Introduction to Pandas
# Dependency needed to install file
!pip install xlrd
# Import required library
import pandas as pd
After the import command, we now have access to a large number of pre-built classes and functions.
This assumes the library is installed; . One way pandas allows you to work with data is a dataframe.
Let's go through the process to go from a comma separated values (.csv) file to a dataframe.
This variable csv_path stores the path of the .csv, that is used as an argument to the read_csv function.
The result is stored in the object df, this is a common short form used for a variable referring to a Pandas dataframe.
# Read data from CSV file
csv_path = 'https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/PY0101EN/Chapter%204/Datasets/TopSellingAlbums.csv'
df = pd.read_csv(csv_path)
We can use the method head() to examine the first five rows of a dataframe:
# Print first five rows of the dataframe
df.head()
We use the path of the excel file and the function read_excel. The result is a data frame as before:
# Read data from Excel File and print the first five rows
xlsx_path = 'https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/PY0101EN/Chapter%204/Datasets/TopSellingAlbums.xlsx'
df = pd.read_excel(xlsx_path)
df.head()
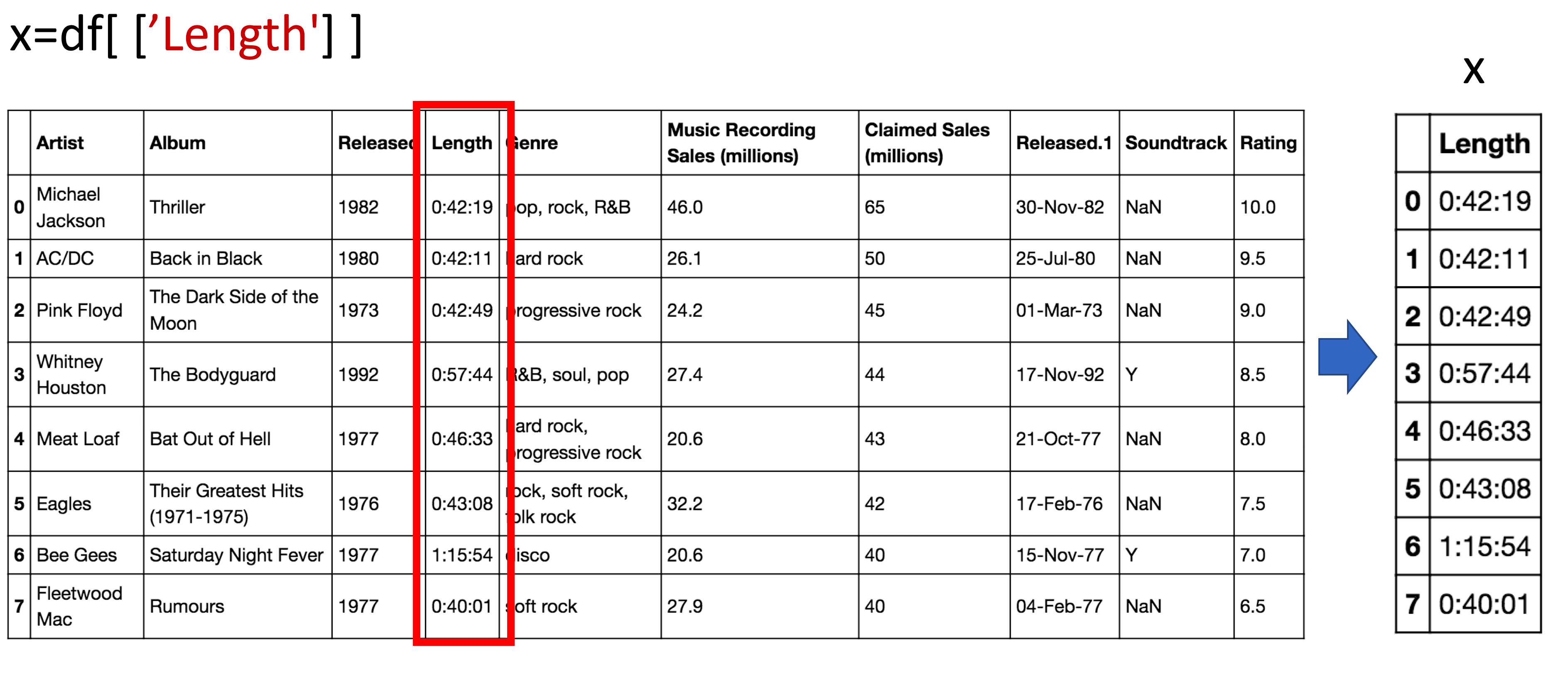
We can access the column Length and assign it a new dataframe x:
# Access to the column Length
x = df[['Length']]
x
The process is shown in the figure:
Viewing Data and Accessing Data You can also get a column as a series. You can think of a Pandas series as a 1-D dataframe. Just use one bracket:
