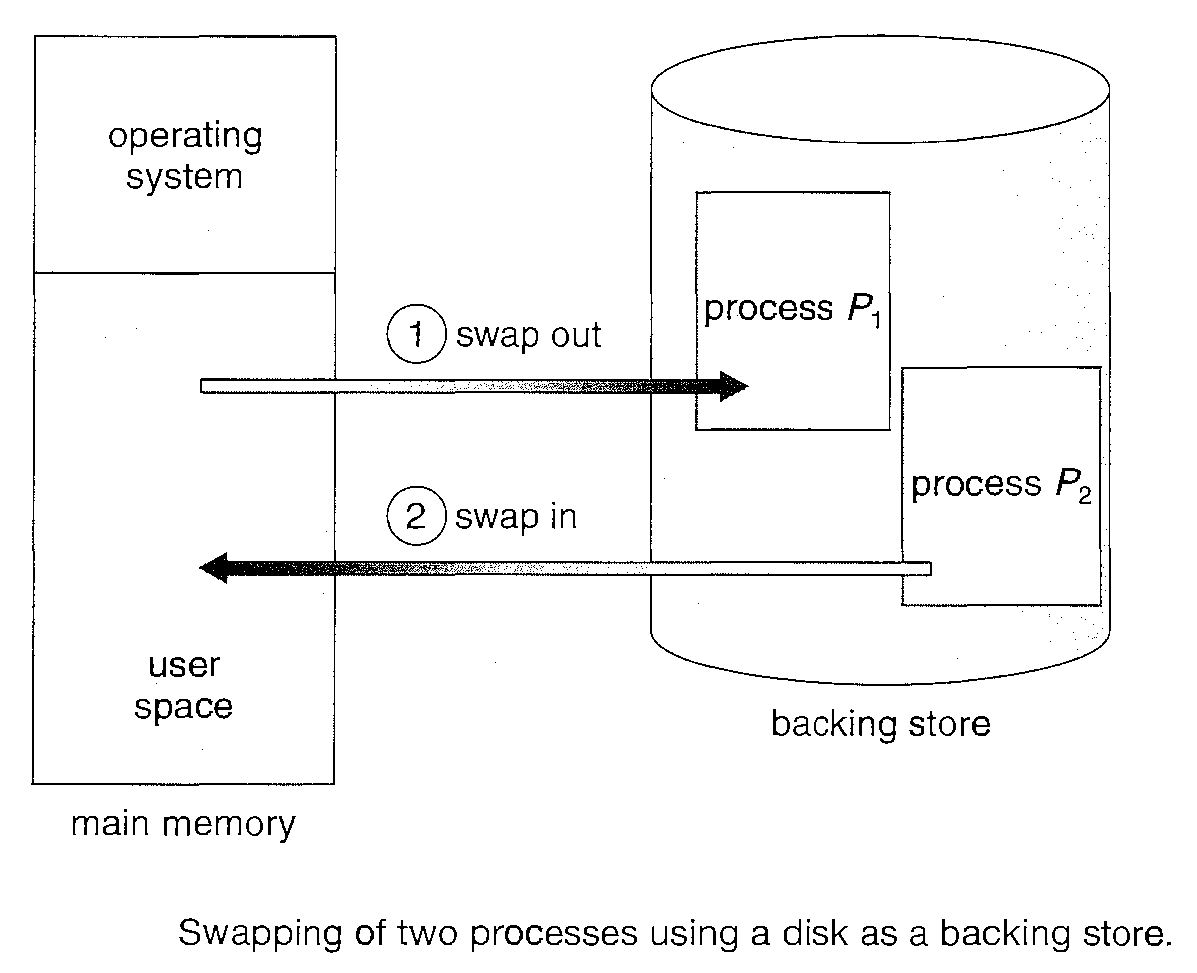
A process, however, can be "Swapped" temporarily out of memory to a "backing store" and then brought into memory for continued execution.
For example, assume a multi-programming environment with a round-robin CPU-scheduling algorithm. When a quantum expires, the memory manager will start to swap out the process that just finished and to swap another process into the memory space that has been freed
In the meantime, the CPU scheduler will allocate a time slice to some other process in memory.
When each process finishes its quantum, it will be swapped with another process.
Ideally, the memory manager can swap processes fast enough that some processes will be in memory, ready to execute, when the CPU scheduler wants to reschedule the CPU.
In addition, the quantum must be large enough to allow reasonable amounts of computing to be done between swaps.
Normally, a process that is swapped out will be swapped back into the same memory space it occupied previously.
This restriction is dictated by the method of address binding. If binding is done at assembly or load time, then the process cannot be easily moved to a different location.
If execution-time binding is being used, however, then a process can be swapped into a different memory space, because the physical addresses are computed during execution time.
Requirements of Swapping
Swapping requires a backing store. The backing store is commonly a fast disk. It must be large enough to accommodate copies of all memory images for all users, and it must provide direct access to these memory images.
The system maintains a "ready queue" consisting of all processes whose memory images are on the backing store or in memory and are ready to run.
Whenever the CPU scheduler decides to execute a process, it calls the dispatcher.
The dispatcher checks to see whether the next process in the queue is in memory.
If it is not, and if there is no free memory region, the dispatcher swaps out a process currently in memory and swaps in the desired process. It then reloads registers and transfers control to the selected process.
Context Switching time
Assume that the user process is 100 MB in size and the backing store is a standard hard disk with a transfer rate of 50MB per second.
The actual transfer of the 100-MB process to or from main memory takes 100 MB / 50 MB per second = 2 seconds.
Assuming an average latency of 8 milliseconds, the swap time is 2008 milliseconds. Since we must both swap out and swap in, the total swap time is about 4016 milliseconds.
Transfer Time
The total transfer time is directly proportional to the amount of memory swapped.
If we have a computer system with 4 GB of main memory and a resident operating system taking 1 GB, the maximum size of the user process is 3GB.
However, many user processes may be much smaller than this-say, 100 MB. A 100-MB process could be swapped out in 2 seconds, compared with the 60 seconds required for swapping 3 GB.
Clearly, it would be useful to know exactly how much memory a user process is using, not simply how much it might be using.
Then we would need to swap only what is actually used, reducing swap time. For this method to be effective, the user must keep the system informed of any changes in memory requirements.
Thus, a process with dynamic memory requirements will need to issue system calls (request memory and release memory) to inform the operating system of its changing memory needs.