File Manipulation Utilities in linux
In particular, the "sort" command is kind of obvious.
You can sort files in all sorts of ways and put the output in another file.
There are many options to sort that can control the "sort".
"uniq" does exactly what its name says.
It'll look at a file and remove duplicate lines and replace them with single lines.
"paste" and "join" work with files that have columns in them and let you reorganize them into a new file, which joins the contents of the files.
And "paste" and "join" are a little bit different
And "split" lets you split up a file into smaller pieces.
In case you need to transmit them and you're worried that piece five will not get through, you can separately send it, etc.
File Manipulation Utilities in linux - sort
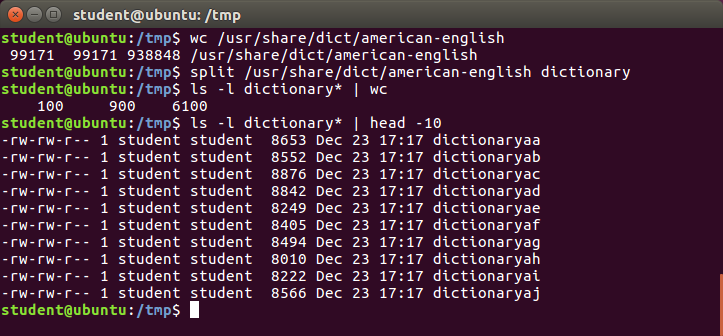
sort is used to rearrange the lines of a text file either in ascending or descending order, according to a sort key.
You can also sort by particular fields of a file.
The default sort key is the order of the ASCII characters (i.e. essentially alphabetically).
sort can be used as follows:
When used with the -u option, sort checks for unique values after sorting the records (lines).
It is equivalent to running uniq (which we shall discuss) on the output of sort.
| Syntax | Usage |
|---|---|
| sort <filename> | Sort the lines in the specified file, according to the characters at the beginning of each line |
| cat file1 file2 | sort | Combine the two files, then sort the lines and display the output on the terminal |
| sort -r <filename> | Sort the lines in reverse order |
| sort -k 3 <filename> | Sort the lines by the 3rd field on each line instead of the beginning |
File Manipulation Utilities in linux - uniq