# Get the column as a series
x = df['Length']
x
You can also get a column as a dataframe. For example, we can assign the column Artist:
# Get the column as a dataframe
x = type(df[['Artist']])
x
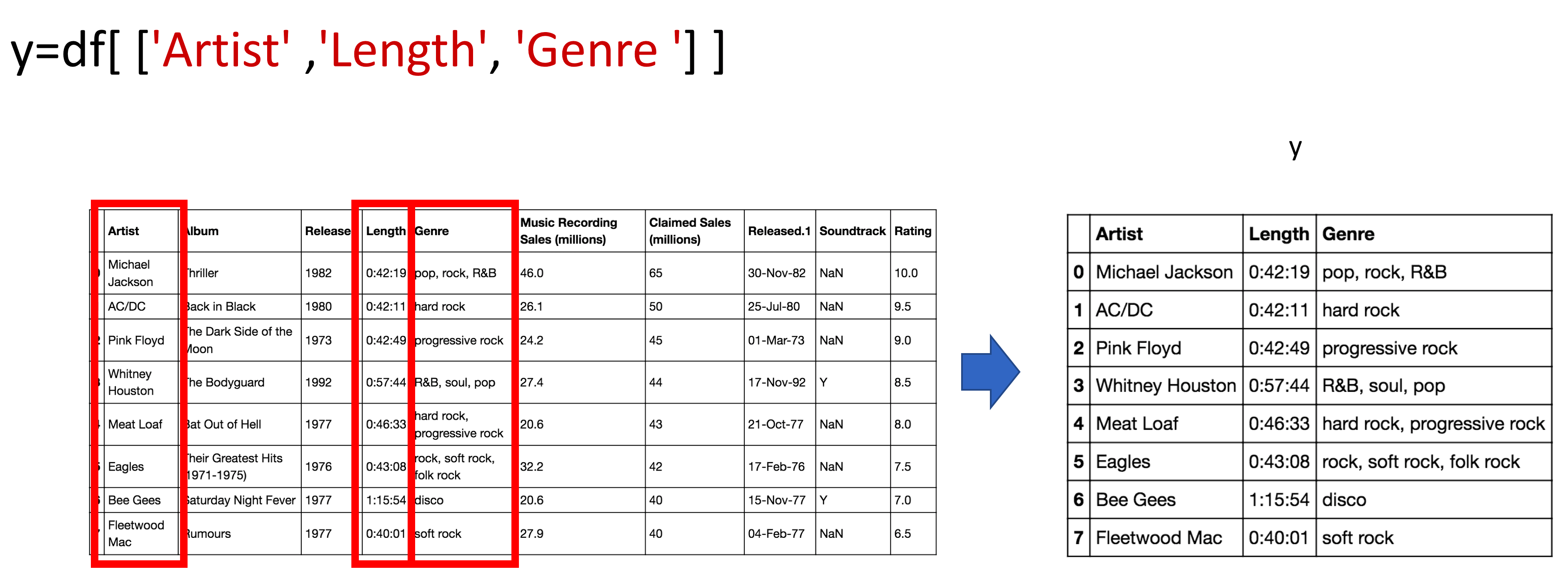
You can do the same thing for multiple columns; we just put the dataframe name, in this case, df, and the name of the multiple column headers enclosed in double brackets. The result is a new dataframe comprised of the specified columns:
# Access to multiple columns
y = df[['Artist','Length','Genre']]
y
The process is shown in the figure:
One way to access unique elements is the iloc method, where you can access the 1st row and the 1st column as follows:
# Access the value on the first row and the first column
df.iloc[0, 0]
You can access the 2nd row and the 1st column as follows:
# Access the value on the second row and the first column
df.iloc[1,0]
You can access the 1st row and the 3rd column as follows:
# Access the value on the first row and the third column
df.iloc[0,2]
You can access the column using the name as well, the following are the same as above:
# Access the column using the name
df.loc[0, 'Artist']
# Access the column using the name
df.loc[1, 'Artist']
# Access the column using the name
df.loc[0, 'Released']
# Access the column using the name
df.loc[1, 'Released']
You can perform slicing using both the index and the name of the column:
# Slicing the dataframe
df.iloc[0:2, 0:3]
# Slicing the dataframe using name
df.loc[0:2, 'Artist':'Released']