Command Line Tools for Compressed Files
When working with compressed files, many standard commands cannot be used directly.
For many commonly-used file and text manipulation programs, there is also a version especially designed to work directly with compressed files.
These associated utilities have the letter "z" prefixed to their name.
For example, we have utility programs such as zcat, zless, zdiff and zgrep.
Here is a table listing some z family commands:
Note that if you run zless on an uncompressed file, it will still work and ignore the decompression stage.
There are also equivalent utility programs for other compression methods besides gzip.
For example, we have bzcat and bzless associated with bzip2, and xzcat and xzless associated with xz.
| Command | Description |
|---|---|
| $ zcat compressed-file.txt.gz | To view a compressed file |
| $ zless somefile.gz or $ zmore somefile.gz | To page through a compressed file |
| $ zgrep -i less somefile.gz | To search inside a compressed file |
| $ zdiff file1.txt.gz file2.txt.gz | To compare two compressed files |
Introduction to sed and awk
It's very common to look at a file and extract some of the contents in a special way.
sed and awk are two very commonly used tools for that task.
Now, it's possible to do anything you do with sed and awk or other texts utilities using comprehensive scripting languages; in particular Python, which is very popular these days and Perl, rather than use sed and awk.
However, Python or Perl are rather heavy in the sense that the binaries are complicated, there's a lot of infrastructure.
sed and awk can be very small programs.
There are situations in which you don't want a large program, and so sed and awk will always be around, especially for people who have been working in the Unix world for a long time where they'd been very standard tools.
One particular case is such as when you're booting the system and time is really important, you don't want to have to load something as complicated as a language like Perl and Python when you have these small programs like sed and awk.
Otherwise, boot may take longer.
sed is a stream editor, it takes an input file or an input stream that's in a pipe.
It puts it in, what's called, a working stream, where is manipulated and the output stream is the resolve.
In that manipulation phase you can substitute strings, you can eliminate certain strings, and do various kinds of operations, we're going to explain in detail later.
So think of it as a filter, it's a filter.
awk is really not a filter, awk is an extraction device.
Its name just comes from the name of the three authors and the initials of their last names.
And it's very old, been around since the early 1970's.
Here you, in a very logical way, extract some of the contents specially a files which have columns.
You work on a column basis, extract the contents and do various operations on them.
sed Command Syntax and Basic Operations
You can invoke sed using commands like those listed in the accompanying table.
The -e command option allows you to specify multiple editing commands simultaneously at the command line.
It is unnecessary if you only have one operation invoked.
Now that you know that you can perform multiple editing and filtering operations with sed. The table explains some basic operations, where pattern is the current string and replace_string is the new string:
You must use the -i option with care, because the action is not reversible. It is always safer to use sed without the –i option and then replace the file yourself, as shown in the following example:
| Command | Usage |
|---|---|
| sed -e command <filename> | Specify editing commands at the command line, operate on file and put the output on standard out (e.g. the terminal) |
| sed -f scriptfile <filename> | Specify a scriptfile containing sed commands, operate on file and put output on standard out |
| Command | Usage |
|---|---|
| sed s/pattern/replace_string/ file | Substitute first string occurrence in every line |
| sed s/pattern/replace_string/g file | Substitute all string occurrences in every line |
| sed 1,3s/pattern/replace_string/g file | Substitute all string occurrences in a range of lines |
| sed -i s/pattern/replace_string/g file | Save changes for string substitution in the same file |
$ sed s/pattern/replace_string/g file1 > file2
The above command will replace all occurrences of pattern with replace_string in file1 and move the contents to file2.
The contents of file2 can be viewed with cat file2. If you approve, you can then overwrite the original file with mv file2 file1.
Example: To convert 01/02/… to JAN/FEB/…
sed -e 's/01/JAN/' -e 's/02/FEB/' -e 's/03/MAR/' -e 's/04/APR/' -e 's/05/MAY/' \
-e 's/06/JUN/' -e 's/07/JUL/' -e 's/08/AUG/' -e 's/09/SEP/' -e 's/10/OCT/' \
-e 's/11/NOV/' -e 's/12/DEC/'
sed Command demo
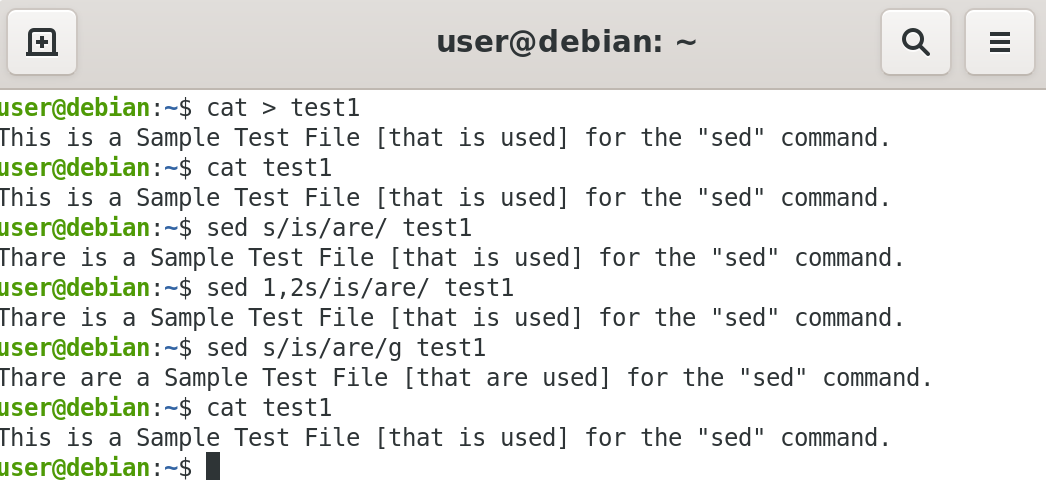
To create a new file, test1 at the command prompt, type: "cat > test1", and press Enter.
