Q.13 Let G=(V,E) be a directed graph where V is the set of vertices and E the set of edges. Then which one of the following graphs has the same strongly connected components as G ?
View Answer
Ans .
B
Explanation : If we reverse directions of all arcs in a graph, the new graph has same set of strongly connected components as the original graph. Se http://www.geeksforgeeks.org/strongly-connected-components/ for more details.
2 )
View Answer
Ans .
C
Explanation : Depth First Search of a graph takes O(m+n) time when the graph is represented using adjacency list. In adjacency matrix representation, graph is represented as an "n x n" matrix. To do DFS, for every vertex, we traverse the row corresponding to that vertex to find all adjacent vertices (In adjacency list representation we traverse only the adjacent vertices of the vertex). Therefore time complexity becomes O(n2 )
View Answer
Ans .
A
Explanation :
We can find the subtree with 4 nodes in O(n) time. Following can be a simple approach.
View Answer
Ans .
C
Explanation : The graph doesn't contain any cycle, so there exist topological ordering. P and S must appear before R and Q because there are edges from P to R and Q, and from S to R and Q. See Topological Ordering for more details.
View Answer
Ans .
C
Explanation : When first element or last element is chosen as pivot, Quick Sort's worst case occurs for the sorted arrays. In every step of quick sort, numbers are divided as per the following recurrence. T(n) = T(n-1) + O(n)
View Answer
Ans .
C
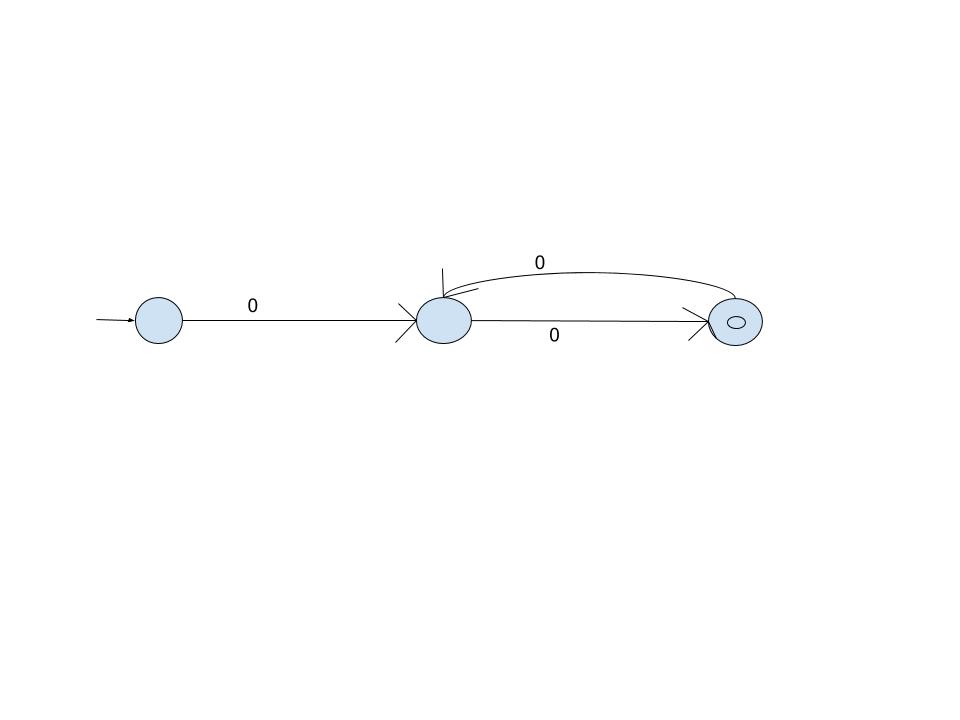
Explanation : (A) L = {a n b n |n >= 0} is not regular because there does not exists a finite automaton that can
View Answer
Ans .
A
Explanation : So, q0, q1 and q2 are reachable states for the input string 0011, but q3 is not. So, option (A) is answer.
View Answer
Ans .
16383
Explanation : 1 Word = 32 bits
View Answer
Ans .
