Loading/Unloading Kernel Modules
Many facilities in the Linux kernel can either be built-in to the kernel when it is initially loaded, or dynamically added (or removed) later as modules, upon need or demand. Indeed, all but some of the most central kernel components are designed to be modular.
Such modules may or may not be device drivers; for example, they may implement a certain network protocol or filesystem. Even in cases where the functionality will virtually always be needed, incorporation of the ability to load and unload as a module facilitates development, as kernel reboots are not required to test changes.
Even with the widespread usage of kernel modules, Linux retains a monolithic kernel architecture, rather than a microkernel one. This is because once a module is loaded, it becomes a fully functional part of the kernel, with few restrictions. It communicates with all kernel sub-systems primarily through shared resources, such as memory and locks, rather than through message passing as might a microkernel.
Linux is hardly the only operating system to use modules; certainly Solaris does it, as well as does AIX, which terms them kernel extensions. However, Linux uses them in a particularly robust fashion. Module loading and unloading must be done as the root user. If you know the full path name, you can always load the module directly with:
$ sudo /sbin/insmod /module_name.ko
A kernel module always has a file extension of .ko, as in e1000e.ko, ext4.ko, or nouveau.ko. Many modules can be loaded while specifying parameter values, such as in:
$ sudo /sbin/insmod /module_name.ko irq=12 debug=3
While the module is loaded, you can always see its status with the lsmod command:
$ lsmod
Module Size Used by
coretemp 16384 0
e1000e 237568 0
ptp 20480 1 e1000e
pps_core 20480 1 ptp
Direct removal can always be done with:
$ sudo /sbin/rmmod module_name
Note that it is not necessary to supply the full path name or the .ko extension when removing a module.
In most circumstances, the insmod and rmmod commands are not usually used to load/unload modules, but rather the modprobe command is, as in:
$ sudo /sbin/modprobe module_name
$ sudo /sbin/modprobe -r module_name
with the second form being used for removal. For modprobe to work, the modules must be installed in the proper location, generally under /lib/modules/$(uname -r) where $(uname -r) gives the current kernel version, such as 4.18.3.
You can also passparameters to modprobe in the exact same fashion as you do with insmod, as in:
$ sudo /sbin/modprobe module_name.ko irq=12 debug=3
There are some important things to keep in mind when loading and unloading modules: It is impossible to unload a module that is being used by another module, which can be seen from the lsmod listing.
It is impossible to unload a module that is being used by one or more processes, which can also be seen from the lsmod listing. However, there are modules which do not always keep track of this reference count, such as network device driver modules, as it would make it too difficult to temporarily replace a module without shutting down and restarting much of the whole network stack.
When a module is loaded with modprobe, the system will automatically load any other modules that are required to be loaded first.
When a module is unloaded with modprobe -r, the system will automatically unload any other modules being used by the module, if they are not being simultaneously used by any other loaded modules.
Files in the /etc/modprobe.d directory control some parameters that come into play when loading with modprobe. These parameters include module name aliases and automatically supplied options. This directory also contains information about blacklisted modules, which should never be located and loaded.
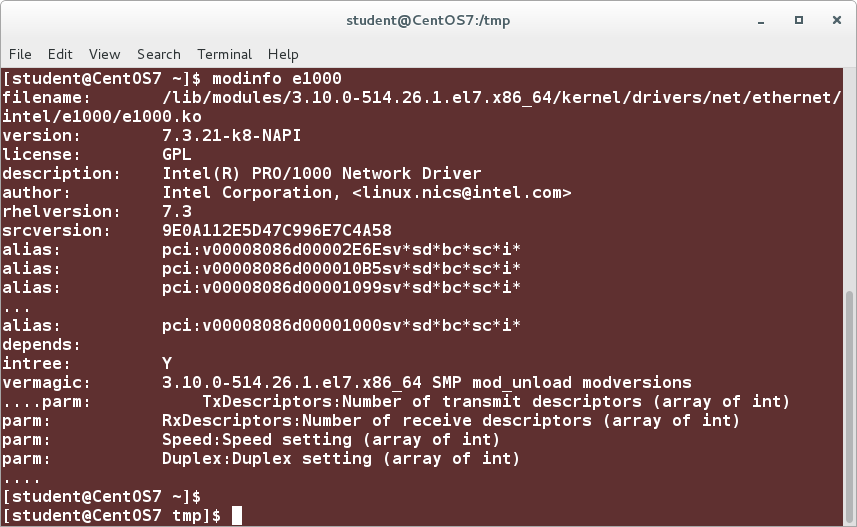
The modinfo command can be used to find out information about kernel modules, whether they are loaded or not, as in:
$ /sbin/modinfo my_module
$ /sbin/modinfo /my_module.ko
An example can be seen in the screenshot below.
Device Management
There are three main types of devices which will probably be connected to your system, character, block and network.
Character devices are sequential streams; they take byte streams of data, they mainly implement open, close, read, and write functions. It could be a serial port, a parallel port, a printer, for instance, sound cards, et cetera.
Block devices are what we usually think of as storage devices, and they only take data in block-size multiples.
I/O operations are generally cached and there may be some delay before they're actually accomplished, we reference the disk, and so there are things like CD-ROMs, hard disks, et cetera.