uniqremoves duplicate consecutive lines in a text file and is useful for simplifying the text display.
Because uniqrequires that the duplicate entries must be consecutive, one often runs sort first and then pipes the output into uniq; if sort is used with the -u option, it can do all this in one step.
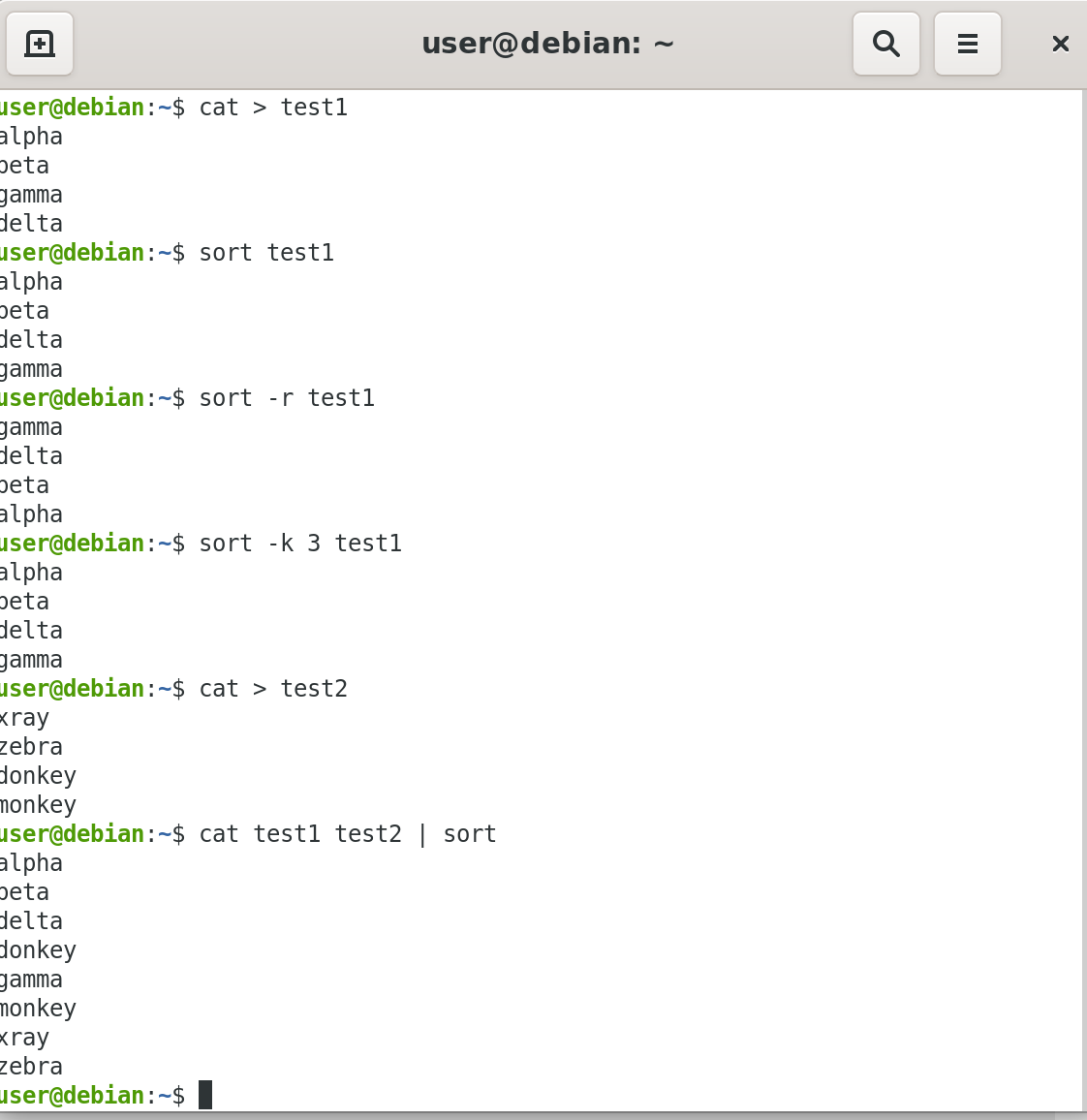
To remove duplicate entries from multiple files at once, use the following command:
sort file1 file2 | uniq > file3
sort -u file1 file2 > file3
To count the number of duplicate entries, use the following command:
uniq -c filename
Introduction to paste, join, and split
Suppose you have some files which contain either some common or related information, and you'd like to construct some new files that contain all the information.
You can do that with "paste" or "join".
And with "split" we can take a long file and we can make it into smaller, more manageable pieces.
So first, let's consider the example where we have two files that have columns in them and we would like to produce a file that has all the columns in one file.
We can do that with "paste". So, "paste" simply will take these columns and append them together to make a file with three columns.
It has some options... the delimiter between the columns doesn't have to be a space, it could be something else: a tab perhaps, or a colon, or a comma
So, you can specify that, so it knows what the different columns are.
You can also do this "paste" operation in a horizontal format, instead of a vertical format, as we have shown.
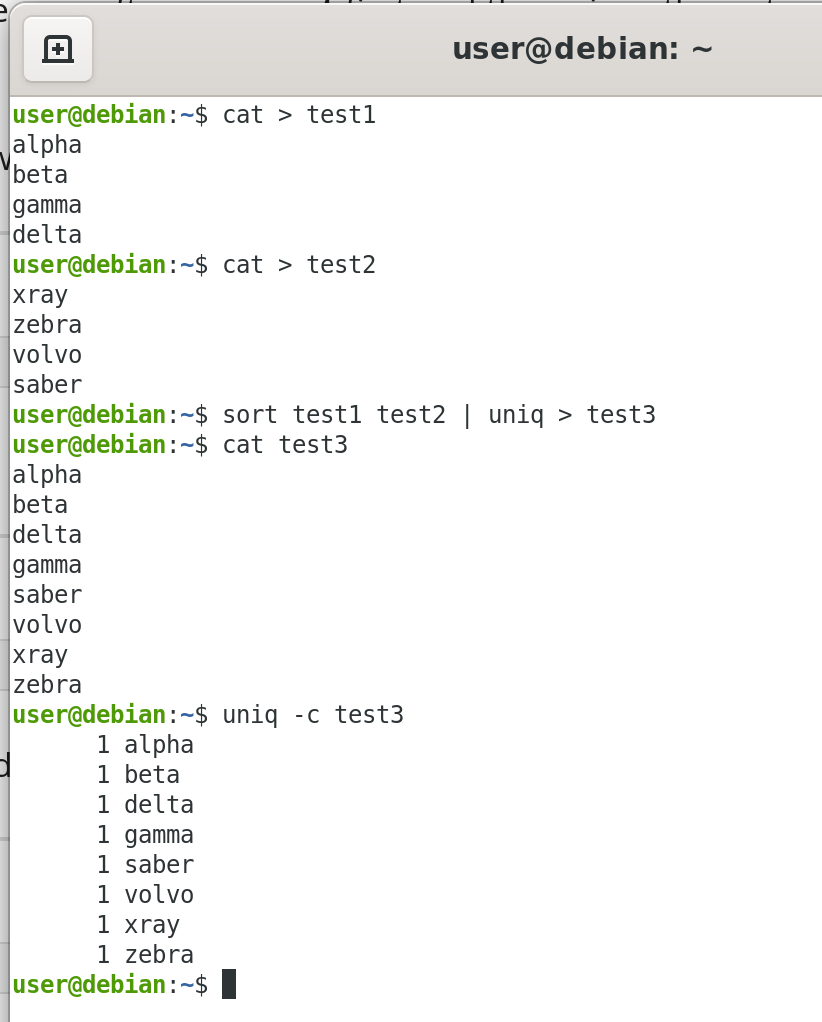
If there is a duplication of columns between the first file and the second file. They both have the phone numbers - a common field.