D
Explanation : A) A basic block is a sequence of instructions where control enters the sequence at the beginning and exits at the end is TRUE. (B) Available expression analysis can be used for common subexpression elimination is TRUE. Available expressions is an analysis algorithm that determines for each point in the program the set of expressions that need not be recomputed. Available expression analysis is used to do global common subexpression elimination (CSE). If an expression is available at a point, there is no need to re-evaluate it. (C)Live variable analysis can be used for dead code elimination is TRUE. (D) x = 4 ∗ 5 => x = 20 is an example of common subexpression elimination is FALSE. Common subexpression elimination (CSE) refers to compiler optimization replaces identical expressions (i.e., they all evaluate to the same value) with a single variable holding the computed value when it is worthwhile to do so. Below is an example
View Answer
Ans .
B
Explanation : Waterfall Model: We can not go back in previous project phase as soon as as we proceed to next phase ,So inflexible
View Answer
Ans .
C
Explanation : In Shortest-Seek-First algorithm, request closest to the current position of the disk arm and head is handled first. In this question, the arm is currently at cylinder number 100. Now the requests come in the queue order for cylinder numbers 30, 85, 90, 100, 105, 110, 135 and 145. The disk will service that request first whose cylinder number is closest to its arm. Hence 1st serviced request is for cylinder no 100 ( as the arm is itself pointing to it ), then 105, then 110, and then the arm comes to service request for cylinder 90. Hence before servicing request for cylinder 90, the disk would had serviced 3 requests. Hence option C.
View Answer
Ans .
D
Explanation :
User level thread Kernel level thread
User thread are implemented by user processes. kernel threads are implemented by OS.
OS doesn’t recognized user level threads.
Kernel threads are recognized by OS.
Implementation of User threads is easy.
Implementation of Kernel thread is complicated.
Context switch time is less. Context switch time is more.
Context switch requires no hardware support.
Hardware support is needed.
If one user level thread perform blocking operation then entire process will be blocked. If one kernel thread perform blocking operation then another thread can continue execution.
Example : Java thread, POSIX threads.
Example : Window Solaris.
View Answer
Ans .
B
Explanation : All attributes can be derived from {E, F, H} To solve these kind of questions that are frequently asked in GATE paper, try to solve it by using shortcuts so that enough amount of time can be saved. Fist Method: Using the given options try to obtain closure of each options. The solution is the one that contains R and also minimal Super Key, i.e Candidate Key.
View Answer
Ans .
D
Explanation : S1: A foreign key declaration can always
View Answer
Ans .
C
Explanation : RSA – It is an algorithm used to encrypt and decrypt messages.
View Answer
Ans .
C
Explanation : RSA – It is an algorithm used to encrypt and decrypt messages.
View Answer
Ans .
C
Explanation :
Current size of congestion window in terms of number of segments
= (Size in Bytes)/(Maximum Segment Size)
= 32KB / 2KB
= 16 MSS
When timeout occurs, in TCP's Slow Start algorithm, threshold is
reduced to half which is 16KB or 8MSS. Also, slow start phase begins
where congestion window is increased twice.
So from 1MSS to 8 MSS window size will grow exponentially.
Congestion window becomes 2MSS after one RTT and becomes 4MSS after
2 RTTs and 8MSS after 3 RTTs. At 8MSS, threshold is reached and
congestion avoidance phase begins. In congestion avoidance phase,
window is increased linearly. So to cover from 8MSS to 16MSS, it needs
8 RTTs
Together, 11RTTs are needed (3 in slow start phase and 8 in congestion
avoidance phase).
View Answer
Ans .
C
Explanation :
Transmission delay = Frame Size/bandwidth
= (1*8*10^3)/(1.5 * 10^6)=5.33ms
Propagation delay = 50ms
Efficiency = Window Size/(1+2a) = .6
a = Propagation delay/Transmission delay
So, window size = 11.856(approx)
min sequence number = 2*window size = 23.712
bits required in Min sequence number = log2(23.712)
Answer is 4.56
Ceil(4.56) = 5
View Answer
Ans .
D
Explanation : In option D, there is no interleaving of operations. The option D has first all operations of transaction 2, then 3 and finally 1 There can not be any conflict as it is a serial schedule with sequence 2 --> 3 -- > 1
View Answer
Ans .
A
Explanation :
S1: Every table with two single-valued
attributes is in 1NF, 2NF, 3NF and BCNF.