Network devices are different. They transfer actually packets of data, not blocks or streams. So, they're quite different. Even though these packets of data may go out in the stream and be reassembled into blocks, etcetera, but they are individual packets.
Internally, there's a so-called socket interface, and you have reception and transmission functions, instead of read and write functions, and they're known by name, such as eth0, perhaps, for the first Ethernet card, and wlan0 for the first wireless card.
There are other types of devices, not really other types of devices, but other ways to classify devices.
For instance, USB devices, where many different types of devices share a lot of common protocols and methods, as well as for SCSI or small computers systems interconnect.
Besides the actual device driver for the device itself, you have to write a driver that works for the controller hardware, which may run many devices and types of devices.
There's also something known as the user-space driver, which is not a component of the Linux kernel, would work completely in user-space. For example, Linux printer drivers are always done this way.
Character and block devices have something known as a device node, which is how the system interfaces with them by doing input or output operations than device nodes.
So, youmake these device nodes with the "mknod" command from the command line, and it's pretty straightforward. You give it a name for the device, and you say what type of device it is, and you give what's known as the major and the minor number.
The major number distinguishes the type of device and the minor number is either the instance of that device or the way it's being used.
Managing System Services
Every operating system has services which are usually started on system initialization and often remain running until shutdown. Such services may be started, stopped, or restarted at any time, generally requiring root privilege.
All relatively new Linux distributions have adopted the systemd method, which does most of the work with the systemctl utility.
Most older distributions, such as RHEL 6, use the service and chkconfig utilities. While older Debian-based systems use *rc-* programs, they also have versions of service and/or chkconfig available for install.
Generally speaking, systemd-based systems maintain backwards compatibility wrappers so one can use the older commands.
For this reason, we will only discuss in detail the systemd methods.
For an excellent summary of how to go from SysVinit to systemd, see the SysVinit to systemd Cheatsheet.
With systemd, all service management is done with the systemctl utility. Its basic syntax is:
$ systemctl [options] command [name]
We will provide some examples next.
To show the status of everything systemd controls, do:
$ systemctl
Show all available services:
$ systemctl list-units -t service --all
Show only active services:
$ systemctl list-units -t service
To start (activate) one or more units:
$ sudo systemctl start foo
$ sudo systemctl start foo.service
$ sudo systemctl start /path/to/foo.service
where a unit can be a service or a socket.
To stop (deactivate):
$ sudo systemctl stop foo.service
These commands are equivalent to sudo service foo start|stop .
Enable/disable a service:
$ sudo systemctl enable sshd.service
$ sudo systemctl disable sshd.service
This is the equivalent of chkconfig on|off and does not actually start the service.
Note that some systemctl commands in the above examples can be run as non-root user, others require running as root or with sudo. Furthermore, in most cases, you can omit the .service from the service name.
Using stress (Lab)
From time to time, it will be useful to us to stress the system by making the CPU labor, wasting memory, or kicking up I/O activity.
The appropriately named stress utility is a C language program written by Amos Waterland at the University of Oklahoma under the GPL v2.
It is designed to place a configurable amount of stress by generating various kind of workloads on any kind of POSIX system.
A newer enhanced version of stress (called stress-ng) is also available and has an almost infinite number of options, including over 105 stress tests.
All major distributions now have both of these programs in their repositories, so you should be able to do one of the following:
$ sudo yum install stress stress-ng
$ sudo dnf install stress stress-ng
$ sudo apt-get install stress stress-ng
$ sudo zypper install stress stress-ng
stress-ng is backwards compatible with stress, so wherever we use stress from here on, you can substitute stress-ng:
$ stress-ng --help
for a quick list of options.
As an example, the command:
$ stress -c 8 -i 4 -m 6 -t 20s
will:
Fork off 8 CPU-intensive processes, each spinning on an sqrt() calculation.
Fork off 4 I/O-intensive processes, each spinning on sync().
Fork off 6 memory-intensive processes, each spinning on malloc(), allocating 256 MB by default. The size can be changed as in --vm-bytes 128M.
Run the stress test for 20 seconds.
After installing stress, start up your system’s graphical system monitor, which you can find on your application menu, or run from the command line, which is probably gnome-system-monitor or ksysguard. Later, we will consider these in some detail.
Now, begin to put stress on the system. The exact numbers you use will depend on your system’s resources, such as the number of CPUs and RAM size.
For example, doing:
$ stress -m 4 -t 20s
which puts only a memory stressor on the system, is likely to take up all your CPU time.
Play with combinations of the switches and see how they impact each other. In succeeding sessions, we will be able to use the stress program to simulate various high load conditions.
Download the folder Then run the following commands using terminal
#/* **************** Coursera: lab_stress.sh **************** */
#/*
# * The code herein is: Copyright the Linux Foundation, 2018
# *
# * This Copyright is retained for the purpose of protecting free
# * redistribution of source.
# *
# * URL: http://training.linuxfoundation.org
# * email: [email protected]
# *
# * This code is distributed under Version 2 of the GNU General Public
# * License, which you should have received with the source.
# *
# */
set -x
tar zxvf stress-1.0.4.tar.gz
cd stress-1.0.4
./configure
make
sudo make install