The first one has the names and the second one has the place, the town name. We'd like to produce a file which doesn't have a duplicated column of phone numbers.
If we use "paste" we would just get that.
So, we can do that with "join" and it's similar, the syntax is similar to "paste", but it doesn't have the duplicated columns.
Finally, suppose we have a very long file, maybe with millions of lines and we need to transmit it over the network, let's say. Then, we'd want to break it up into smaller segments. So that, if one of them is corrupted, we don't have to send the whole thing over again, or, if one of them doesn't get through.
Or, if you need to edit the file and you don't want to have to load a huge file to memory to do an editor, you can break it into smaller pieces, and that you can do with "split" command.
It's basically pretty simple. You just say the name of the file as an argument to "split", and you can give arguments that control what the names are, how big the segments are, etc.
paste can be used to combine fields (such as name or phone number) from different files, as well as combine lines from multiple files.
For example, line one from file1 can be combined with line one of file2, line two from file1 can be combined with line two of file2, and so on.
To paste contents from two files, you can do:
$ paste file1 file2
The syntax to use a different delimiter is as follows:
$ paste -d, file1 file2
Common delimiters are 'space', 'tab', '|', 'comma', etc.
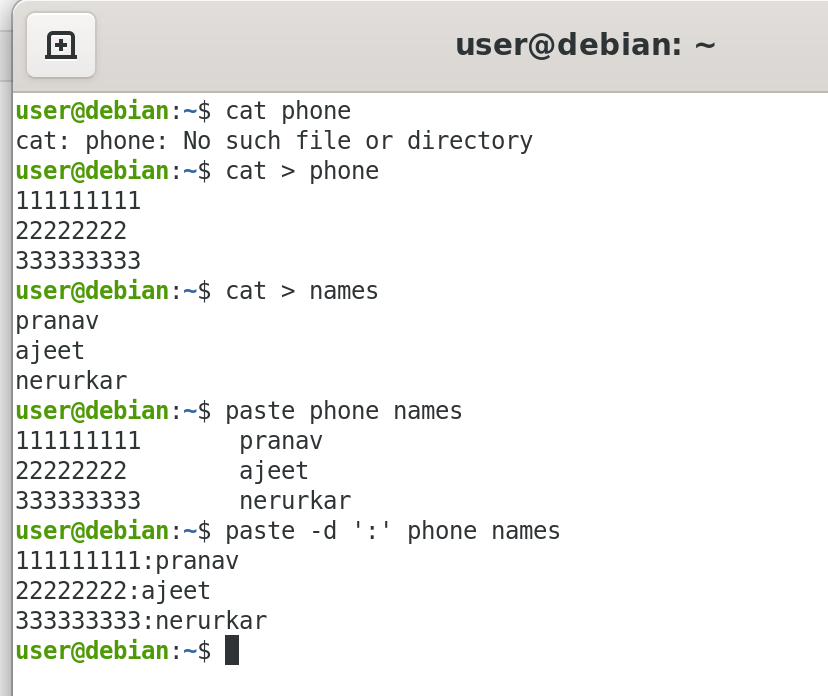

We will apply split to an American-English dictionary file of over 99,000 lines:
$ wc -l american-english
99171 american-english
where we have used wc (word count, soon to be discussed) to report on the number of lines in the file. Then, typing:
$ split american-english dictionary
will split the American-English file into 100 equal-sized segments named 'dictionaryxx. The last one will, of course, be somewhat smaller.