Type the following sentences: "This is a Sample Test File [that is used] for the "sed" command.
The sed command is used to edit contents in a file. For example, the sed command is used to replace words in a line or file.", and press the Enter key, and press Ctrl+D to save the file.
You will return to the command prompt. To substitute first string occurrence in a line, type: "sed s/is/are/ test1", and press the Enter key.
The first occurrenceof the word "is", is replaced with "are".
To view the file test1, type: "cat test1", and press the Enter key.
The file test1 is displayed at the command prompt. The contents of test1 are not altered, because we don't save the results of the "sed" command.
To substitute string occurrence globally on a range of lines, type: "sed 1,2s/is/are/g test1", and press the Enter key.
All occurrences of the word "is" between line one and two are replaced with "are".
To view the file test1, type: "cat test1", and press the Enter key.
The file test1 is displayed at the command prompt.
The contents of test1 are not altered, because we don't save the results of the "sed" command.
To substitute string occurrence globally, type: "sed s/is/are/g test1", and press the Enter key.
All occurrences of the word "is" in the file test1, are replaced with "are".
To view the file test1, type: "cat test1", and press the Enter key.
The file test1 is displayed at the command prompt.
The contents of test1 are not altered, because we don't save the results of the "sed" command.
awk
awk is invoked as shown in the following screenshot:
As with sed, short awk commands can be specified directly at the command line, but a more complex script can be saved in a file that you can specify using the -f option.
The table below explains the basic tasks that can be performed using awk.
The input file is read one line at a time, and, for each line, awk matches the given pattern in the given order and performs the requested action.
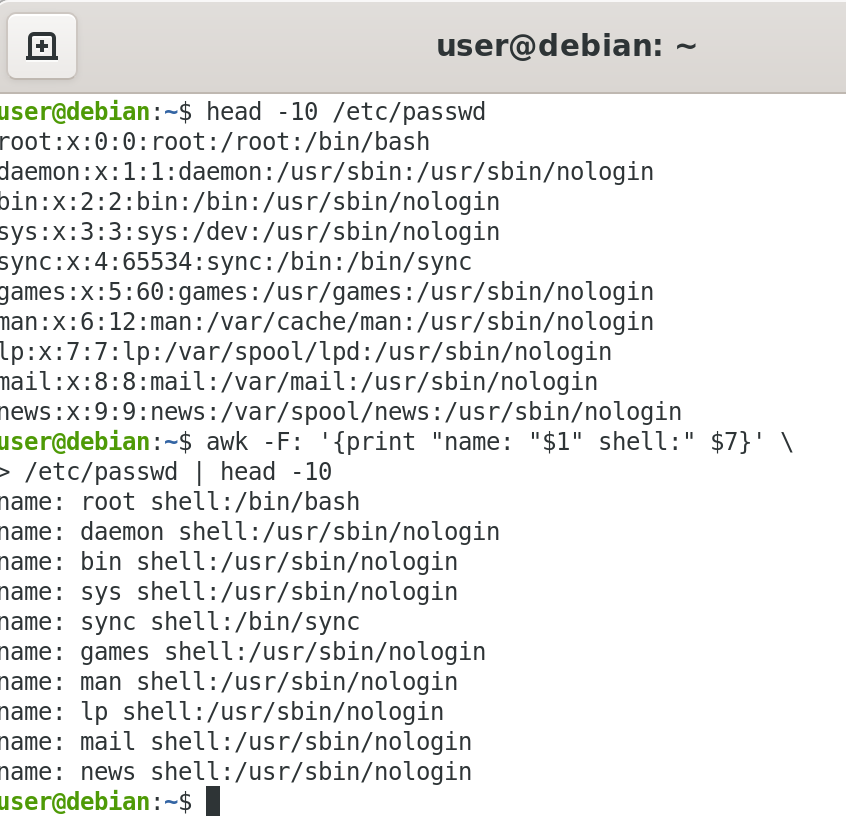
The -F option allows you to specify a particular field separator character. For example, the /etc/passwd file uses ":" to separate the fields, so the -F: option is used with the /etc/passwd file.
The command/action in awk needs to be surrounded with apostrophes (or single-quote (')). awk can be used as follows:
| Command | <header> |
|---|---|
| awk 'command' file | Specify a command directly at the command line |
| awk -f scriptfile file | Specify a file that contains the script to be executed |
| Command | Usage |
|---|---|
| awk '{ print $0 }' /etc/passwd | Print entire file |
| awk -F: '{ print $1 }' /etc/passwd | Print first field (column) of every line, separated by a space |
| awk -F: '{ print $1 $7 }' /etc/passwd | Print first and seventh field of every line |