A relational schema R is in BCNF iff in Every non-trivial Functional Dependency X->Y, X is Super Key. If we can prove the relation is in BCNF then by default it would be in 1NF, 2NF, 3NF also. Let R(AB) be a two attribute relation, then
If {A->B} exists then BCNF since {A}+ = AB = R
If {B->A} exists then BCNF since {B}+ = AB = R
If {A->B,B->A} exists then BCNF since A and B both are Super Key now.
If {No non trivial Functional Dependency} then default BCNF.
Hence it's proved that a Relation with two single - valued attributes is in BCNF hence its also in 1NF, 2NF, 3NF. Hence S1 is true.
S2: AB->C, D->E, E->C is a minimal cover for
the set of functional dependencies
AB->C, D->E, AB->E, E->C.
As we know Minimal Cover is the process of eliminating redundant Functional Dependencies and Extraneous attributes in Functional Dependency Set. So each dependency of F = {AB->C, D->E, AB->E, E->C} should be implied in minimal cover. As we can see AB->E is not covered in minimal cover since {AB}+ = ABC in the given cover {AB->C, D->E, E->C} Hence, S2 is false.
View Answer
Ans .
B
Explanation :
This is the current safe state.
AVAILABLE
X=3, Y=2, Z=2
MAX
ALLOCATION
X Y Z
X Y Z
P0
8 4 3
0 0 1
P1
6 2 0
3 2 0
P2
3 3 3
2 1 1
Now, if the request REQ1 is permitted, the state would become :
AVAILABLE
X=3, Y=2, Z=0
MAX
ALLOCATION
NEED
X Y Z
X Y Z
X Y Z
P0
8 4 3
0 0 3
8 4 0
P1
6 2 0
3 2 0
3 0 0
P2
3 3 3
2 1 1
1 2 2
Now, with the current availability, we can service the need of P1. The state would become :
AVAILABLE
X=6, Y=4, Z=0
MAX
ALLOCATION
NEED
X Y Z
X Y Z
X Y Z
P0
8 4 3
0 0 3
8 4 0
P1
6 2 0
3 2 0
0 0 0
P2
3 3 3
2 1 1
1 2 2
With the resulting availability, it would not be possible to service the need of either P0 or P2, owing to lack of Z resource.
Therefore, the system would be in a deadlock.
⇒ We cannot permit REQ1.
Now, at the given safe state, if we accept REQ2 :
AVAILABLE
X=1, Y=2, Z=2
MAX
ALLOCATION
NEED
X Y Z
X Y Z
X Y Z
P0
8 4 3
0 0 1
8 4 2
P1
6 2 0
5 2 0
1 0 0
P2
3 3 3
2 1 1
1 2 2
With this availability, we service P1 (P2 can also be serviced). So, the state is :
AVAILABLE
X=7, Y=4, Z=2
MAX
ALLOCATION
NEED
X Y Z
X Y Z
X Y Z
P0
8 4 3
0 0 1
8 4 2
P1
6 2 0
5 2 0
0 0 0
P2
3 3 3
2 1 1
1 2 2
With the current availability, we service P2. The state becomes :
AVAILABLE
X=10, Y=7, Z=5
MAX
ALLOCATION
NEED
X Y Z
X Y Z
X Y Z
P0
8 4 3
0 0 1
8 4 2
P1
6 2 0
5 2 0
0 0 0
P2
3 3 3
2 1 1
0 0 0
Finally, we service P0. The state now becomes :
AVAILABLE
X=18, Y=11, Z=8
MAX
ALLOCATION
NEED
X Y Z
X Y Z
X Y Z
P0
8 4 3
0 0 1
0 0 0
P1
6 2 0
5 2 0
0 0 0
P2
3 3 3
2 1 1
0 0 0
The state so obtained is a safe state. ⇒ REQ2 can be permitted.
So, only REQ2 can be permitted.
Hence, B is the correct choice.
Please comment below if you find anything wrong in the above post.
View Answer
Ans .
A
Explanation :
Turn around time of a process is total time between submission of the process and its completion. Shortest remaining time (SRT) scheduling algorithm selects the process for execution which has the smallest amount of time remaining until completion.
Solution:
Let the processes be A, ,C,D and E. These processes will be executed in following order. Gantt chart is as follows:
First 3 sec, A will run, then remaining time A=3, B=2,C=4,D=6,E=3 Now B will get chance to run for 2 sec, then remaining time. A=3, B=0,C=4,D=6,E=3
Now A will get chance to run for 3 sec, then remaining time. A=0, B=0,C=4,D=6,E=3 By doing this way, you will get above gantt chart.
Scheduling table:
As we know, turn around time is total time between submission of the process and its completion. i.e turn around time=completion time-arrival time. i.e. TAT=CT-AT
Turn around time of A = 8 (8-0)
Turn around time of B = 2 (5-3)
Turn around time of C = 7 (12-5)
Turn around time of D = 14 (21-7)
Turn around time of E = 5 (15-10)
Average turn around time is (8+2+7+14+5)/5 = 7.2.
Answer is 7.2.
Reference:
https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/5_CPU_Scheduling.html
This solution is contributed by
Nitika Bansal
Alternate Explanatio:
After drawing Gantt Chart
Completion Time for processes A, B, C, D
and E are 8, 5, 12, 21 and 15 respectively.
Turnaround Time = Completion Time - Arrival Time
View Answer
Ans .
C
Explanation :
In optimal page replacement replacement policy, we replace the place which is not used for longest duration in future.
Given three page frames.
Reference string is 1, 2, 3, 4, 2, 1, 5, 3, 2, 4, 6
Initially, there are three page faults and entries are
1 2 3
Page 4 causes a page fault and replaces 3 (3 is the longest
distant in future), entries become
1 2 4
Total page faults = 3+1 = 4
Pages 2 and 1 don't cause any fault.
5 causes a page fault and replaces 1, entries become
5 2 4
Total page faults = 4 + 1 = 5
3 causes a page fault and replaces 1, entries become
3 2 4
Total page faults = 5 + 1 = 6
3, 2 and 4 don't cause any page fault.
6 causes a page fault.
Total page faults = 6 + 1 = 7
View Answer
Ans .
D
Explanation : The question is asked with respect to the symbol ' < ' which is not present in the given canonical set of items. Hence it is neither a shift-reduce conflict nor a reduce-reduce conflict on symbol '<'. Hence D is the correct option. But if the question would have asked with respect to the symbol ' > ' then it would have been a shift-reduce conflict.
View Answer
Ans .
C
Explanation : A) It is possible if L itself is NOT RE. Then L' will also not be RE. B) Suppose there is a language such that turing machine halts on the input. The given language is RE but not recursive and its complement is NOT RE. C) This is not possible because if we can write enumeration procedure for both languages and it's complement, then the language becomes recursive. D) It is possible because L is closed under complement if it is recursive. Thus, C is the correct choice.
View Answer
Ans .
B
Explanation :
I) 0*1(1+00*1)*
II) 0*1*1+11*0*1
III) (0+1)*1
(I) and (III) represent DFA.
(II) doesn't represent as the DFA accepts strings like 11011,
but the regular expression doesn't accept.
View Answer
Ans .
B
Explanation :
There are 5 bags numbered 1 to 5.
We don't know how many bags contain 10 gm and
11 gm coins.
We only know that the total weights of coins is 323.
Now the idea here is to get 3 in the place of total
sum's unit digit.
Mark no 1 bag as having 11 gm coins.
Mark no 2 bag as having 10 gm coins.
Mark no 3 bag as having 11 gm coins.
Mark no 4 bag as having 11 gm coins.
Mark no 5 bag as having 10 gm coins.
Note: The above marking is done after getting false
results for some different permutations, the permutations
which were giving 3 in the unit place of the total sum.
Now, we have picked 1, 2, 4, 8, 16 coins respectively
from bags 1 to 5.
Hence total sum coming from each bag from 1 to 5 is 11,
20, 44, 88, 160 gm respectively.
For the above combination we are getting 3 as unit digit
in sum.
Lets find out the total sum, it's 11 + 20 + 44 + 88 + 160 = 323.
So it's coming right.
Now 11 gm coins containing bags are 1, 3 and 4.
Hence, the product is : 1 x 3 x 4 = 12.
 Option B : Hence This option is Correct, because L is Regular but not 0+, as we proved above.
Option B : Hence This option is Correct, because L is Regular but not 0+, as we proved above.